# 分析模型操作项说明
在通过模型进行分析时,您可以对一些操作项进行调整以得到更符合需求的数据结果,本章节会对部分操作项的逻辑进行说明。
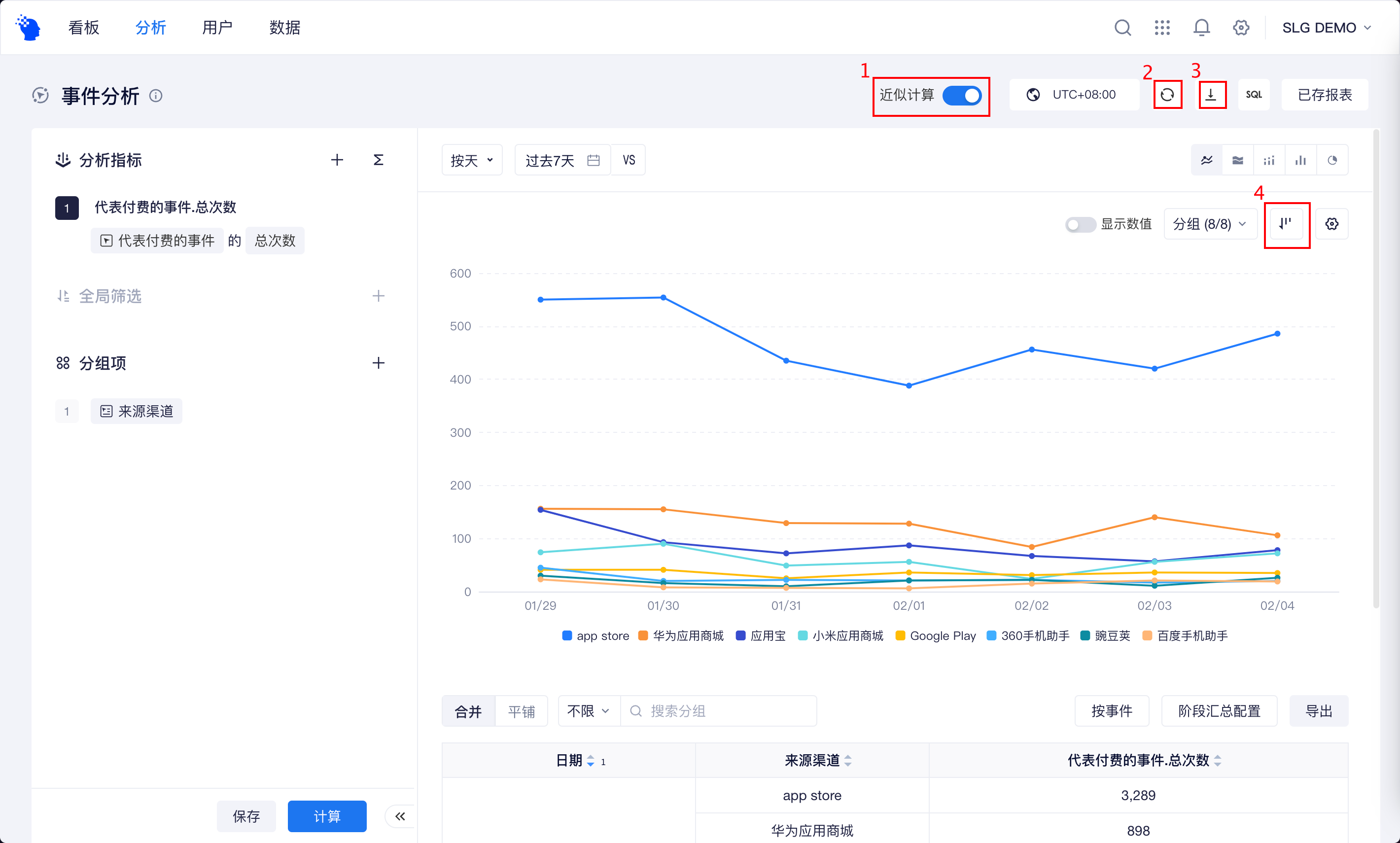
# 近似计算
分析模型在使用到触发用户数、人均次数、人均值、去重数等计算方法时,默认为“精确计算”;由于去重计算会消耗大量计算资源,您可以开启“近似计算”(图例1)以提升查询效率,TE将采用approx_distinct函数代替distinct,极大减少资源开销。和“精确计算”相比,“近似计算”会有约4‰的误差。
# 手动刷新
为了减少资源开销,分析模型在计算后会默认将得到的数据结果缓存10分钟,如果您的查询条件没有发生改变,10分钟内点击“计算”按钮会得到相同的数据结果。
当您选择的时间范围包含“今天”时,缓存的数据结果可能不准确,您可以点击“手动刷新”(图例2)以获得最新的数据结果。
# 以页面格式下载全量数据
为提升渲染性能优化看数体验,TE默认展示前1000个分组值的数据结果。
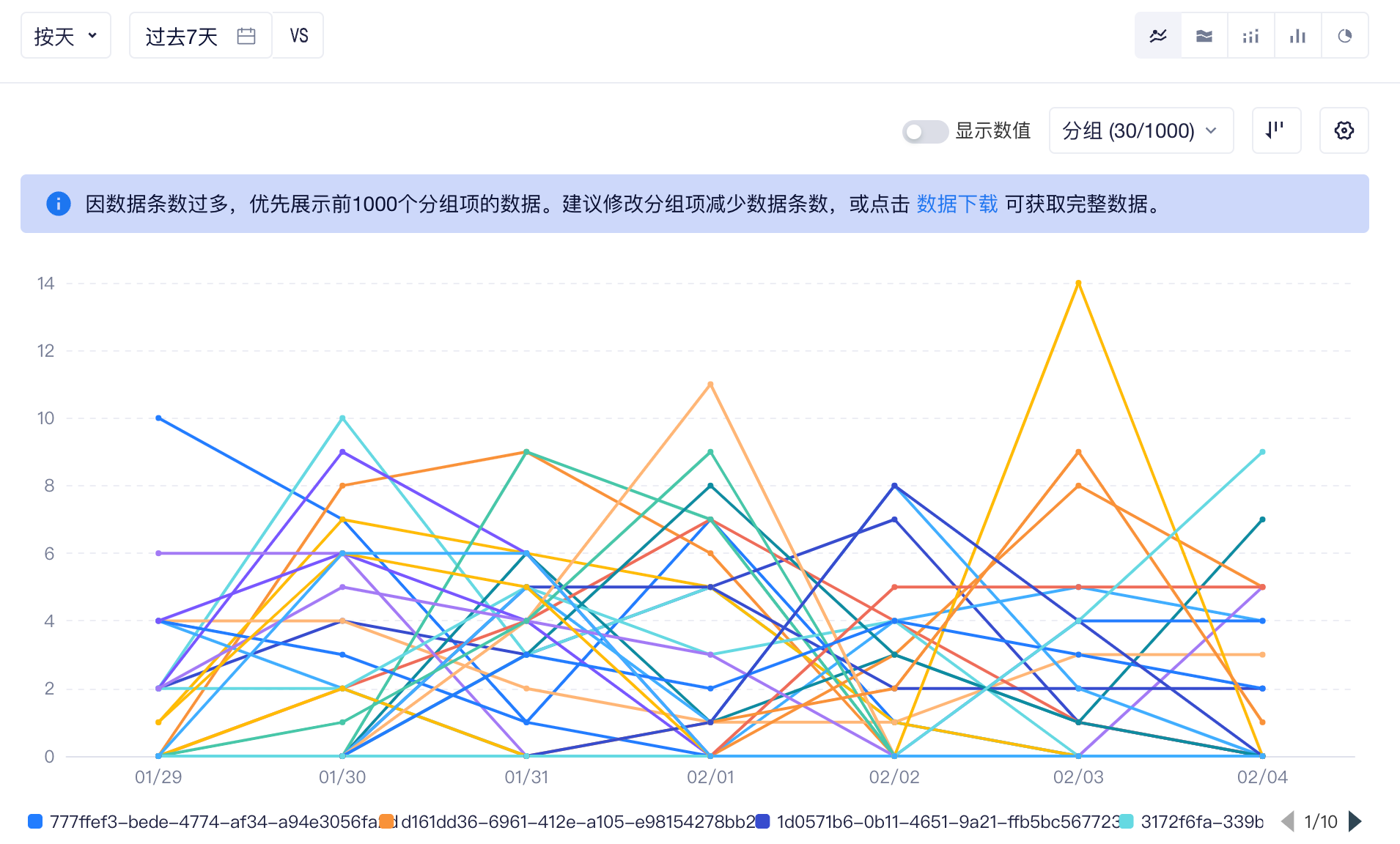
如果分组值超过1000个,您可以在分析模型界面看到提示。此时点击“导出”,将只会基于界面上展示的数据导出CSV文件,即前1000个分组项的数据结果。如果您希望分析全量数据,可以使用“以页面格式下载全量数据”(图例3),从而基于完整的数据下载CSV文件。
# 分组排序
如果您有设置分组项或者事件拆分,可以修改图表中各分组值的排序方式(图例4)。分组排序仅针对图表生效,如您希望调整表格中的排序方式,可以点击表格的表头排序。
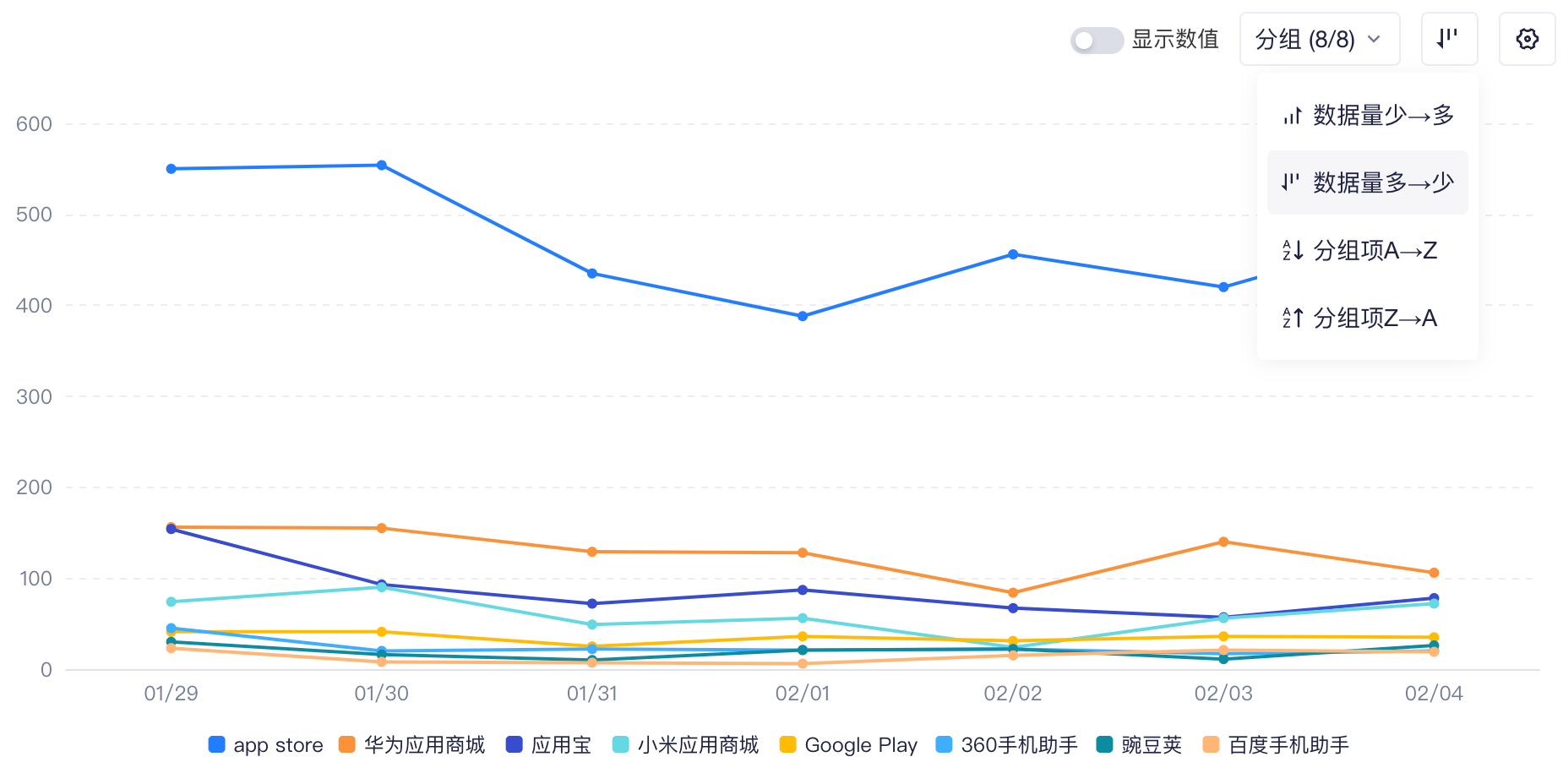
- 数据量少→多:按第一个指标的数据升序
- 数据量多→少:按第一个指标的数据降序,表现好的分组值排在前面
- 分组项A→Z:按名称的字典序(字母序)升序,如果是数值则从小到大排序
- 分组项Z→A:按名称的字典序降序,如果是数值则从大到小排序
注意
为提升渲染性能、优化看数体验,TE默认展示前1000个分组值的数据结果,分组排序方式仅针对这批分组值生效而不是全部的分组值。如果您希望在界面上展示更多分组值,请联系您的客户成功经理调整展示上限。