# 분석 모델의 조작 항목 설명
모델로 분석할 경우 화면 상의 조작 항목을 조정하여, 더욱 필요에 맞는 데이터 결과를 얻을 수 있습니다. 이 장에서는 그 조작 항목의 로직에 대해 설명합니다.
# 근사계산 (그림 1)
분석 모델이 유니크 수, 1인당 평균 회수, 1인당 평균 값, 중복 제외 수 등의 계산 방법을 사용하는 경우, 기본적으로 '정밀 계산'으로 진행됩니다. 중복 제외의 계산량이 많기 때문에, '근사계산' (그림 1)을 활성화하여 쿼리의 효율을 향상시킬 수 있습니다. TE는 distinct 대신 approx_distinct 함수를 사용하여, 리소스의 오버헤드를 크게 줄입니다. '정밀 계산'과 비교하면 '근사계산'에서는 약 4‰의 오차가 발생합니다.
# 수동 업데이트(그림 2)
리소스의 오버헤드를 줄이기 위해, 분석 모델은 기본적으로 계산 후에 얻은 데이터 결과를 10분 동안 캐시합니다. 쿼리 조건이 변경되지 않은 경우, 10분 이내에 [계산] 버튼을 클릭하면, 같은 데이터 결과를 얻을 수 있습니다.
선택한 시간 범위에 '오늘'이 포함되어 있는 경우, 캐시된 데이터의 결과가 부정확해질 가능성이 있습니다. '수동 업데이트'(그림 2)를 클릭하여, 최신의 데이터 결과를 얻을 수 있습니다.
# 페이지 상에서 표시되는 형식으로 전량 데이터를 다운로드(그림 3)
렌더링 성능을 향상시키고, 데이터 조회 경험을 최적화하기 위해, TE는 기본적으로 처음 1000개의 그룹 값의 데이터 결과를 표시합니다.
그룹 값이 1000을 초과하는 경우, 분석 모델 페이지에 프롬프트가 표시됩니다. 이 시점에서 '내보내기'를 클릭하면, 페이지에 표시된 데이터의 처음 1000개의 그룹 항목의 데이터 결과에 기초하여, CSV 파일이 내보내집니다. 전체 데이터를 분석하고 싶은 경우, '전체 데이터를 페이지 표시 형식으로 다운로드'(그림 3)를 이용하여, 전체 데이터를 기반으로 CSV 파일을 다운로드할 수 있습니다.
# 그룹 정렬(그림 4)
그룹 항목이나 이벤트 분할을 설정한 경우, 차트 내의 각 그룹 값의 정렬 방법을 변경할 수 있습니다(그림 4). 그룹화 정렬은 차트에만 적용됩니다. 테이블의 정렬 방법을 조정하려면 테이블 헤더를 클릭하여 정렬할 수 있습니다.
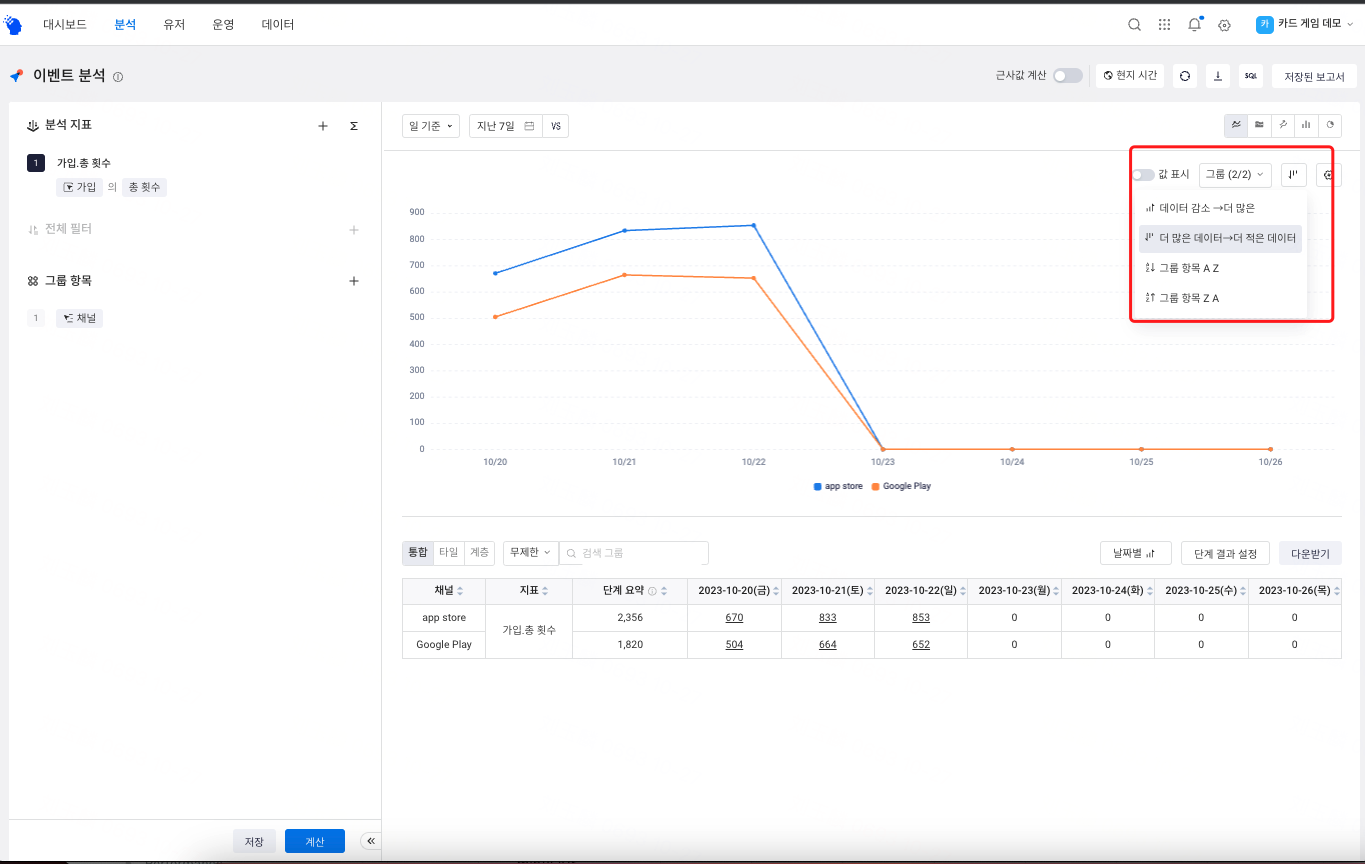
- 데이터가 적음 → 많음: 첫 번째 지표의 데이터 오름차순
- 데이터가 많음 → 적음: 첫 번째 지표의 데이터 내림차순으로, 성능이 좋은 그룹 값이 먼저 순위가 매겨집니다.
- A→Z: 이름의 알파벳 순으로 오름차순, 숫자의 경우 작은 것부터 큰 것으로 정렬
- Z→A: 이름의 알파벳 순으로 내림차순, 숫자의 경우 큰 것부터 작은 것으로 정렬
DANGER
렌더링 성능을 향상시키고 데이터 브라우징 경험을 최적화하기 위해, TE는 기본적으로 처음 1000개의 그룹 값의 데이터 결과를 표시하며, 그룹화 정렬 방법은 모든 그룹 값이 아닌 이 그룹 값의 배치에만 적용됩니다. 페이지에 더 많은 그룹 값을 표시하려면 저희 스태프에게 연락하십시오.