# 用户标签
# 一、用户标签的意义
用户标签是具有某一系列特征的人群集合,标签值是“一组相似人群”的集合,通过标签和标签值可以方便将人群结构化。
如:用户标签为“付费用户”,标签下有标签值分别为“大 R”、“中 R”、“小 R” 的 3 种群体。
通过某种创建方式,将相似特征用户按特征值汇总后组成标签,方便在各种模型中进行细分分析;同时,可以在看板内添加标签,日常数据监控更加方便
- 提供多种创建方式,适合更深度的用户群体下钻分析
- 同一维度下的多个相似人群组成标签,每种人群作为一个标签值,实现关联人群间的连接
- 标签可以创建不同日期的历史版本(备份),可以看不同标签值用户数随日期变化的情况
- 标签可以切换不同的分析主体,对应不同的计算逻辑和分析场景
# 二、用户标签的位置和适用角色
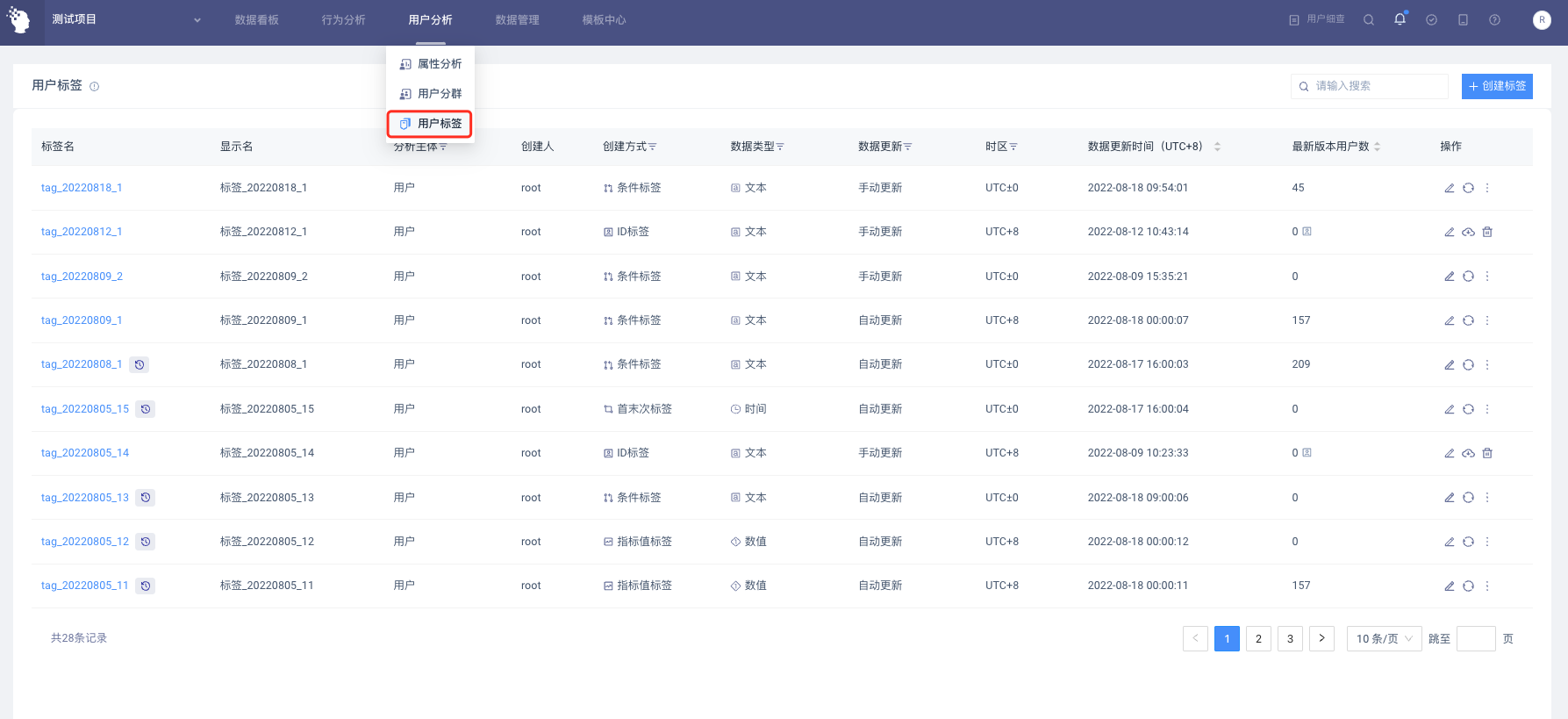
具有用户标签查看权限的用户从“用户分析-用户标签”进入,设置用户标签
| 公司超管 | 管理员 | 分析师 | 普通成员 | |
|---|---|---|---|---|
| 查看标签列表 | ● | ● | ● | ○ |
| 新增、编辑、删除自建非SQL标签 | ● | ● | △ | ○ |
| 新增、编辑、删除自建SQL标签 | ● | ● | △ | ○ |
| 编辑、删除其他人的标签 | ● | ○ | ○ | ○ |
权限说明:
● 角色必有
▲ 角色默认有,可以没有
△ 角色默认没有,可以有
○ 角色必没有
# 三、用户标签的页面概览
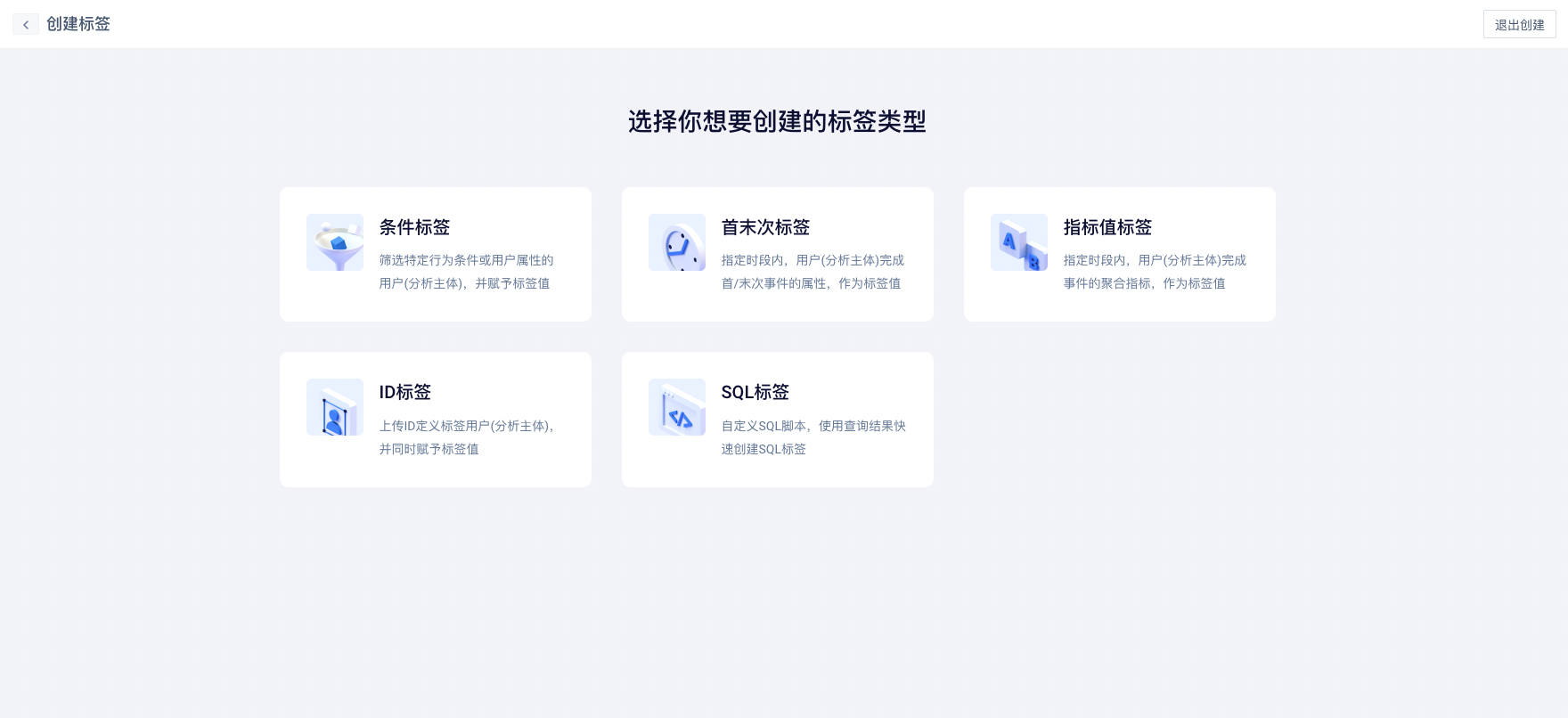
点击“+新建标签”按钮,选择一种标签类型
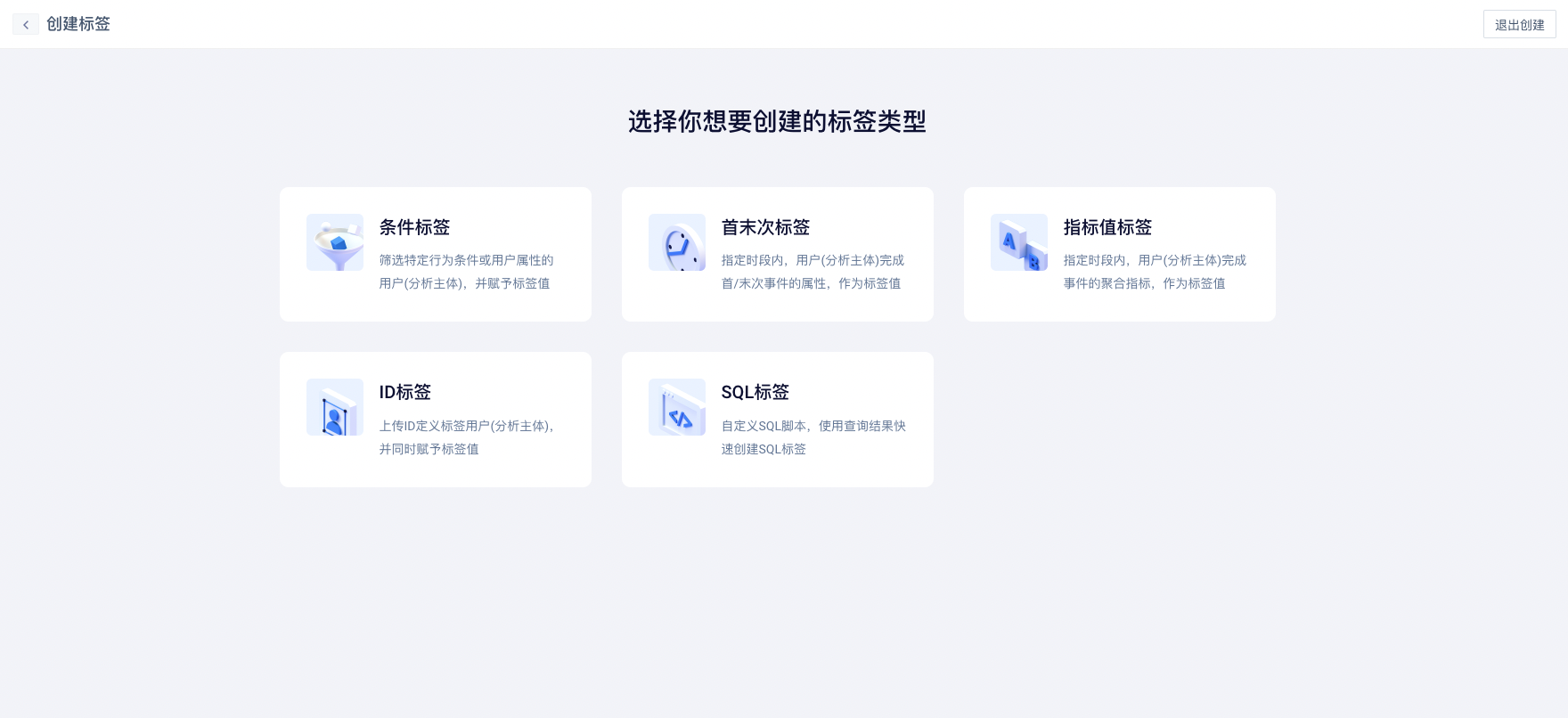
完成整个标签创建流程
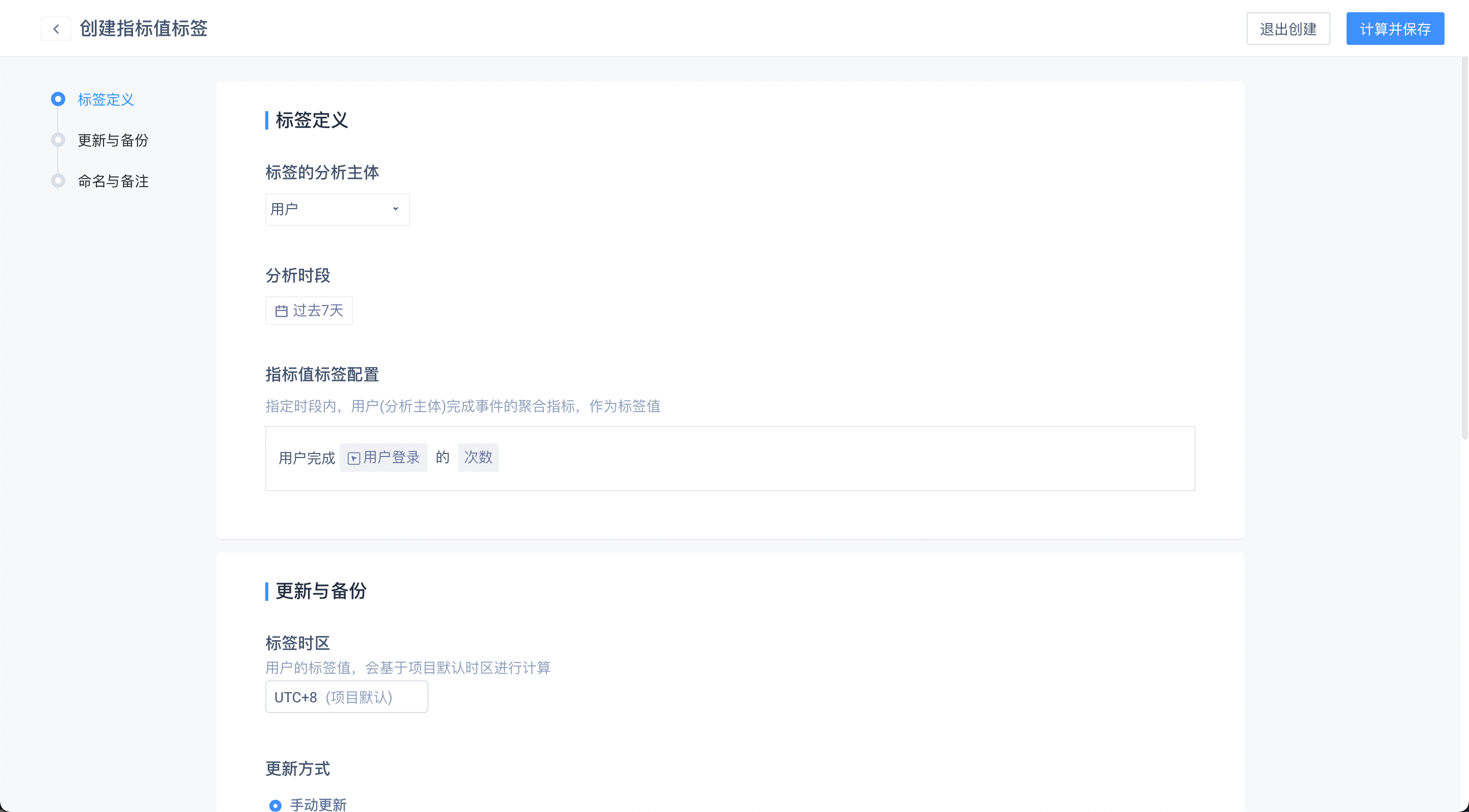
查看不同用户的标签情况
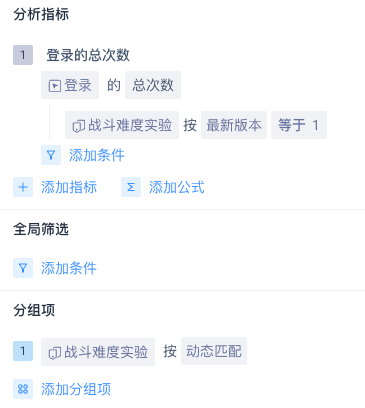
在模型筛选、分组项查看中使用标签
# 四、用户标签的使用场景
# 4.1 用户标签与标签值
用户标签是一组具有“同一维度下,多组相似人群”的集合,标签值是“一组相似人群”的集合。
如:用户标签为“付费用户”,标签下有标签值分别为“大 R”、“中 R”、“小 R”的 3 种群体。
属于某一标签的用户有且只有唯一的标签值,如果某一标签有历史版本则用户在该标签下的每份历史版本(每个日期)内的标签值可能不同
# 4.2 用户标签的创建
新建时,可选择“条件标签”、“ID 标签”、“首末次标签”、“指标值标签”、“SQL标签”五种标签类型之一,选择后进入具体创建配置页面。
# 4.2.1 标签定义
- 对于所有标签,都需要先从已配置的分析主体中选择,默认选择预置分析主体(TE用户ID);标签创建后,分析主体不可修改
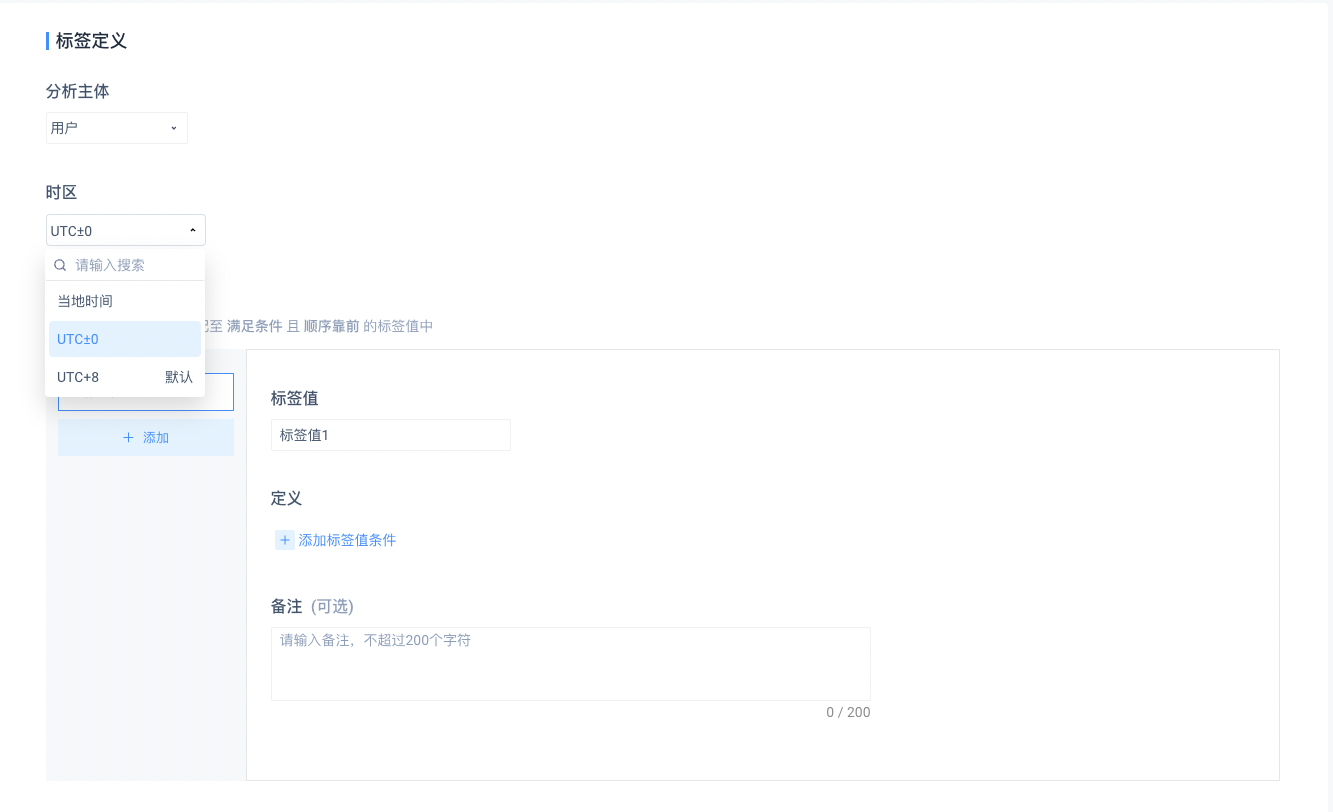
- 标签时区
如果当前项目有开启 项目时区,可在创建标签时选择标签时区,标签时区会影响计算得到的标签值,默认按项目默认时区进行计算,可根据需要进行调整
假设标签逻辑都为“今日”的付费事件.付费金额总和
- 如果标签时区为UTC+8,那么用户在2022-05-10的标签值就是以用户在UTC+8下的 2022-05-10 00:00:00 ~ 2022-05-10 23:59:59 的付费事件进行计算
- 如果标签时区为UTC-8,那么用户在2022-05-10的标签值就是以用户在UTC-8下的 2022-05-10 00:00:00 ~ 2022-05-10 23:59:59 的付费事件进行计算,即UTC+8下的 2022-05-10 16:00:00 ~ 2022-05-11 15:59:59
因此,对于需要按多个展示时区进行分析的场景,可在创建标签时选择所需标签时区,和模型分析时的时区保持一致
# (1) 条件标签
筛选特定行为条件或用户属性的用户,并赋予标签值;用户优先匹配至满足条件且顺序靠前的标签值中。
比如,可以创建“付费用户标签”,再通过自定义条件将用户分为高消费用户、中消费用户、低消费用户。后续可将该标签作为分组项,同时分析三种类型用户。
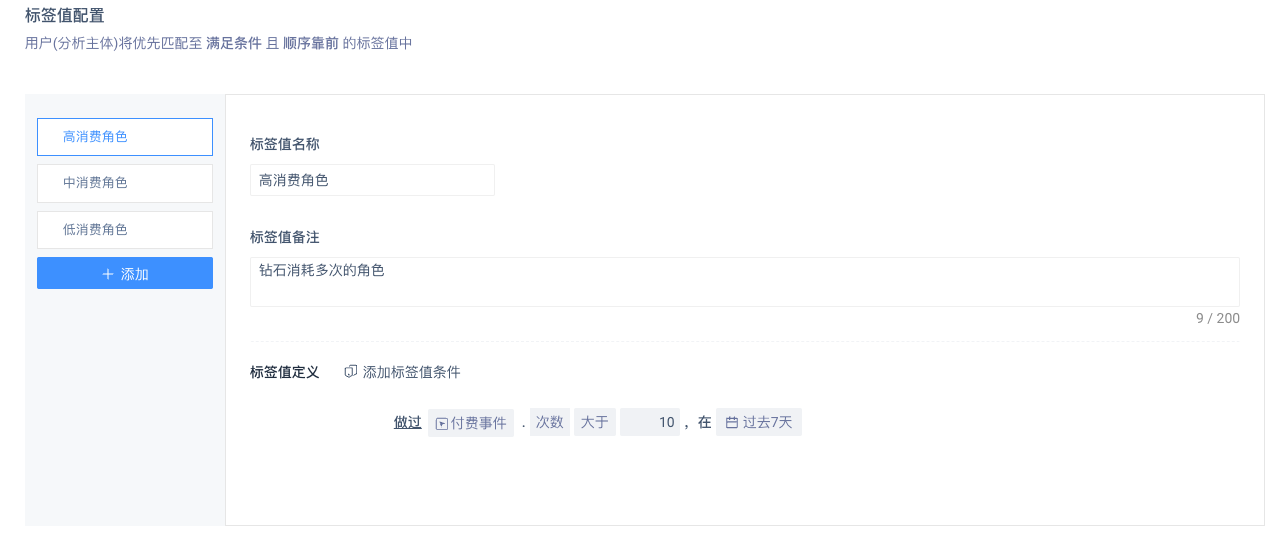
- 自定义条件时,所有用户将按照标签值的先后顺序依次判断组成。即同一用户满足上层标签值后,将不再参与下层标签值筛选
- 所有标签值中的用户共同组成了标签用户
- 新增标签值始终在最后一个标签值后。创建时一个标签最多设置 20 组标签值。达到 20 时,无法新增
- 条件标签的上限为 200 个
注意
如果标签的分析主体来源是事件属性则只能选择「做过某事」条件,不能选择「没做过某事」。同时,事件下拉列表里只有包含该属性的事件。
# (2)首末次标签
指定时段内,用户完成首/末次事件的属性,作为标签值
举例:埋点层面没有记录用户的首次登录时间,但又需要通过首登日期去做分组或筛选条件
可以选取从开服日至今作为分析时段,以首次登录的时间作为用户的标签值。
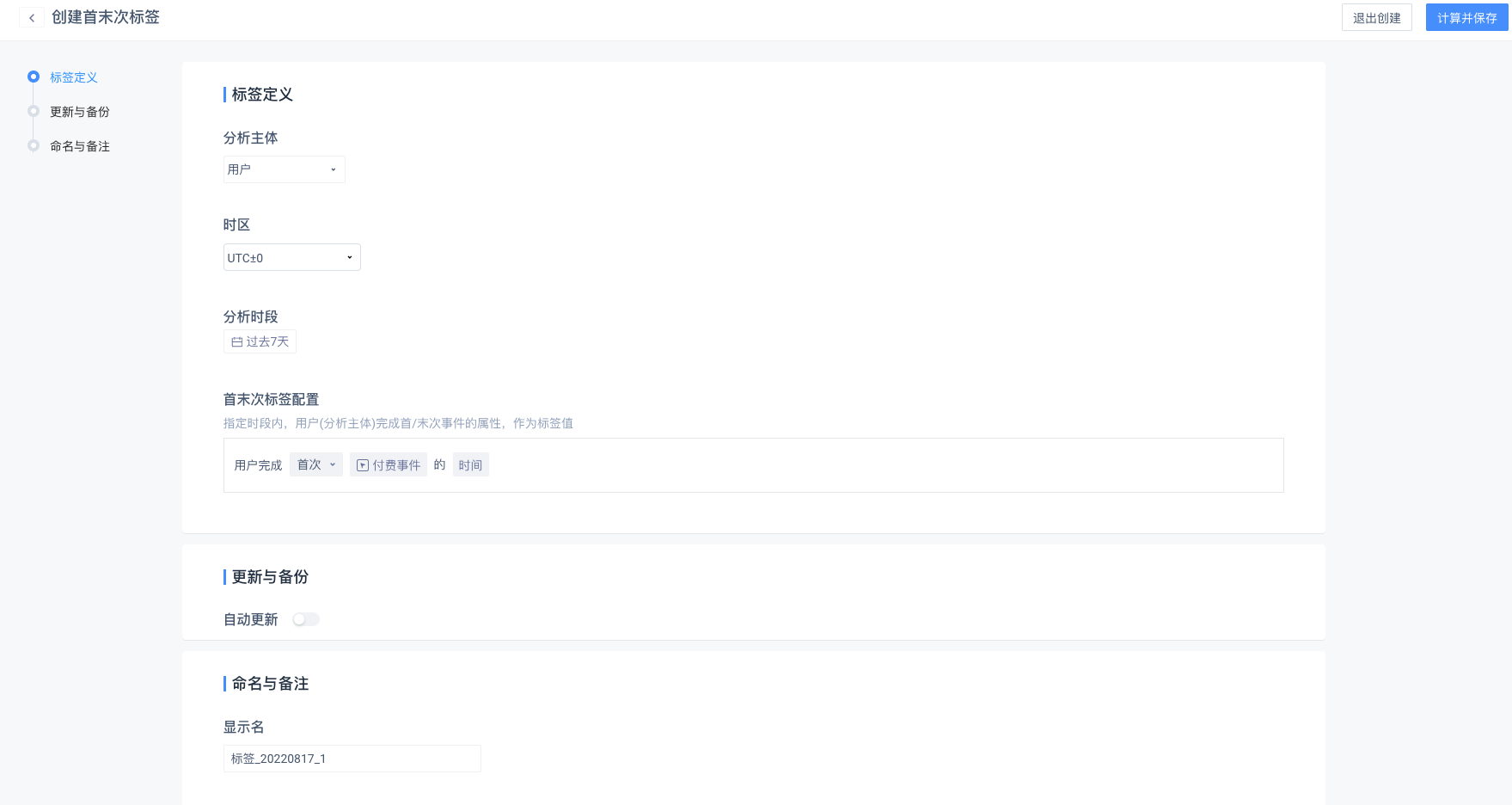
- 分析时段:默认选中动态的「过去 7 天」,可选择动态或静态时间
- 首末次信息:可选择首次或者末次
- 完成事件:可选择任意一个物理事件或虚拟事件,可以筛选事件属性或用户属性
| 事件类型 | 可筛选的事件属性 |
|---|---|
| 物理事件 | 事件属性 |
| 虚拟事件 | 虚拟事件的事件属性(并集) |
选择时间型事件属性作为筛选条件时,会将该属性偏移到所选取的标签时区后再进行计算
- 分析属性(标签值):可选发生时间或事件属性,元属性、虚拟属性、维度表属性都可以进行选择,但不包括对象、对象组、对象组的子属性
- 数据类型将决定标签的数据类型,及使用标签时的关键字。
| 类型 | 属性 | 数据类型 |
|---|---|---|
| 预置指标 | 时间* | 时间 |
| 事件属性指标 | 数值型属性 | 数值 |
| 列表型属性 | 列表 | |
| 布尔型属性 | 布尔 | |
| 时间型属性* | 时间 | |
| 文本型属性 | 文本 |
注意
- 即使有完成事件,当标签值为空时,该用户依然将会被剔除出标签;如果标签的分析主体是事件属性,则事件下拉列表仅可选择包含该事件属性的事件
- 时间或时间类型属性,都以偏移到所选取的标签时区后的值作为标签值
# (3)指标值标签
指定时段内,用户完成事件的聚合指标,作为标签值。
比如,需要记录用户在一段时间内的累计付费数据,通过这个数据为用户分层。
那么可以将这段时间的付费金额总和作为标签值。再通过筛选或分组对用户进行全面分析。
- 创建时的标签条件设置
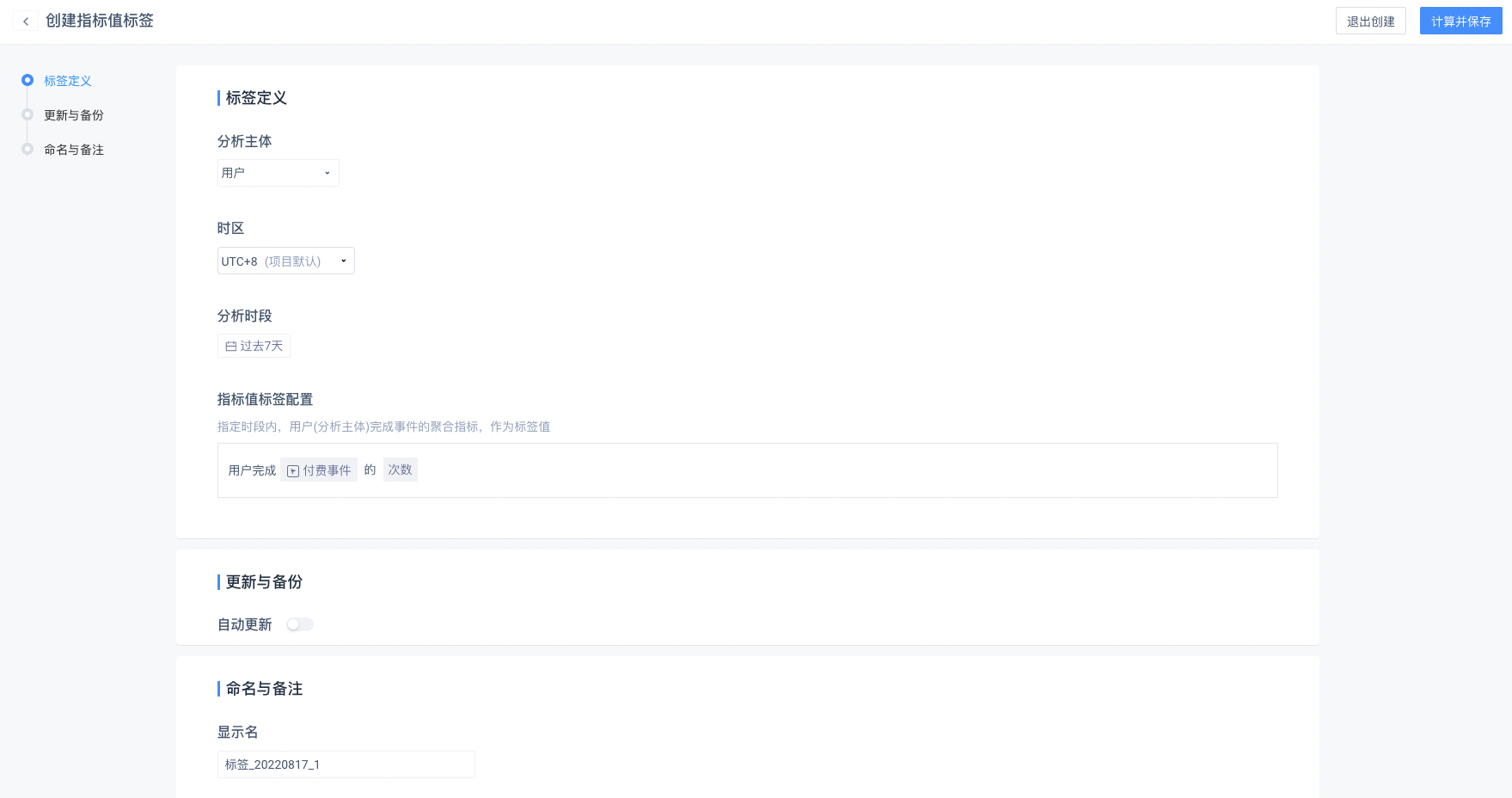
完成事件的用户将属于标签(指标为空的用户被剔除)
分析时段:默认选中动态的「过去 7 天」,可选择动态或静态时间
完成事件:可选择任意一个物理事件或虚拟事件或任意事件
事件的筛选条件:可以筛选事件属性或用户属性
| 事件类型 | 可筛选的事件属性 |
|---|---|
| 物理事件 | 事件属性 |
| 虚拟事件 | 虚拟事件的事件属性(并集) |
选择时间型事件属性作为筛选条件时,会将该属性偏移到项目的默认时区后再进行计算
注意
如果标签的分析主体是事件属性,则事件下拉列表仅可选择包含该事件属性的事件
- 创建条件的标签值确定
通过分析指标确定用户的标签值,即(「事件」+「属性」+「计算方法」)或直接(「事件」+「计算方法」)
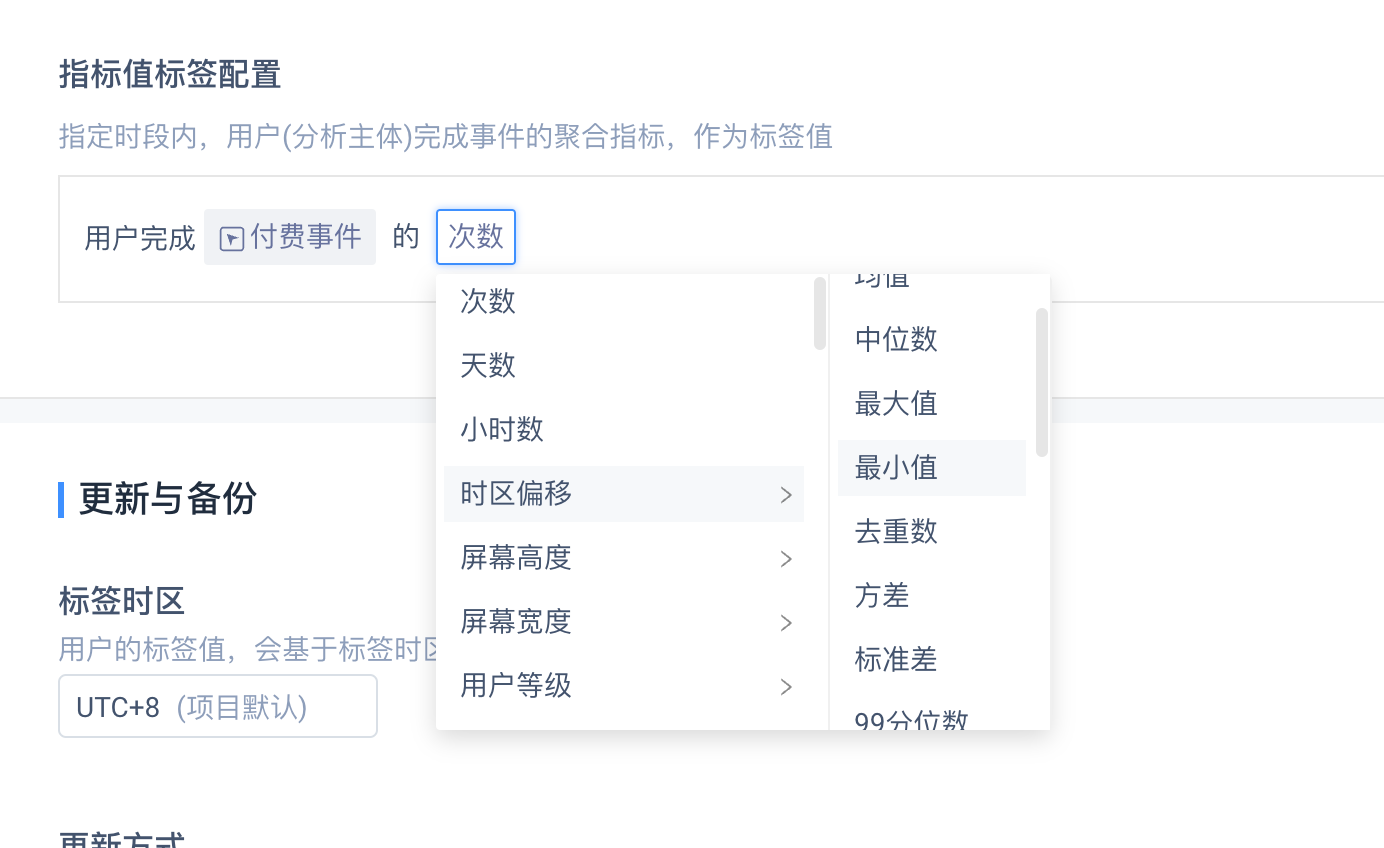
| 属性 | 计算方法 |
|---|---|
| 总次数 | |
| 天数 | |
| 小时数 | |
| 数值型属性 | 总和、均值、中位数、最大值、最小值、去重数、方差、标准差、99分位数、95分位数、90分位数、80分位数、75分位数、70分位数、60分位数、40分位数、30分位数、25分位数、20分位数、10分位数、5分位数 |
| 列表型属性 | 列表去重数、列表元素去重数 |
| 布尔型属性 | 为真数、为假数、为空数、不为空数、去重数 |
| 时间型属性* | 去重数 |
| 文本型属性 | 去重数 |
| 对象型属性 | 去重数 |
| 对象组型属性 | 去重数 |
发生的时间按照标签时区计算
- 编辑公式场景
每一个公式需要编辑显示名,公式中元素通过四则运算组成公式
- 公式计算中各个组成部分的组成规范
| 事件描述 | 指标描述/数据类型 | 分析角度 |
|---|---|---|
| 任意事件 | 次数、天数、小时数 | |
| 元事件 | 次数、天数、小时数 | |
| 元事件 | 事件属性(数值型) | 总和、均值、中位数、最大值、最小值、去重数、方差、标准差、99分位数、95分位数、90分位数、80分位数、75分位数、70分位数、60分位数、40分位数、30分位数、25分位数、20分位数、10分位数、5分位数 |
| 元事件 | 事件属性(列表型) | 列表去重数、元素去重数 |
| 元事件 | 事件属性(布尔型) | 为真数、为假数、为空数、不为空数、去重数 |
| 元事件 | 事件属性(其他类型) | 去重数 |
- 整体筛选条件与细分筛选条件
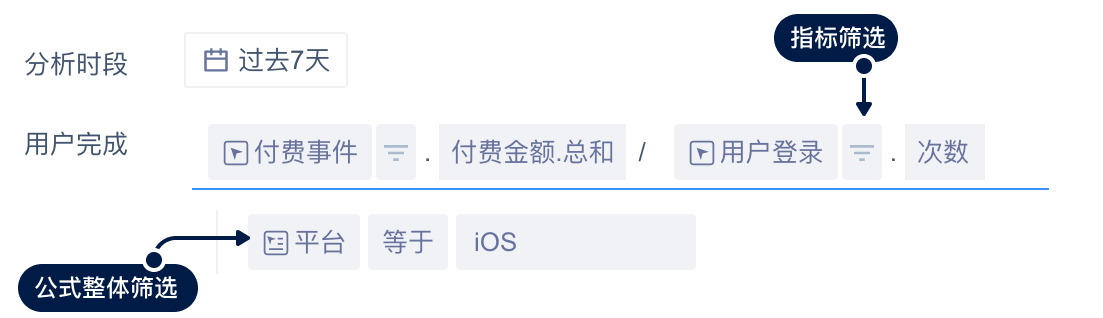
整体筛选条件的可选属性为:公式所有组成部分的公有事件属性或全部用户属性。
属性的筛选逻辑与事件分析一致。
所有用户样本为:满足整体筛选条件,且参与过组成部分中任一事件
- 未参与事件的取值
用户在公式中的未参与事件的分析角度,值记为 0
- 计算结果的异常情况
当使用除法时,可能出现除数为 0 的情况,此时数值无法计算。将定义为“未知”,该名用户将被剔除出标签。
# (4)ID标签
根据模板要求的规范上传 ID 定义标签用户,并同时赋予标签值,可以选择某一用户属性作为判断用户的关联字段
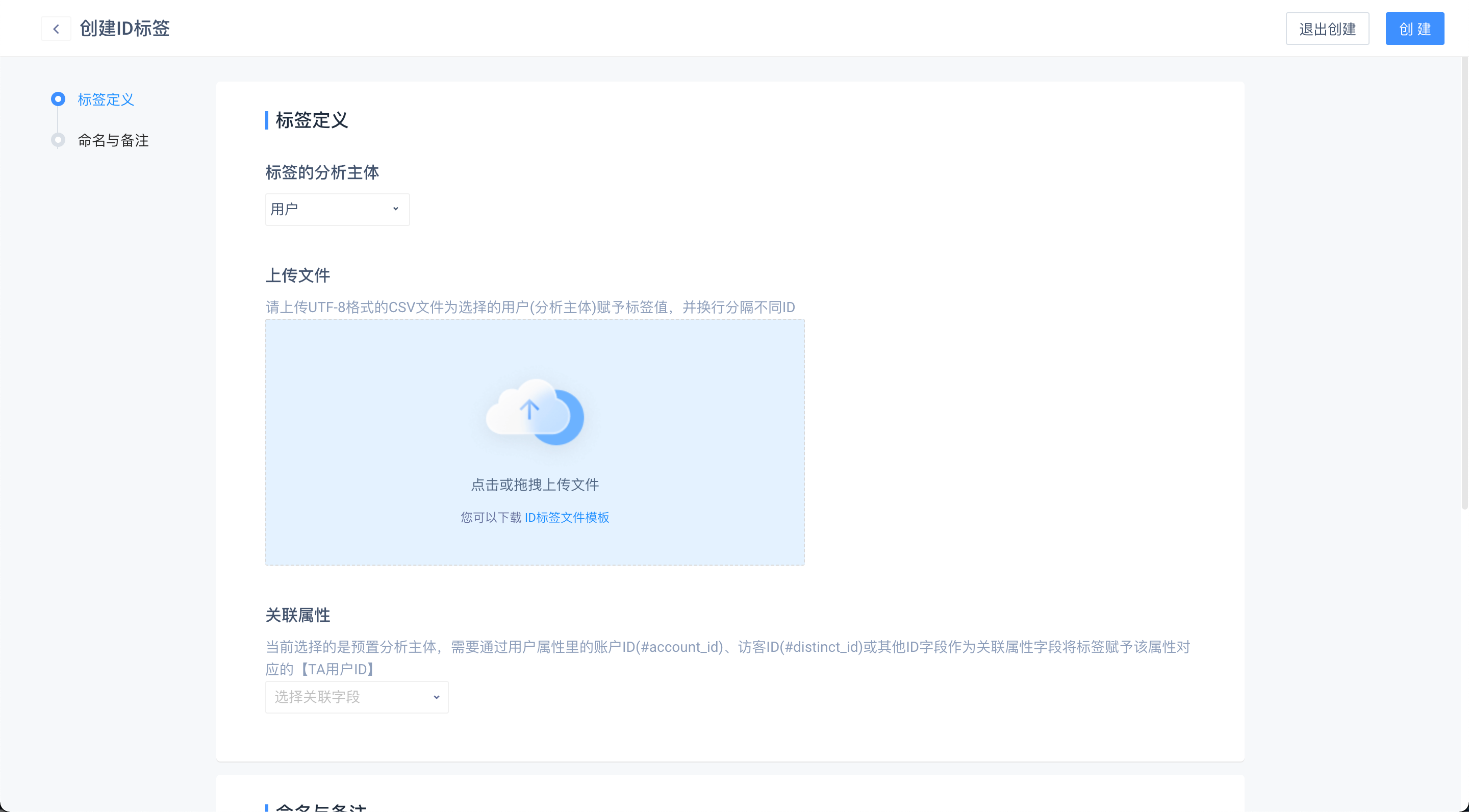
- 第二列值相同的用户将组成同一个标签值
- 如果用户没有标签值,那么该行记录将被抛弃,并在最后一步结果展示时给出提示
- ID 上传创建的标签值,记录的独立标签值个数没有上限
- ID 上传类型的标签,不可设置“更新方式”和“备份方式”
如果分析主体选择的是TE用户ID(#user_id),可以选择某一用户属性作为判断用户的关联字段,上传当时符合选择的用户属性值(第一列)的TE用户ID都将被赋予对应的标签值;
如果选择的是其他分析主体,则会直接将上传文件里的第一列作为分析主体ID,不会校验对应ID在当前已上报的数据内是否存在,在上传前请仔细检查。
举例来说:以区服ID作为分析主体,假设当前游戏只开到第60区服,上传的文件中仍然可以使用61、62……作为分析主体ID。
TIP
每个用户支持创建50个ID上传标签,到达上限后,可通过删除已有标签来继续添加。
一个项目支持创建 200 个标签(ID上传标签除外),可以联系 TE 工作人员上调标签上限数。
# (5)SQL标签
基于SQL规则生成分析主体的标签值
- 创建时的标签条件设置
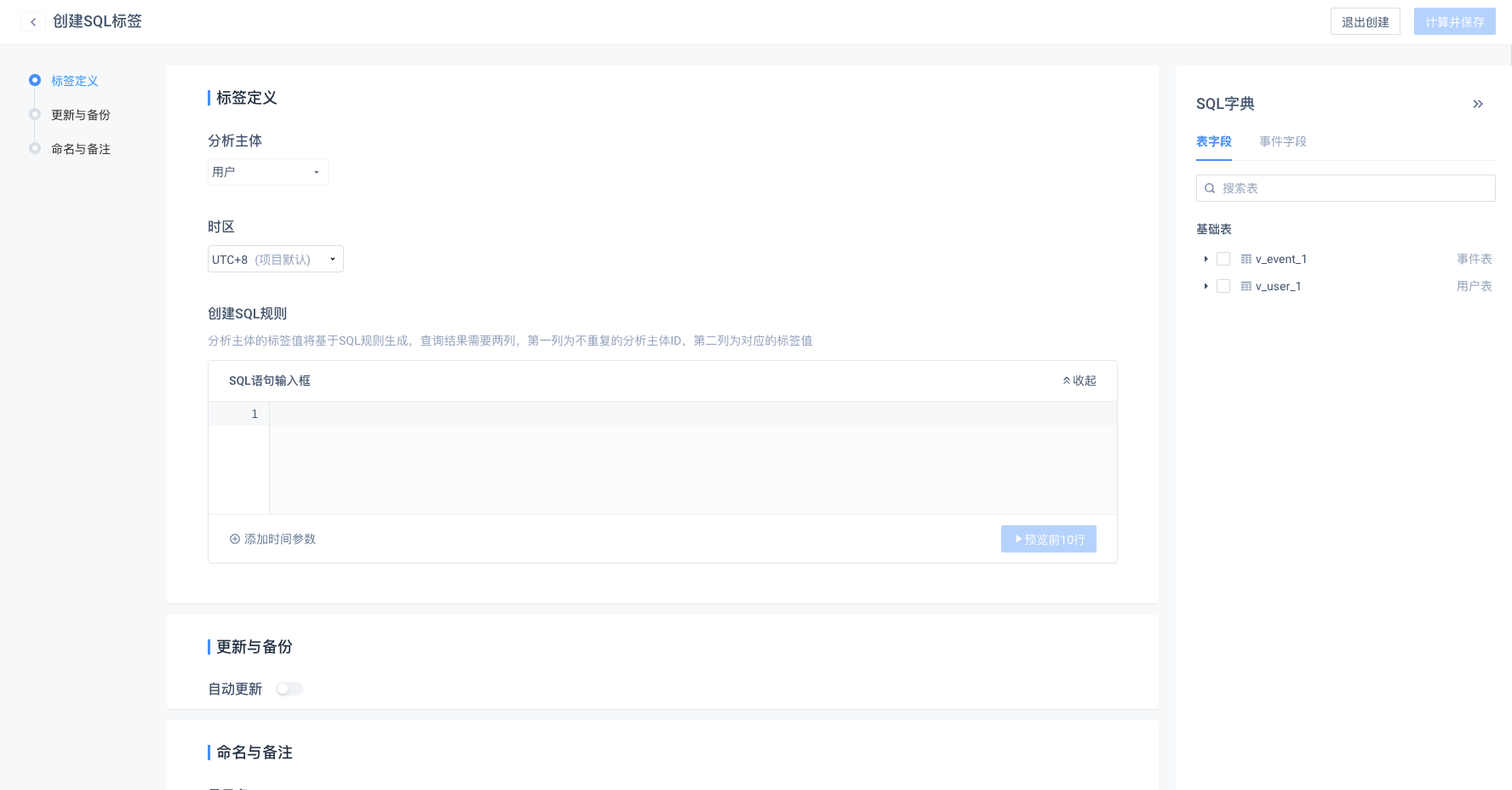
根据需要的逻辑,在SQL语句输入框写下对应的语句,查询结果需要两列,第一列为不重复的分析主体ID,第二列为标签值。
如果语句涉及到事件发生的时间范围,可添加时间参数$Part_date,标签每次更新时都会基于当前的日期确定时间范围
- SQL字典
在创建界面右侧,TE提供了SQL字典,方便查看当前可用的表结构,包括事件表、用户表、维度表、临时表等,并复制相应的字段名或直接解析
注意
- 如果查询结果中,分析主体ID对应多个标签值,会从中随机选择一个作为分析主体ID的标签值,其余数据将被抛弃
- $Part_date会受标签时区影响,事件时间会偏移到标签时区后再判断是否在选择的日期范围内
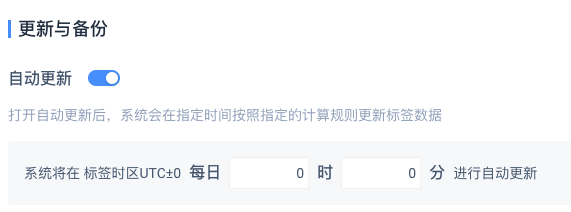
# 4.2.2 更新与备份
- 仅当标签类型不为“ID 上传”时可设置更新方式
- 自动更新开关关闭:该标签默认只可以进行手动更新,标签在创建时会默认计算一次,之后会保持在创建时的计算结果,直到用户主动点击更新计算才会更新计算结果
- 自动更新开关打开:系统将在每日的指定时间,按照用户设置的标签定义的条件进行计算并更新标签数据;该标签同时支持手动更新
- 自动更新时间选择:自动更新的时间,与标签定义里的标签时区强相关,因为选择的更新时间,决定了标签计算条件中所选的时间窗口的完整性;用户在选择自动更新时间时,可以依据标签需要的数据回流完整性来选择标签对应时区的时间
- 手动更新和自动更新的计算基准日期:为保证手动更新和自动更新的计算结果是一致的,计算的基准时期为,更新计算发生时的标签时区日期
- 仅当数据更新方式选择自动更新时可设置备份方式
- 自动备份开关关闭:标签只会保留最后计算的版本,标签自动更新时,之前的历史数据会被清除
- 自动备份开关打开:
- 所有计算过的基准日期都会有一个版本保留,保留的版本为该基准日期最后的计算结果;
- 每天定时更新时,会以当日和前一日作为基准日期计算,计算完后即保留当前计算结果为当日和前一日的版本;刷新前一日的版本,是为了避免所选标签条件窗口期不完整,导致的标签版本数据不完整
注意:自动备份必须在设置「自动更新」的情况下才能生效,如果更新方式选择的是「手动更新」,则无论自动备份是否关闭,都不会进行自动备份

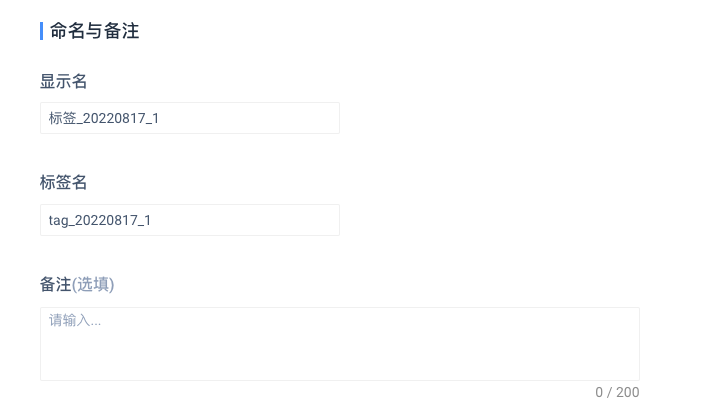
# 4.2.3 命名与备注
- 标签名:标签名须控制在24个字符以内,并使用小写字母开头,可含小写字母、数字、下划线;标签创建后,标签名不可修改
- 显示名:显示名须控制在24个字符以内
- 备注(选填):备注须控制在200个字符以内
# 4.3 历史版本的操作
# 4.3.1 自动备份
如果自动备份开启,则在标签自动更新时,会以当日和前一日作为基准日期计算,计算完后即保留当前计算结果为当日和前一日的版本
# 4.3.2 手动备份
除了自动备份,还可主动对指定日期的历史版本进行计算,主要用于补充缺失版本、重算失败任务或更新标签计算逻辑等场景。
- 重新计算:对于已经计算(备份)过的日期,可以点击“重新计算”按钮对该日期的数据进行计算
- 批量计算:点击“批量计算”按钮,可以选择日期范围内的全部历史版本或者异常版本进行计算
注意:历史版本批量计算可能耗时较长,请选择合适的时间进行
TE系统在手动备份时会尽可能还原当时的数据,如果标签规则中使用了用户属性(包括使用了用户属性的虚拟事件属性或维度表属性),需要在对话框内选择选项:
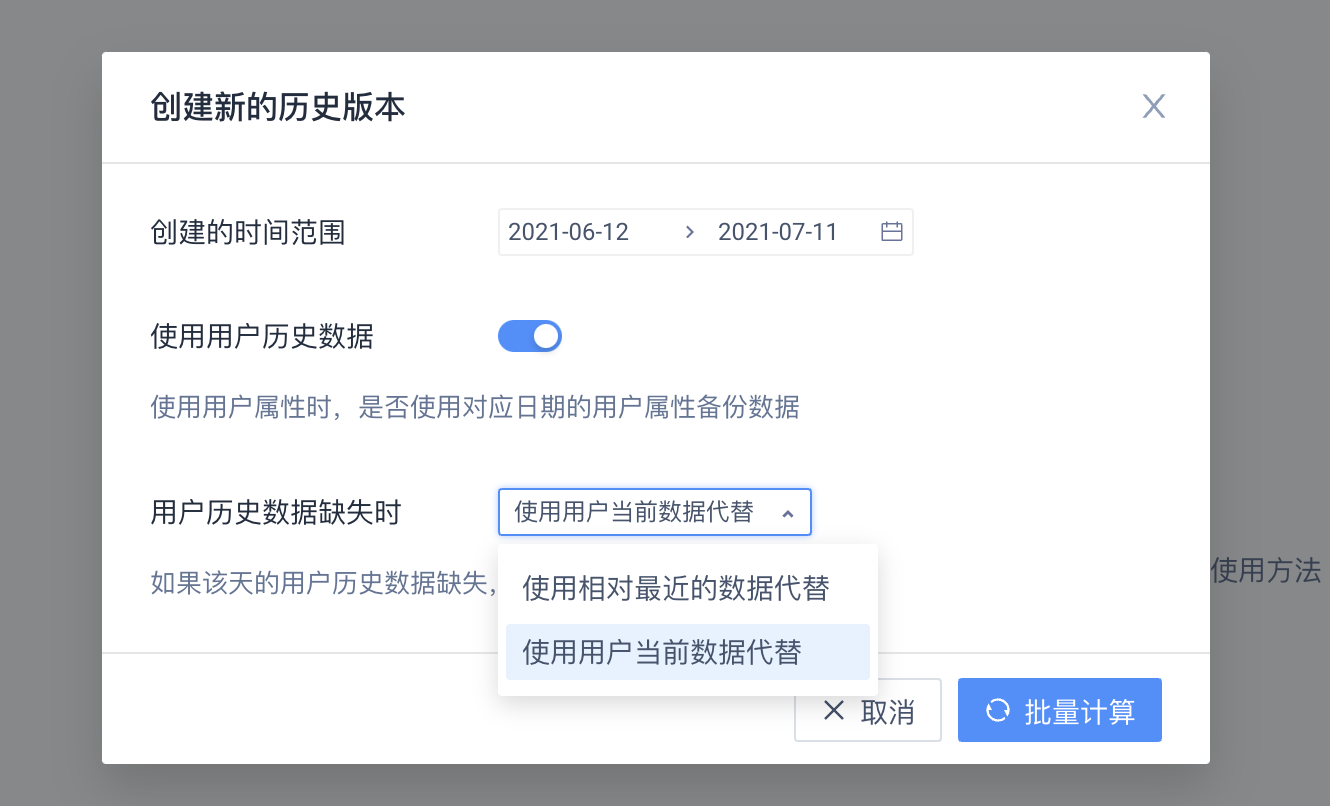
- 是否使用用户历史数据:使用用户属性时,是否使用对应日期的用户属性备份数据
- 用户历史数据缺失时的处理方式:该选项需要在勾选“是否使用用户历史数据”时才可以选择,如果该天的用户历史数据缺失,使用用户当前数据代替还是相对最近的数据代替
# 4.3.3 清理历史版本
如果该标签之前保存的历史版本已经不需要了,可以点击“清理历史版本按钮”,所选日期范围内全部的历史版本都将被清理
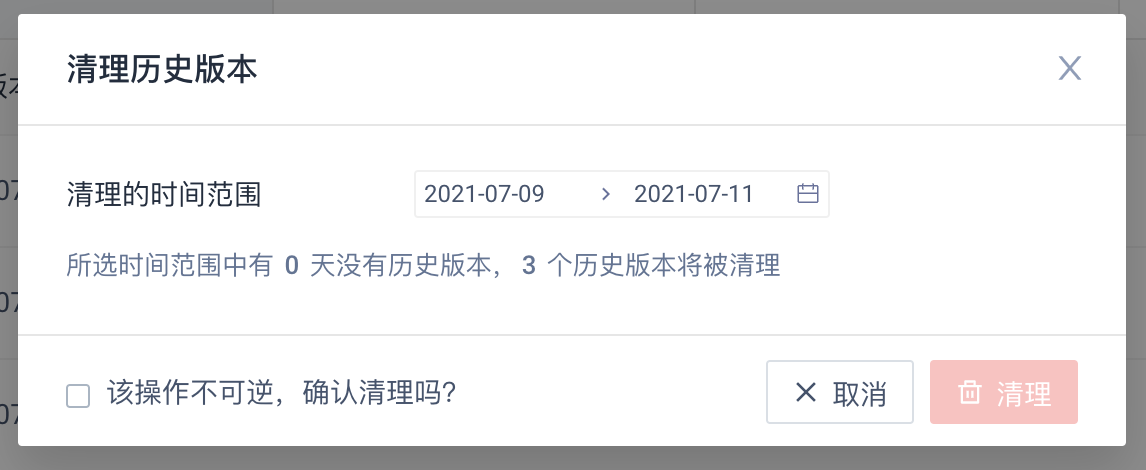
注意:清理历史版本的操作不可逆,在清理前请务必注意;如果不小心清理,可以参考前面的“批量计算”操作补回缺失版本的数据
# 4.4 用户标签在模型中的使用
# 4.4.1 用户标签下的筛选条件
用户标签筛选,进一步选择“标签值”的场景
用户标签中选择“标签”作为筛选项目时,属性逻辑、关联值与“文本”类型相同
关于标签筛选逻辑的列表
| 标签的数据类型 | 可选项 |
|---|---|
| 文本 | 等于、不等于、包括、不包括、有值、无值、正则匹配、正则不匹配 |
| 数值 | 等于、不等于、小于、小于等于、大于、大于等于、有值、无值、区间 |
| 时间 | 位于区间、小于等于、大于等于、相对当前日期、相对事件发生时刻、有值、无值 |
| 列表 | 存在元素、不存在元素、元素位置、有值、无值 |
| 布尔 | 为真、为假、有值、无值 |
# 4.4.2 用户标签分组项使用
选择用户分群、用户标签作为分组项时
| 分组项选项 | 分组下的分组项 |
|---|---|
| 用户标签 | 标签值、(null) |
用户标签下的分组为“标签值”与(null)(相当于不属于标签),如果不想在数据中看到(null),可以在筛选条件里选择该标签“有值”
# 4.4.3 历史标签的使用
如果所使用的标签有历史版本,可以在筛选条件或者分组项使用时指定所需的版本
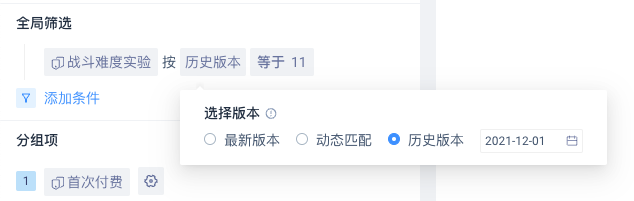
- 最新版本:按用户最新的标签值计算
- 动态匹配:按用户在事件发生当日的标签值计算
- 历史版本:按用户在某个特定日期的标签值计算,仅可选择有数据的历史版本(日期)
注意:目前事件分析、留存分析、漏斗分析、分布分析、路径分析、间隔分析支持标签选择版本,属性分析仅能使用标签的最新版本
# 4.5 用户标签列表页
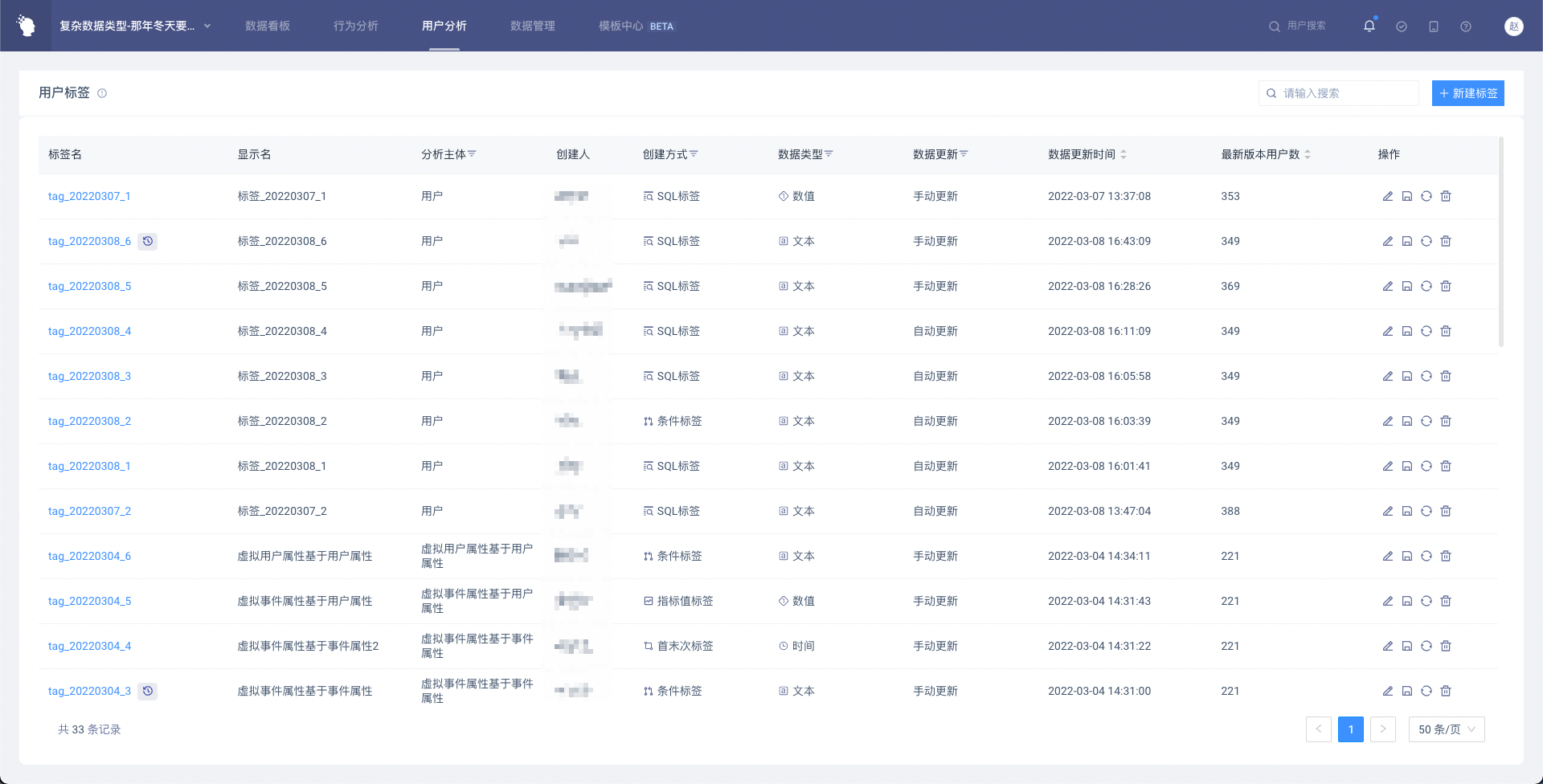
- 通过点击标签名,可以进入用户标签详情页(数据详情);点击标签名旁边的icon可进入用户标签详情页(历史版本管理)
- 点击右上角“新建标签”按钮可创建标签
- 点击操作栏icon可以进行各种操作
- 点击「编辑标签」可进入标签编辑页面
- 点击「另存为」可将当前标签的条件带入标签新建页面
- 点击「更新数据」会以当前日期作为基准更新日期重新计算标签最新版本
- 点击「下载」可以直接下载用户标签数据(仅ID上传标签有该按钮)
- 点击「删除」可以删除该标签。请注意,标签删除后使用该标签的报表、虚拟属性将不可用
# 4.6 用户标签详情页
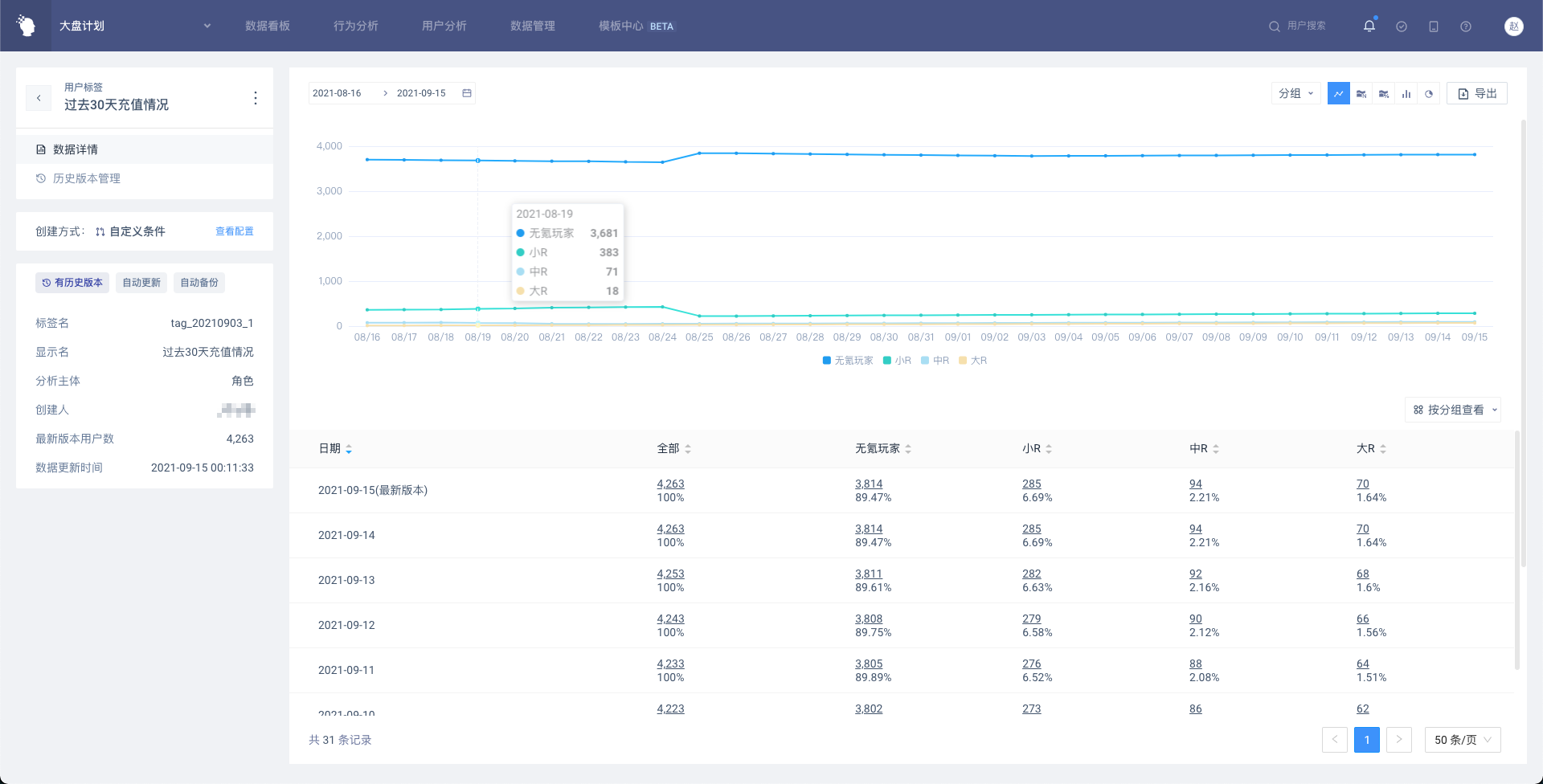
用户标签详情页,包含标签基础信息、数据详情和历史版本管理三部分
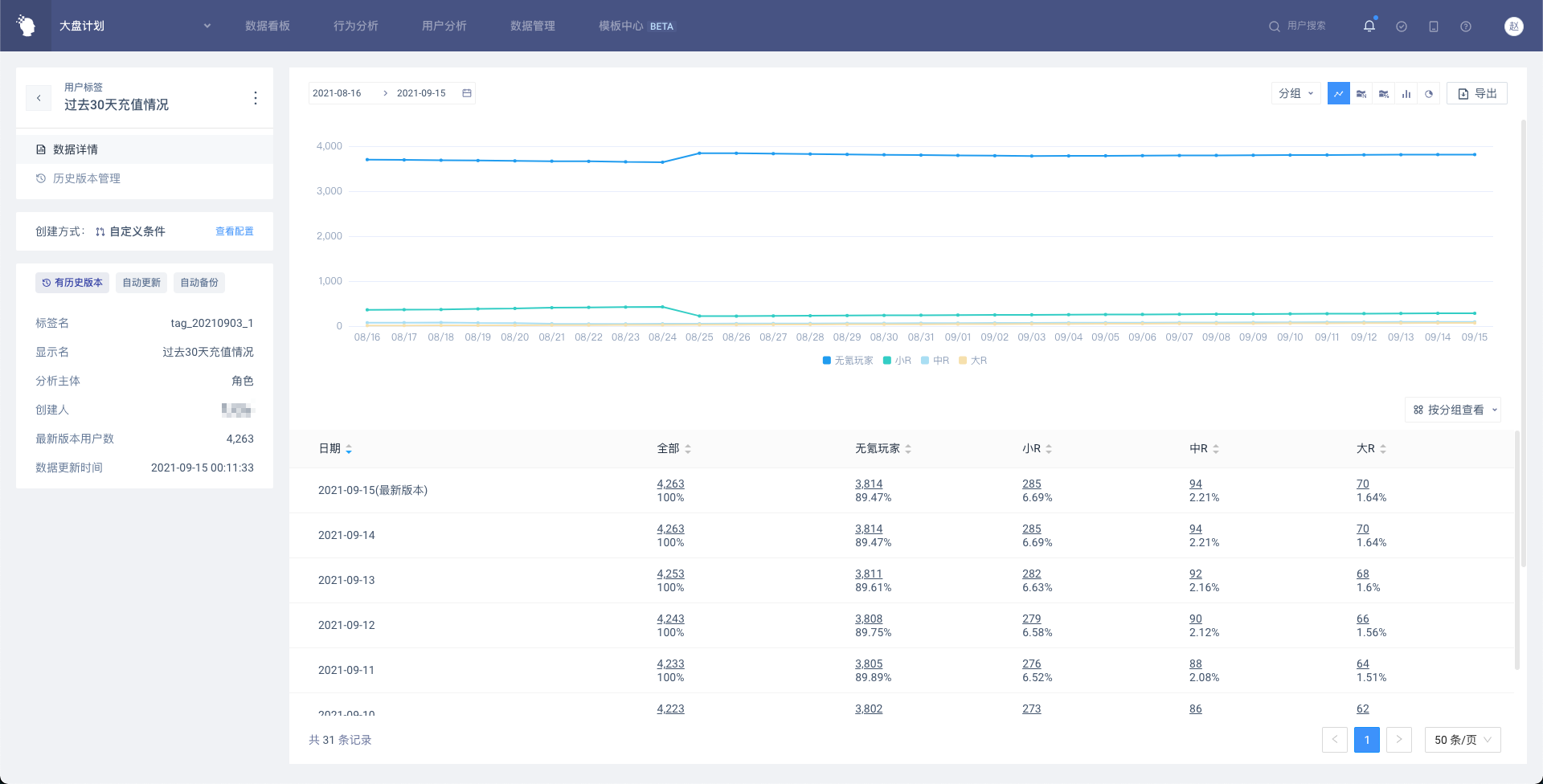
# 4.6.1 标签基础信息
展示标签基础信息,和用户标签列表页展示内容基本一致
点击「查看配置」即可打开详情弹窗,查看具体的创建条件
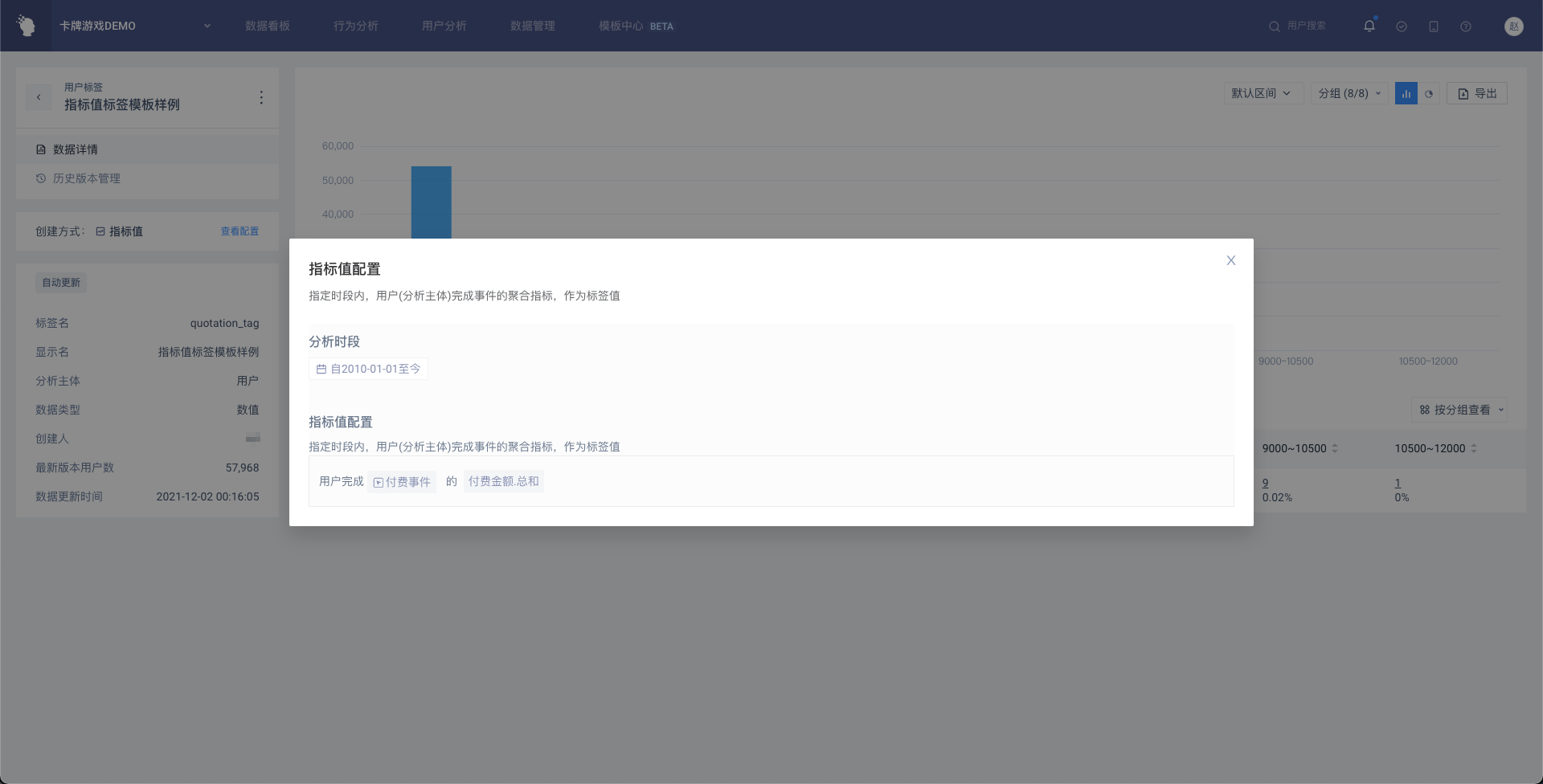
点击标签名称旁边的「更多」按钮,可以进行操作,同用户标签列表页一致
# 4.6.2 数据详情
展示标签最新版本和历史版本的数据,最新版本将以「今天」的日期展示,默认会展示最近31天的数据(过去30天+最新版本),如果历史版本的时间跨度不到30天,即最早一份历史版本的日期在30天内,则展示从该日期到今天的数据。
如果标签值的类型是数值型、列表型或时间型,可以自定义数据的汇总方式
(1)表格展示
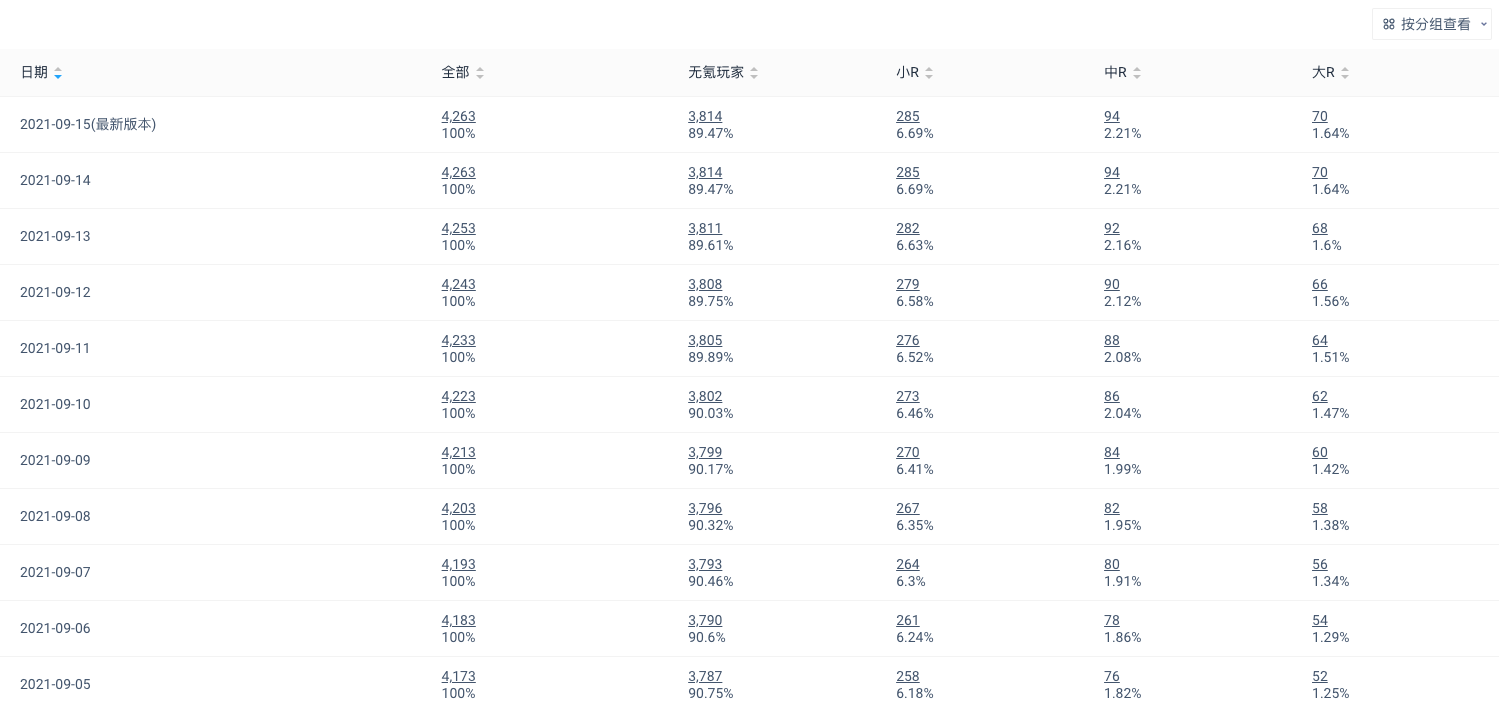
表格内展示按标签值分组后的用户数量及占比,同时展示「全部」,即有标签值的所有用户。点击带下划线的数字可以进入用户列表,和分析模型一致,用户列表除了属性外,还会展示标签值和标签日期。
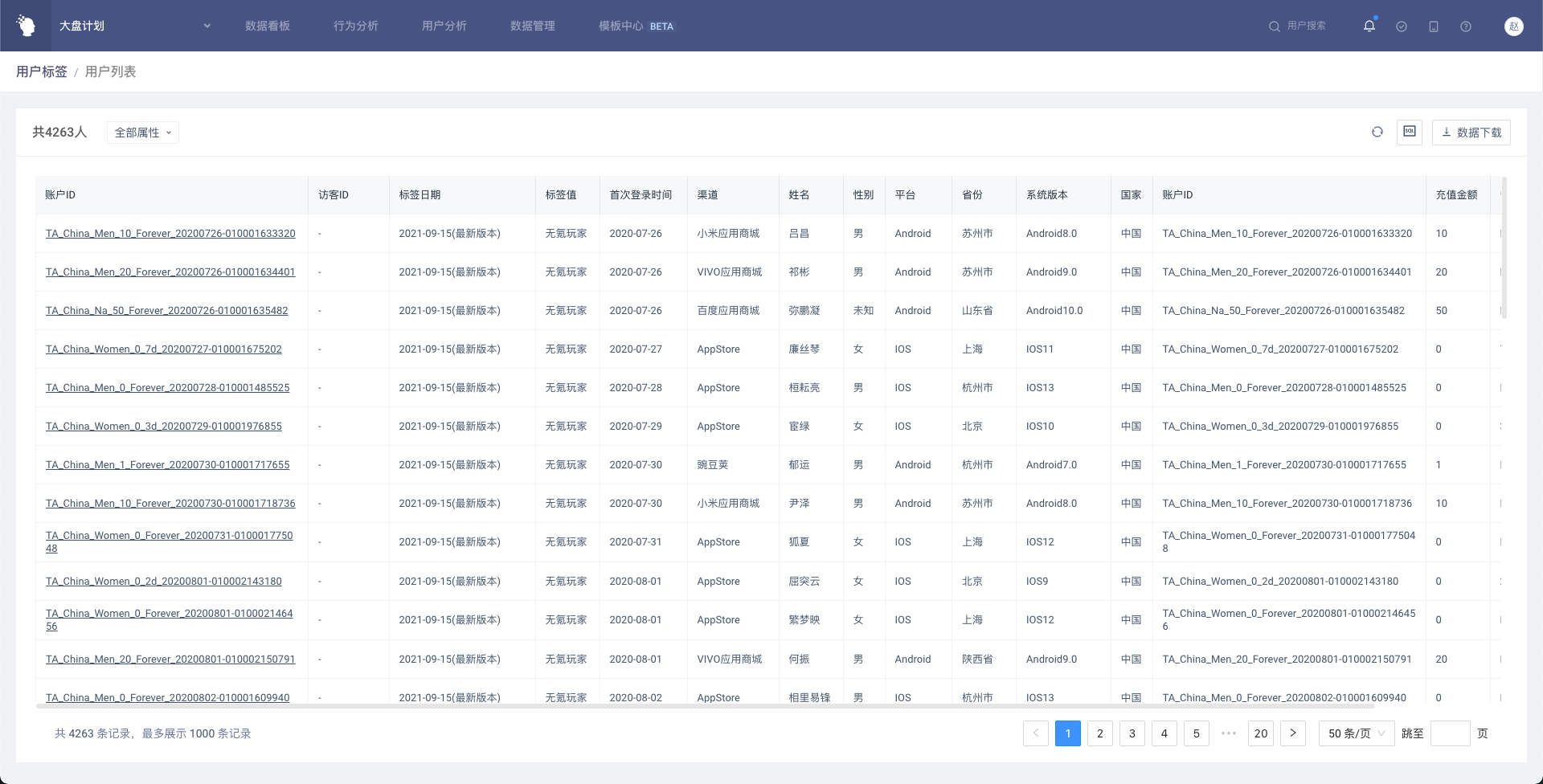
表格支持两种展示样式,默认为按分组查看
按分组查看
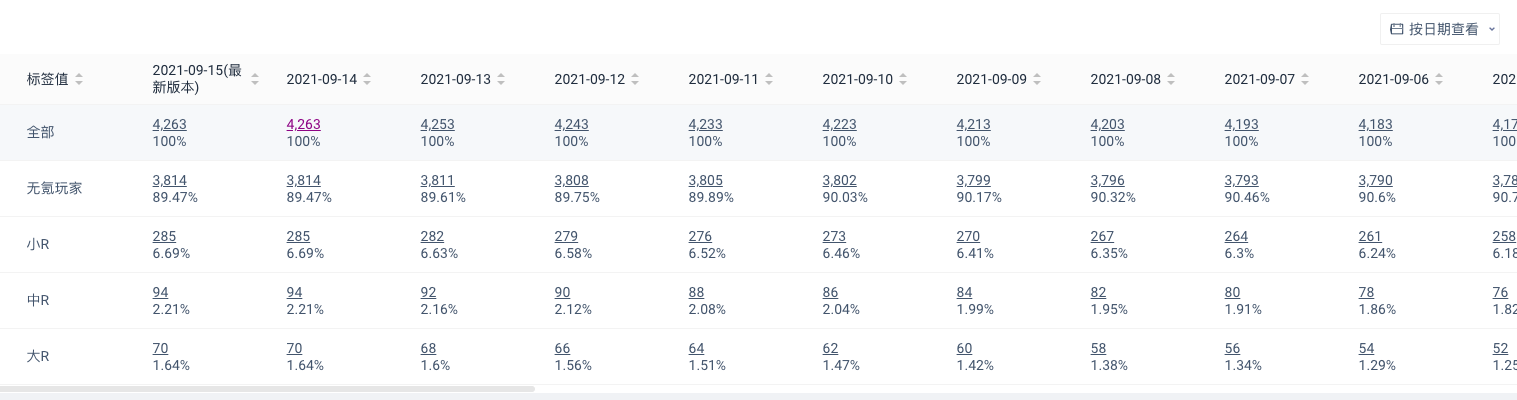
按日期查看
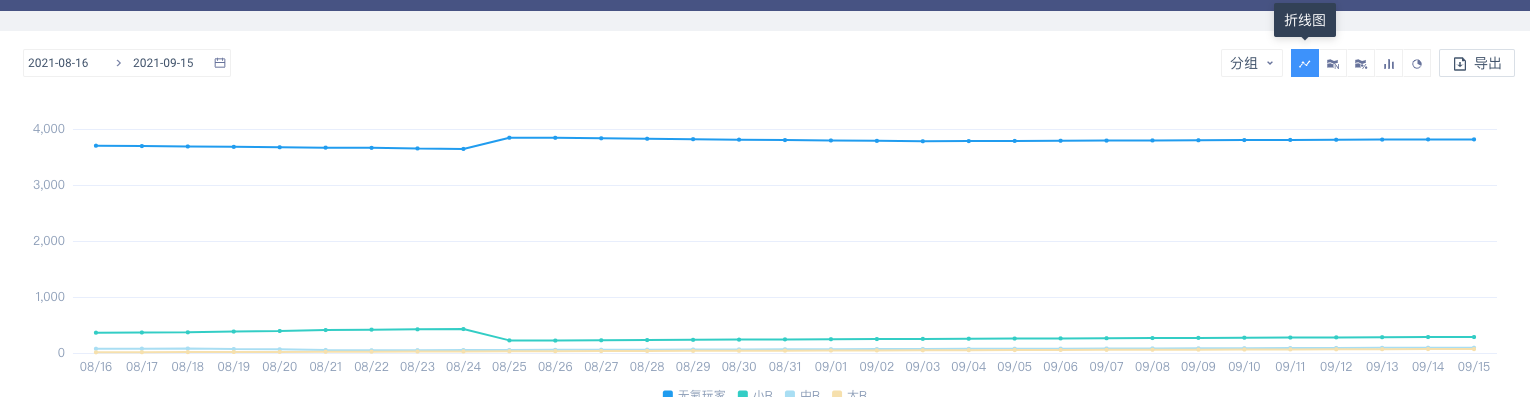
(2)图表展示
如果标签有历史版本,则支持所有图表类型;如果标签没有历史版本,则只能按柱状图、饼图展示。当有历史版本的标签切换到柱状图或者饼图时,需要从日期范围内选择需要展示的版本
折线图
数值堆积图
百分比堆积图
柱状图
饼图
# 4.6.3 历史版本管理
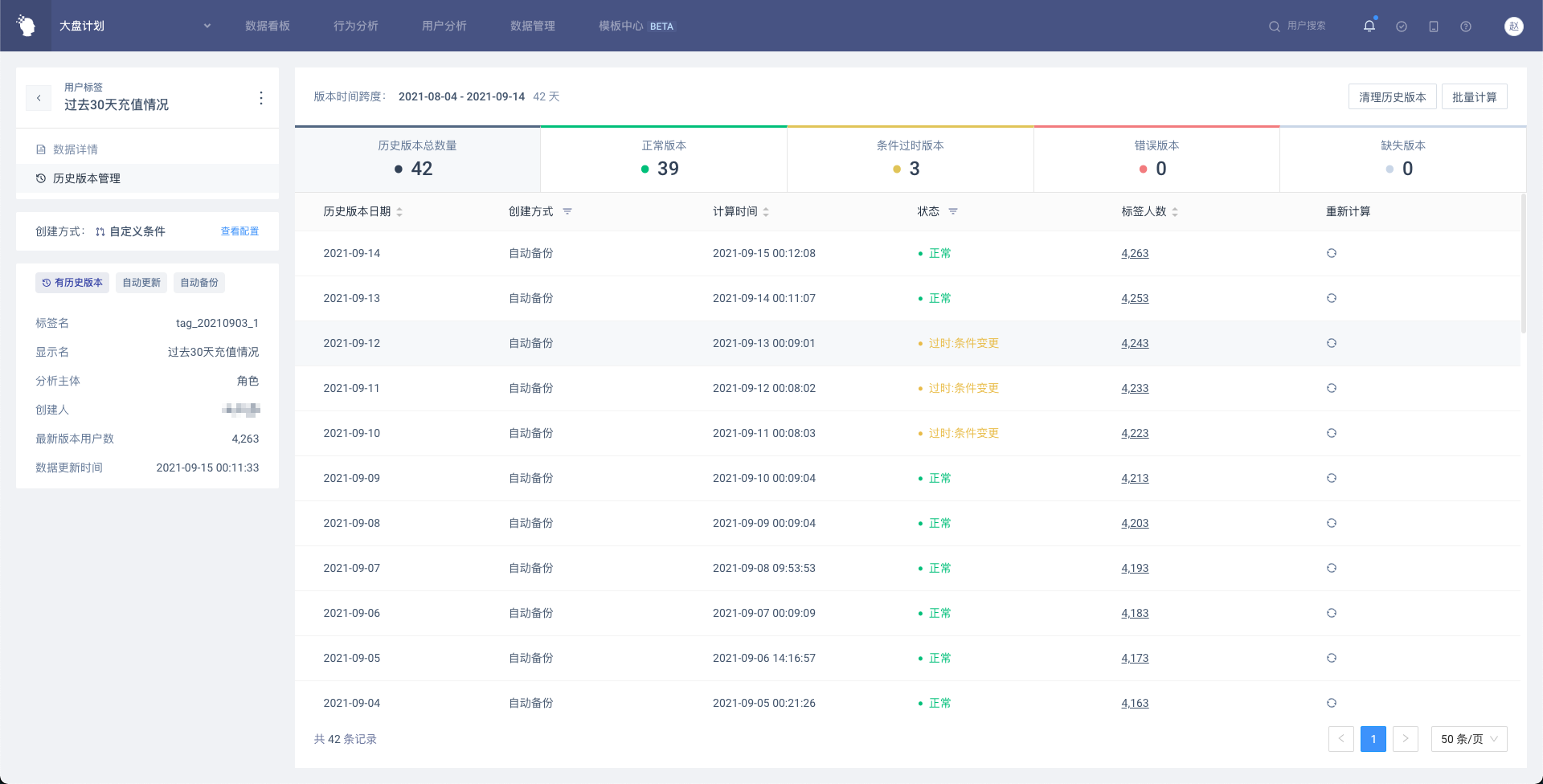
1.历史版本概览
展示历史版本宏观数据,包括跨越的时间段、包含天数、版本数,以及异常状态的版本数等等
2.历史版本列表
展示跨度内的每一天的历史版本信息以及状态,可在列表中进行操作
版本状态及说明:
- 正常
- 缺失:该日期没有历史版本
- 过时(条件变更):该历史版本使用的标签逻辑和当前的标签逻辑不一致
- 过时(类型变更):该历史版本的标签值的数据类型和当前的标签逻辑不一致
- 计算中:正在计算中,计算完成后会有消息通知
- 计算失败:计算发生异常,未成功计算
- 排队状态:等待计算
# 五、最佳实践
# 5.1 获取历史行为指标
通过“指标值”标签,可以计算出每个用户历史行为的指标,比如历史总付费金额(即全生命周期付费额),启动应用的总次数以及总时长等等。这些总体指标,能够很好地对用户进行分层,无论是在属性分析中直接查看标签值的分布情况,还是在分析模型中使用标签做分组和筛选,标签都可以起到非常强大的作用。
# 5.2 获取首次行为
通过“首末次特征”标签,可以计算出每个用户首次产生某行为的时间,搭配虚拟属性可以获取首次事件标识(将标签中的首次时间和事件时间相比,相等则为首次,反之则不为首次)。在创建标签增加更多筛选条件,可以获取更为定制化的首次事件。
# 5.3 使用历史标签准确还原事件发生时的用户状态
同一个用户,随时间推移可能从“小R”变为“大R”,按用户付费级别分组的时候,应该把该用户昨天产生的行为,认为是小R产生的,今天产生的行为,认为是大R产生的。所以计算历史上用户的“总充值金额”标签后,将该标签作为分组项,按照“动态匹配”的方式,查看每日的数据,就能得到想要的结果了。
# 5.4 查看每天回流用户的表现
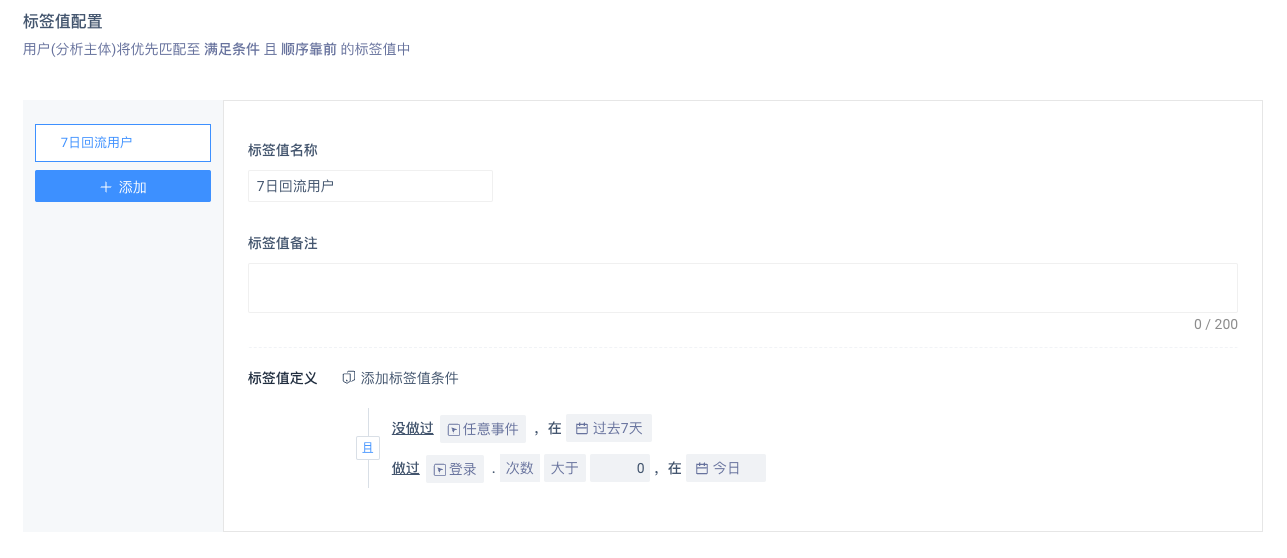
通过“自定义条件”标签,可以按以下条件筛选出当日回流用户:
- 今天有登录
- 过去7天没有任意事件(即未登录)
# 5.5 按账号统计累计充值金额
创建标签时,可以使用自定义分析主体作为标签对象,切换后逻辑也将相应调整;以付费事件为例,创建指标值标签:
- 分析时段为自1月1日至今
- 标签值为付费事件的付费金额总和
- 分析主体为账号(用户属性,预置分析主体为角色,一个账号下可以有多个角色)
该逻辑代表的含义是,以1月1日至今,单个账号下所有角色的付费金额总和作为该账户ID的累计充值金额
关于分析主体的更多说明,可以参考分析主体
# 5.6 使用SQL标签统计连续登录天数
通过SQL标签,可以实现较为复杂的标签逻辑,比如按用户在过去30天的最大连续登录天数给用户打标签,示例如下
WITH
dataset AS (
SELECT
"#user_id"
, ta_date_trunc('day', "#event_time", 1) "date"
FROM
v_event_2
WHERE ("$part_event" = 'login') AND ${PartDate:date1}
GROUP BY "#user_id", ta_date_trunc('day', "#event_time", 1)
)
SELECT
"#user_id"
, max(days_count) max_days
FROM
(
SELECT
"#user_id"
, start_date
, count(1) days_count
FROM
(
SELECT
*
, row_number() OVER (PARTITION BY "#user_id" ORDER BY "date" ASC) row_number
, date_add('day', -(row_number() OVER (PARTITION BY "#user_id" ORDER BY "date" ASC)), "date") start_date
FROM
dataset
ORDER BY "#user_id" ASC, "date" ASC
)
GROUP BY "#user_id", start_date
ORDER BY "#user_id" ASC, start_date ASC
)
GROUP BY "#user_id"
ORDER BY max_days desc