# Data Deduplicate Tool
# I. Introduction
The data deduplicate tool is mainly used to deduplicate the duplicate event data in the TA system, and supports deduplicate event data according to the time period and event type.
Because deduplicate will take up cluster computing resources, we recommend deduplicate only when the data is abnormal. It is not recommended to deduplicate data frequently. Please use this tool carefully.
# II. Instructions for Use
The data deduplicate tool only supports users of self-hosting services. root logs into any server of the self-hosting cluster and executes su-ta
Then execute the ta-tool dupevent_delto enter the data deduplicate tool interface.
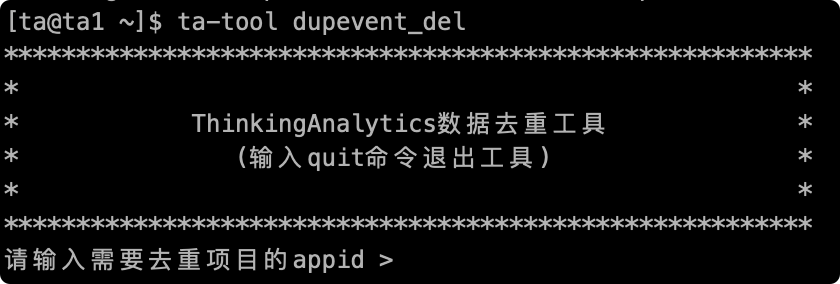
# 2.1 Fill in the appid of the project to be processed
The appid of the project can be queried in the project management page in the TA background.
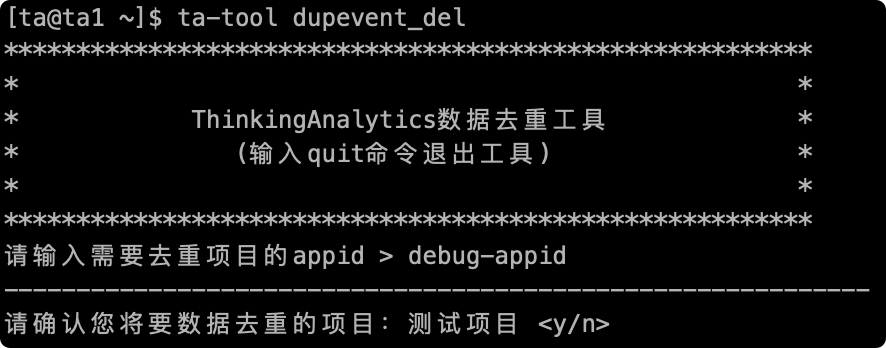
# 2.2 Confirm the project name
After entering, the project name of the project that needs to be deduplicated will be prompted, enter "y" to confirm, and enter "n" to cancel the operation
# 2.3 Fill in the event name that needs to be deduplicated
Next, you need to enter the **event name **of the deduplicate event. The event name entered here is the key value when transferring data, **not the display name **. You can query the event name in the metadata management page, and deduplicate multiple events are available. "," Split, and you will be prompted to deduplicate the event name after entering.
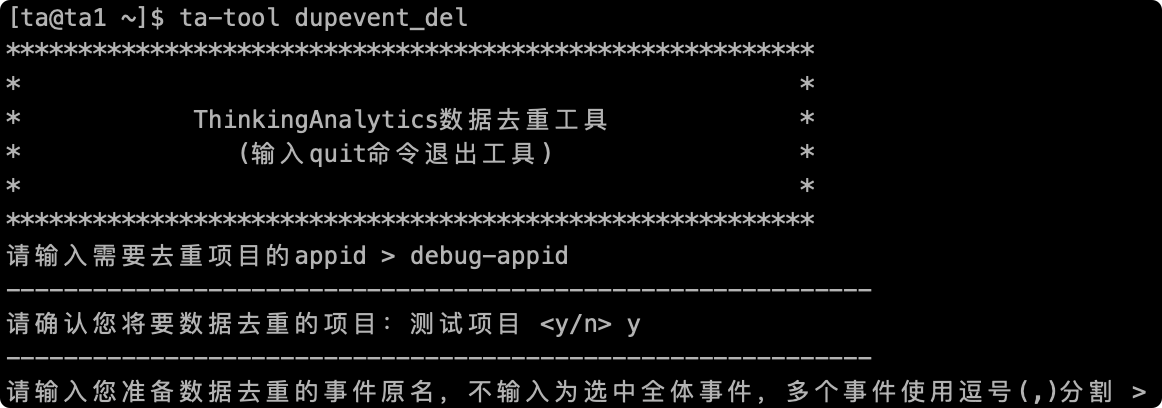
If you do not enter any characters to confirm the carriage directly, all event data will be deduplicated:

# 2.4 Fill in column names ignored in deduplicate logic
Next, you need to enter the field name to determine the deduplicate logic is ignored, the default has been removed ta self-use field to participate in repeating logic judgment, such as "#server_time", "#kafka_offset" field does not participate in repeating judgment logic, ignoring multiple fields available "," split, after the input will prompt the field name to be ignored.
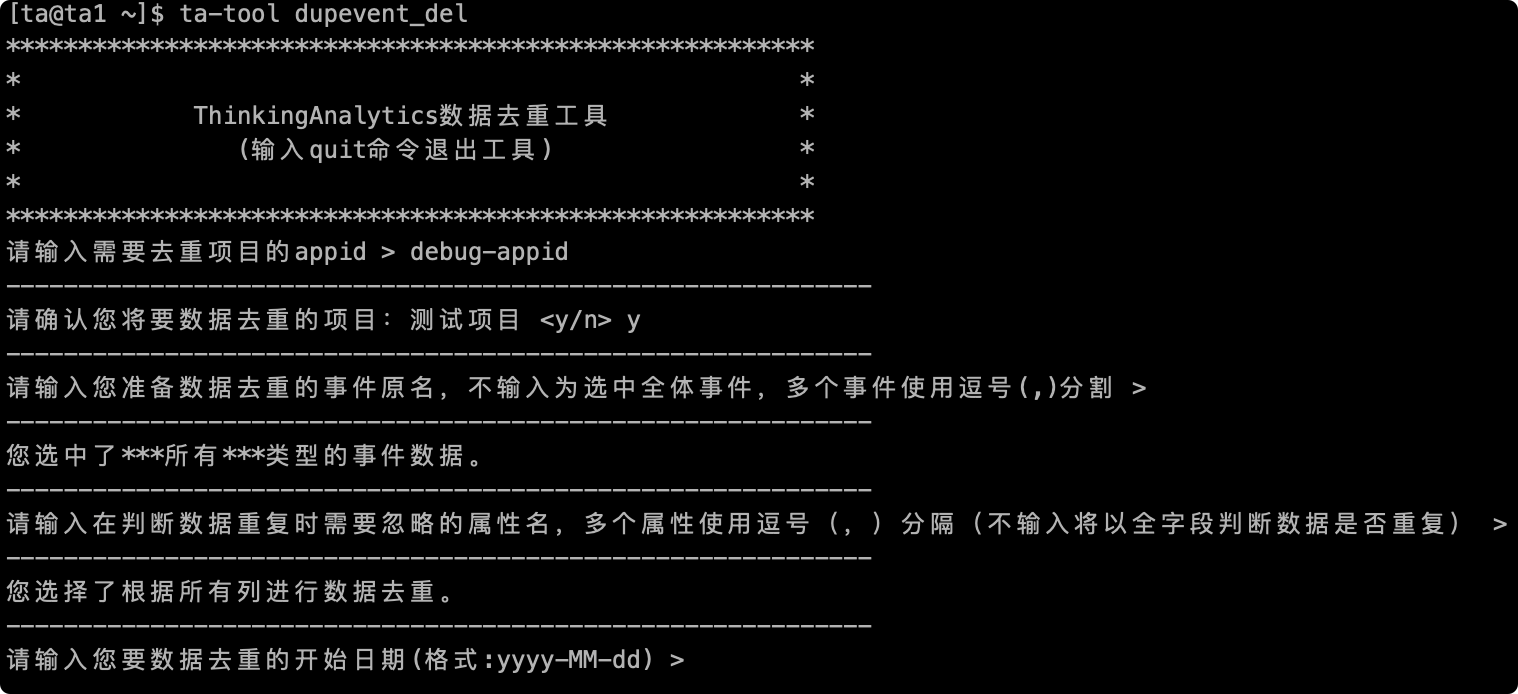
# 2.5 Fill in the time range of deduplicate event data
Next, you need to enter the time period for deduplicate data. The optional time granularity is "days". Please enter the date in the format of yyy-MM-dd. This item is a must-enter item):
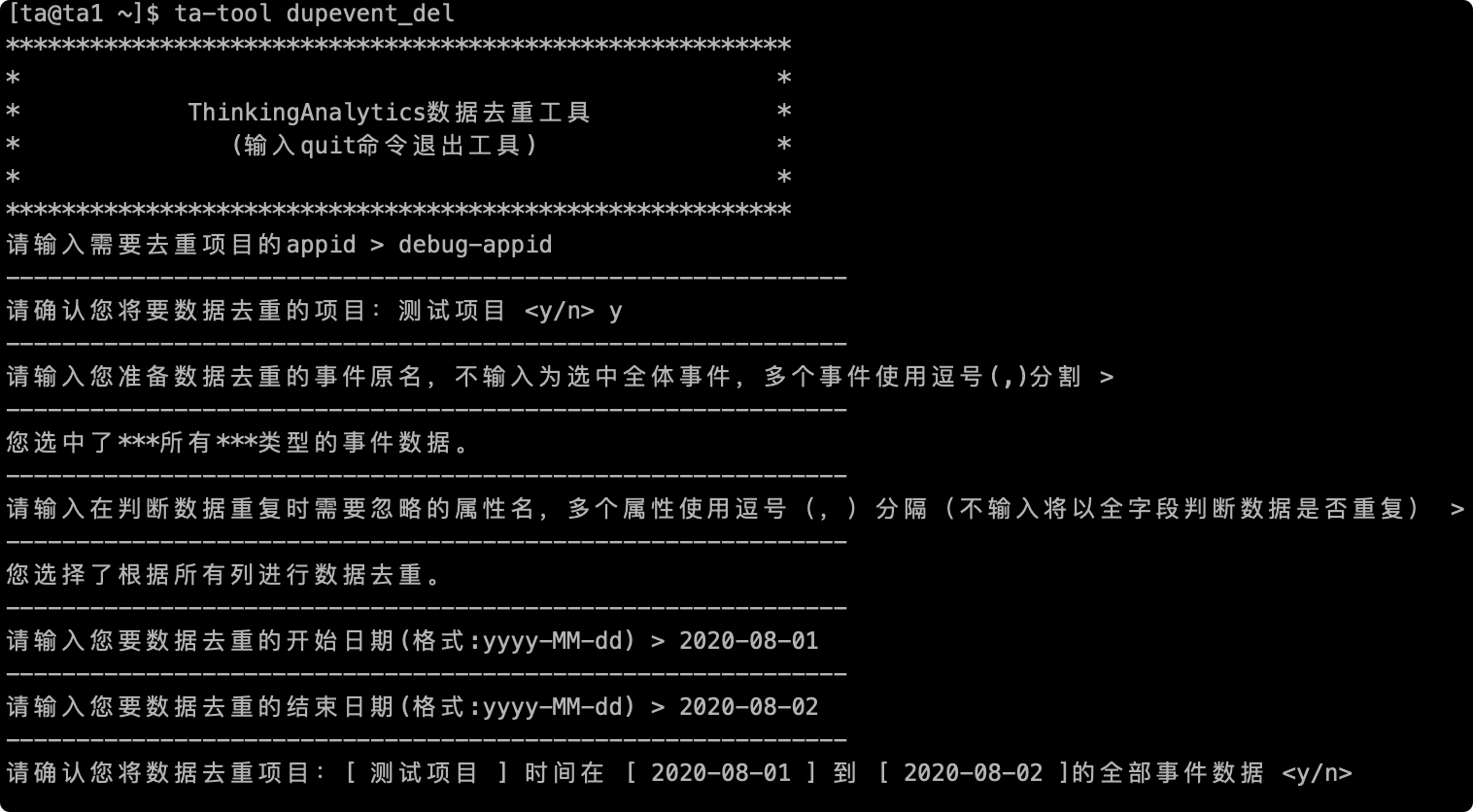
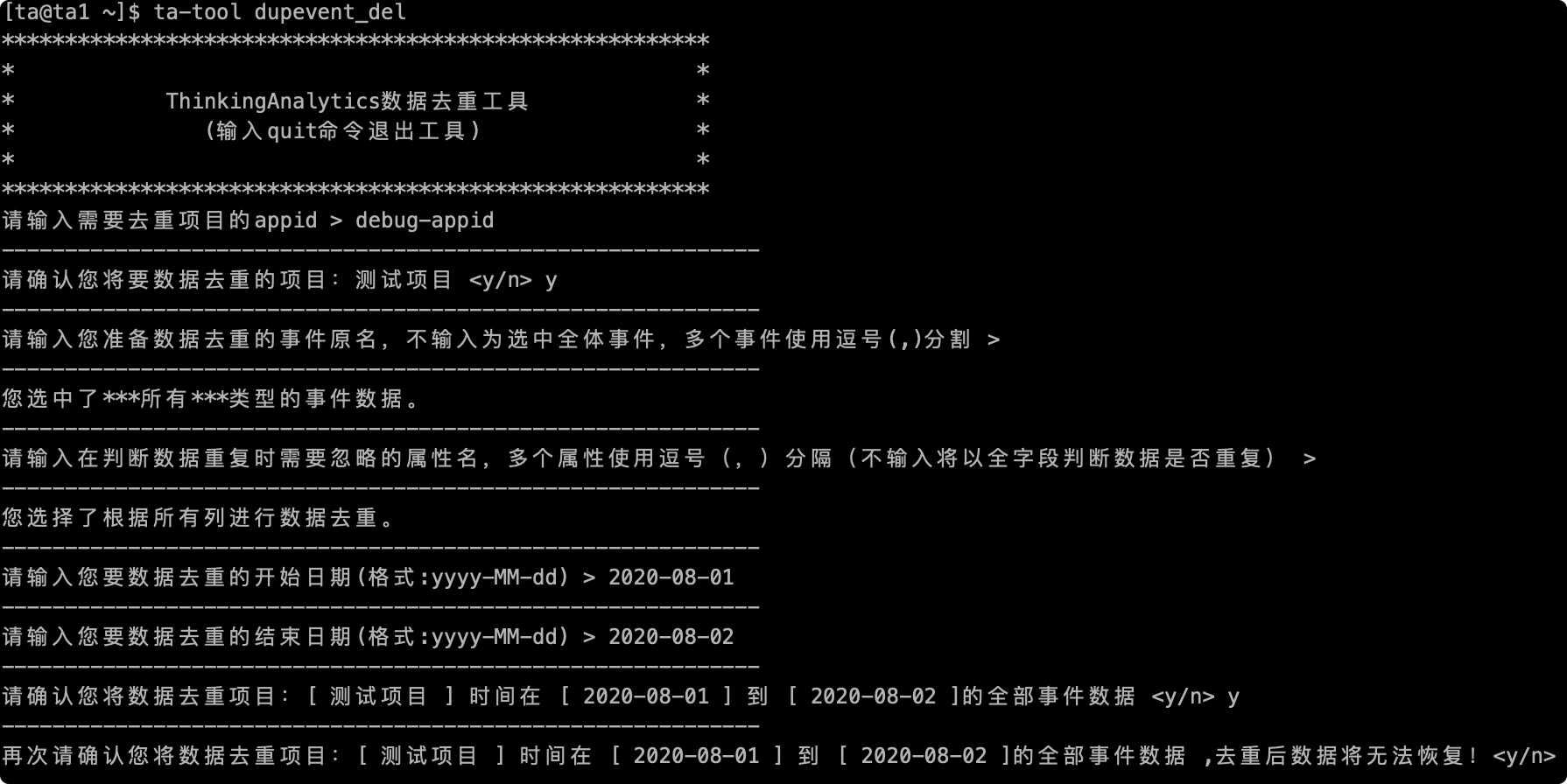
# 2.6 Final confirmation
Finally, before the data is deduplicated, the final confirmation will be made, including the name of the deduplicate project, the name of the deduplicate event and the deduplicate period. Enter "y" to start processing the data. If there is an error, enter "n" to exit the tool and re-enter:
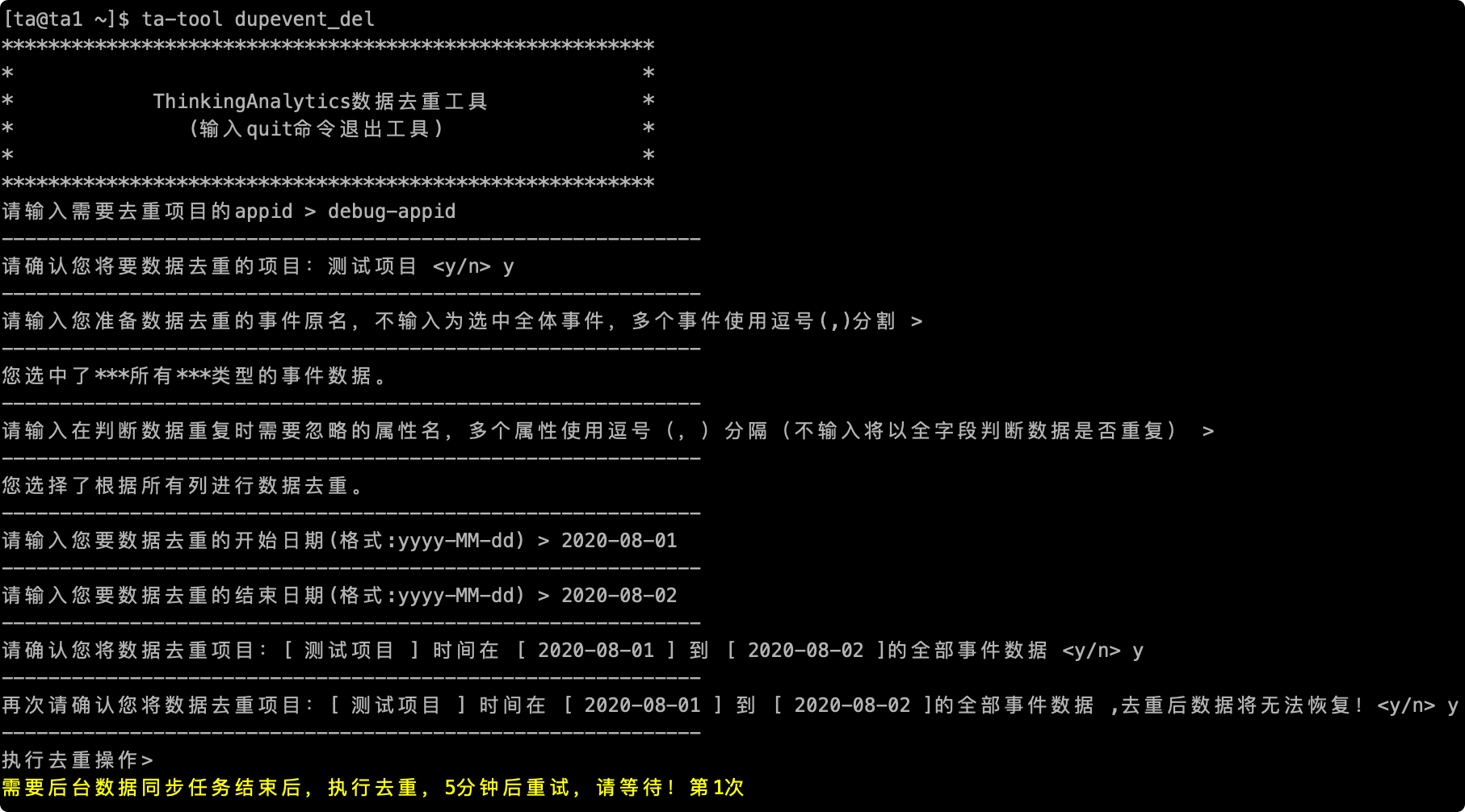
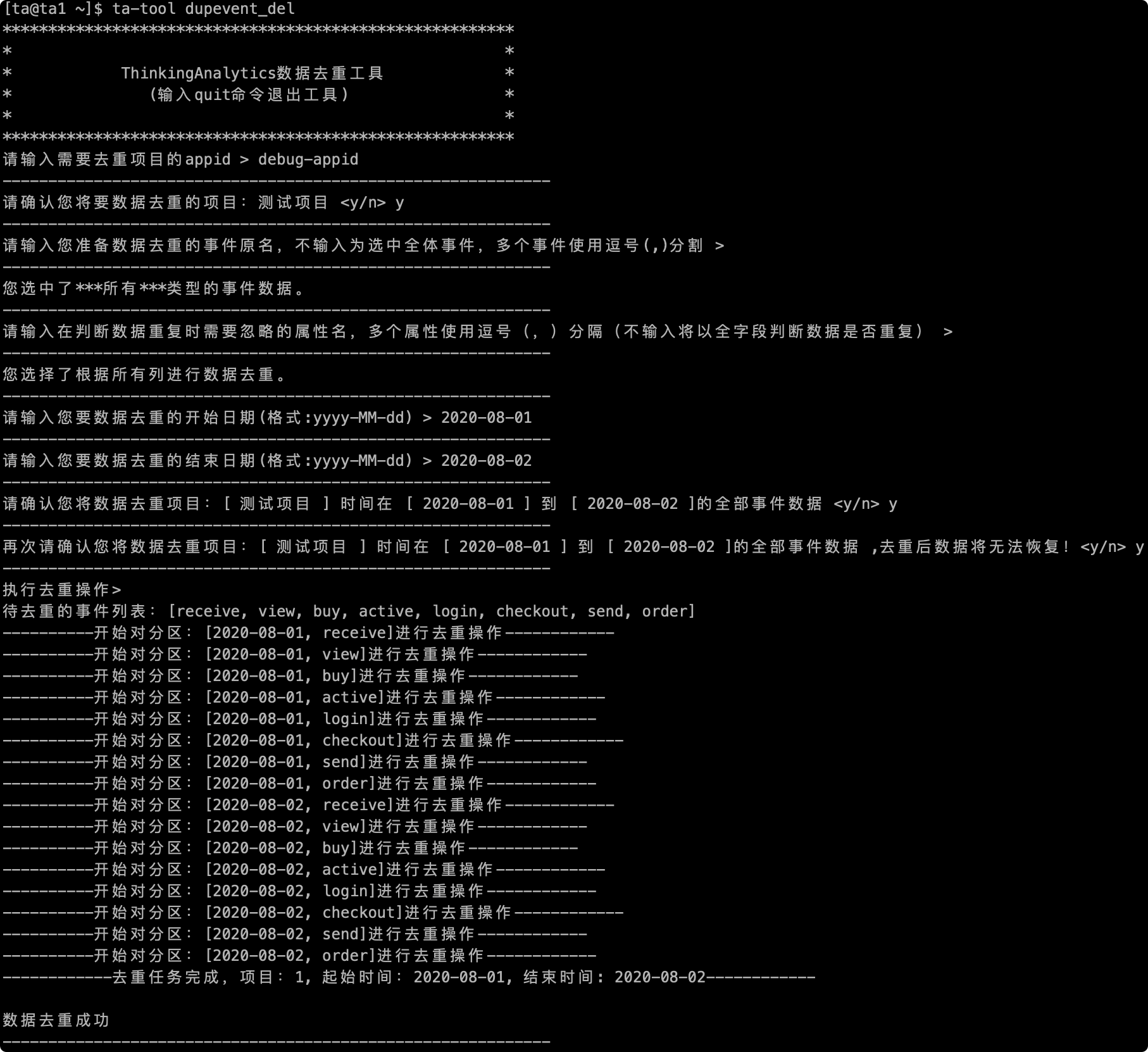
# 2.7 Complete Execution Process
After confirmation, the data will be deduplicated, as shown in the following figure to deduplicate the screenshot of the whole process:
# III. Precautions
# 1 Before using the data deduplicate tool, please confirm the cause of data duplication to avoid deduplicate data entering at the same time, and the deduplicate effect cannot be guaranteed.
# 2 deduplicate requires cluster computing resources and is not recommended for frequent use.
# 3 If the following screenshot occurs, the cluster is merging data, and it can wait for its own automatic execution. If it is stuck at the second place for a long time, it can contact the operation and maintenance personnel for investigation.