# 計算方法ロジック説明
イベント分析の分析指標、リテンション分析と分布分析の同時表示指標を設定する際に、分析内容に応じて適切な計算方法を選択する必要がありますが、本章ではいくつかの方法のロジックについてご説明します。
# プリセット計算方法
- 合計回数:イベントがトリガーされた回数
- ユニークユーザー:イベントをトリガーしたユニークユーザーの数
- 1人あたりの回数:合計回数 / イベントをトリガーしたユーザーの数、イベントをトリガーした各ユーザーが平均のイベントトリガー回数
# 数値型プロパティ
| 計算方法 | ロジック |
|---|---|
| 平均値 | プロパティ値の合計/プロパティ値の数 |
| 一人当たりの値 | プロパティ値の合計/トリガーユーザー数、各トリガーユーザーのプロパティ値の平均合計 |
| 中央値 | プロパティ値を大きい方から小さい方に並べ替え、中央のプロパティ値を並ぶ。プロパティ値の数が偶数の場合、中央値は 2つの中央値の平均となる。 |
平均はデータの平均的なパフォーマンスを反映していますが、他よりも大幅に高いまたは低いプロパティ値がある場合、中央値は平均よりも全体的な状況をよりよく把握できます。
例:4人のユーザーが合計7つの課金イベントをトリガーするとします。
| ユーザー | 毎回の課金金額 |
|---|---|
| A | 6、648 |
| B | 30、30、30 |
| C | 128 |
| D | 6 |
| 計算方法 | ロジック |
|---|---|
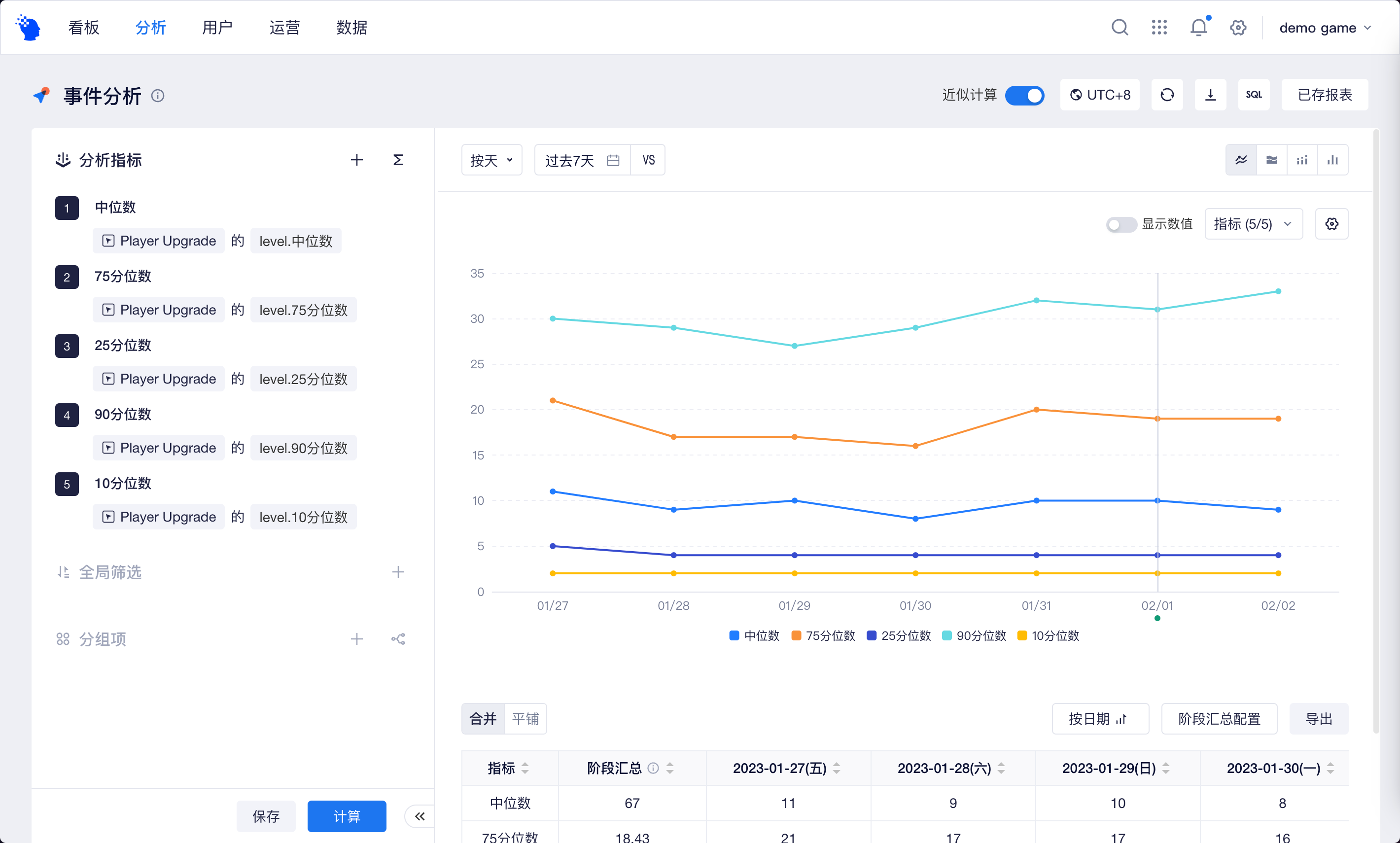
| Nパーセンタイル | プロパティ値を大きい方から小さい方に並べ替えます。プロパティ値は Nパーセンタイル、中央値は50パーセンタイルです。 |
中央値以外でデータの分布をより適切に測定するためにNパーセンタイルがよく使用されます。
例えばコアアイテム・資源のNパーセンタイルの変化を観察し、新しいアイテム・資源を作るかどうかを判断します。
| 計算方法 | ロジック |
|---|---|
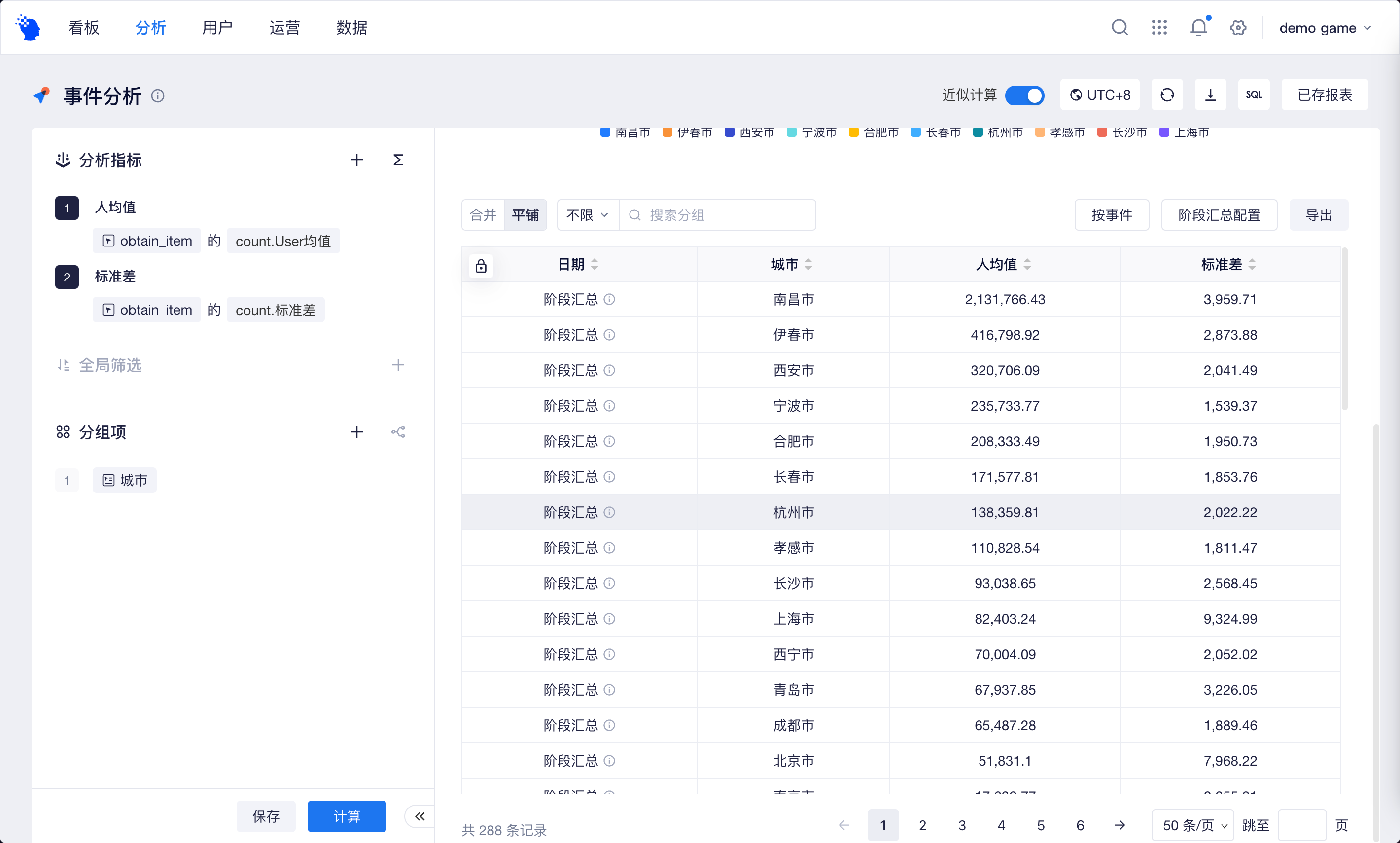
| 分散 | 平均値を統計し、次に各プロパティ値と平均の差の二乗を計算し平均を取る |
| 標準偏差 | 分散の平方根 |
分散と標準偏差は、データの変動を測定するために使用できます。実験群と対照群の1人あたりの平均課金額が類似しており、標準偏差が対照群よりも有意に高いと仮定すると、実験群の指標データは大額課金によってより影響を受けることが示されます。
# リスト型プロパティ
| 計算方法 | ロジック |
|---|---|
| リスト重複排除カウント | リスト全体を取り、ユニークのリストがいくつあるか統計する |
| 集合重複排除カウント | 各リスト内のエレメントを重複排除し並び替えて集合を取り、重複しない集合数を統計する |
| エレメント重複排除カウント | すべてのリストのすべてのエレメントを取り出し、ユニークのエレメントがいくつあるかを統計する |
ゲームでは戦闘中の複数のヒーローIDがリスト属性で記録されることがよくあります。どれぐらいのヒーローが戦闘に参加したかを分析したい場合は、統計に「エレメント重複排除カウント」を使用できます;「リスト重複排除カウント」または「集合重複排除カウント」を使用して、ユニークな出場組み合わせがいくつあるかを分析できます。後者はリスト内のヒーローの順序は区別されません。
4つのリスト属性があるとする:[a,b,c]、[a,b,c,c]、[c,b,a]和[a,b,c,d]:
- リスト重複排除カウント = 4
- 集合重複排除カウント = 2
- エレメント重複排除カウント = 4
# ブール型プロパティ
| 計算方法 | ロジック |
|---|---|
| 真数、偽数 | 値が True/False のイベントの数 |
| 空の数、空ではない数 | 値が null/not null であるイベントの数 |
← ダッシュボード活用事例 グループで比較分析 →