# データ重複除去ツール
# I.プロフィール
データ重複除去ツールは、主にTEシステム内の重複イベントデータを再処理するために使用され、時間とイベントタイプに応じてイベントデータを再調整することをサポートします。
重複するとクラスターの計算リソースを占有するため、データが異常な場合にのみデータを重複することをお勧めします。頻繁にデータを重複することはお勧めしません。本ツールを慎重に使用してください。
# 二、使用説明
データ重複除去ツールは私有化サービスのユーザーだけが使用できる。rootユーザーは民営化クラスタの任意のサーバにログインし、su-taを実行su-ta
を実行ta-tool dupevent_del、データ重複除去ツールインターフェイスに入ります。
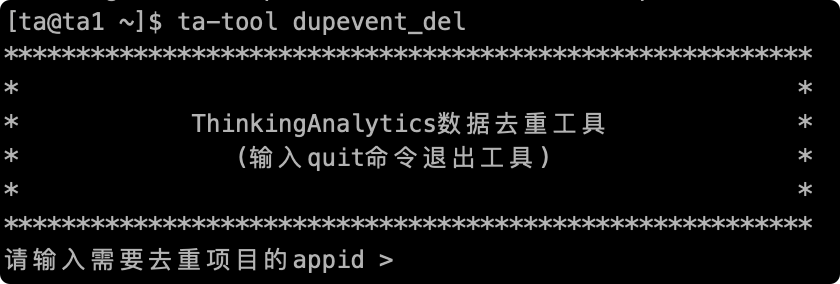
# 2.1処理項目を記入するappid
プロジェクトのappidは、TEバックグラウンドのプロジェクト管理ページで照会できます。
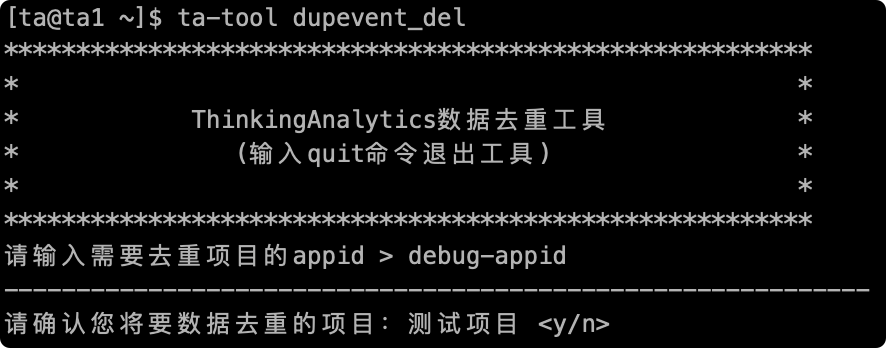
# 2.2確認項目名
入力が終わると、重み付けが必要な項目の項目名を提示し、「y」と入力して確認し、「n」と入力して操作をキャンセル
# 2.3やり直しが必要なイベント名の記入
次に、イベントをリセットするイベント名ます。ここで入力したイベント名はデータを転送するときのkey値で、表示名では。メタデータ管理ページでイベント名を照会して、複数のイベントをリセットすることができます。「」分割して、入力が完了すると、リセットするイベント名をプロンプトします。
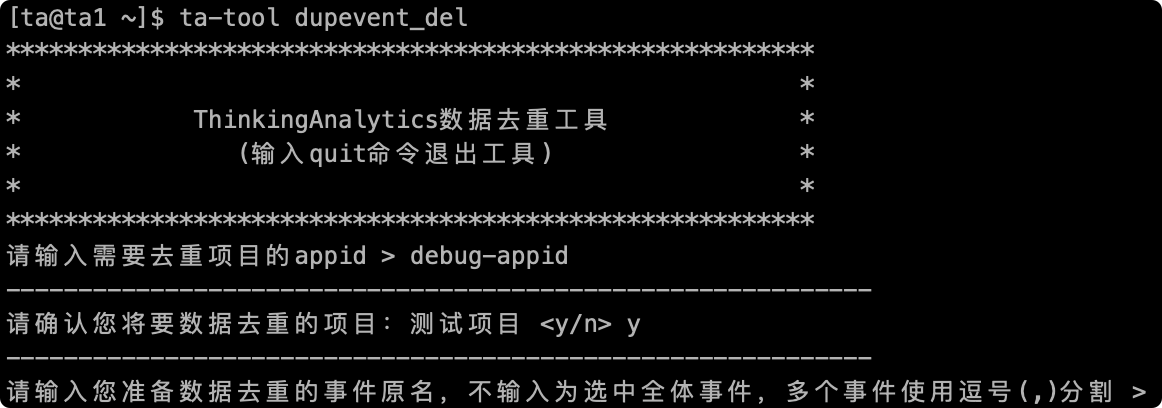
文字を入力せずに確認に直接戻ると、すべてのイベントデータが重複していると見なされます

# 2.4重複除去論理で無視した列名を記入
次に、判断を再論理無視にするフィールド名を入力する必要があり、デフォルトではTEの自己使用フィールドを削除して重複論理判断に参加している。例えば、「#server_time」、「#kafka_offset」フィールドは重複判断論理に参加しておらず、複数のフィールドを無視して使用できる」、「分割して、入力後に無視するフィールド名を提示する。
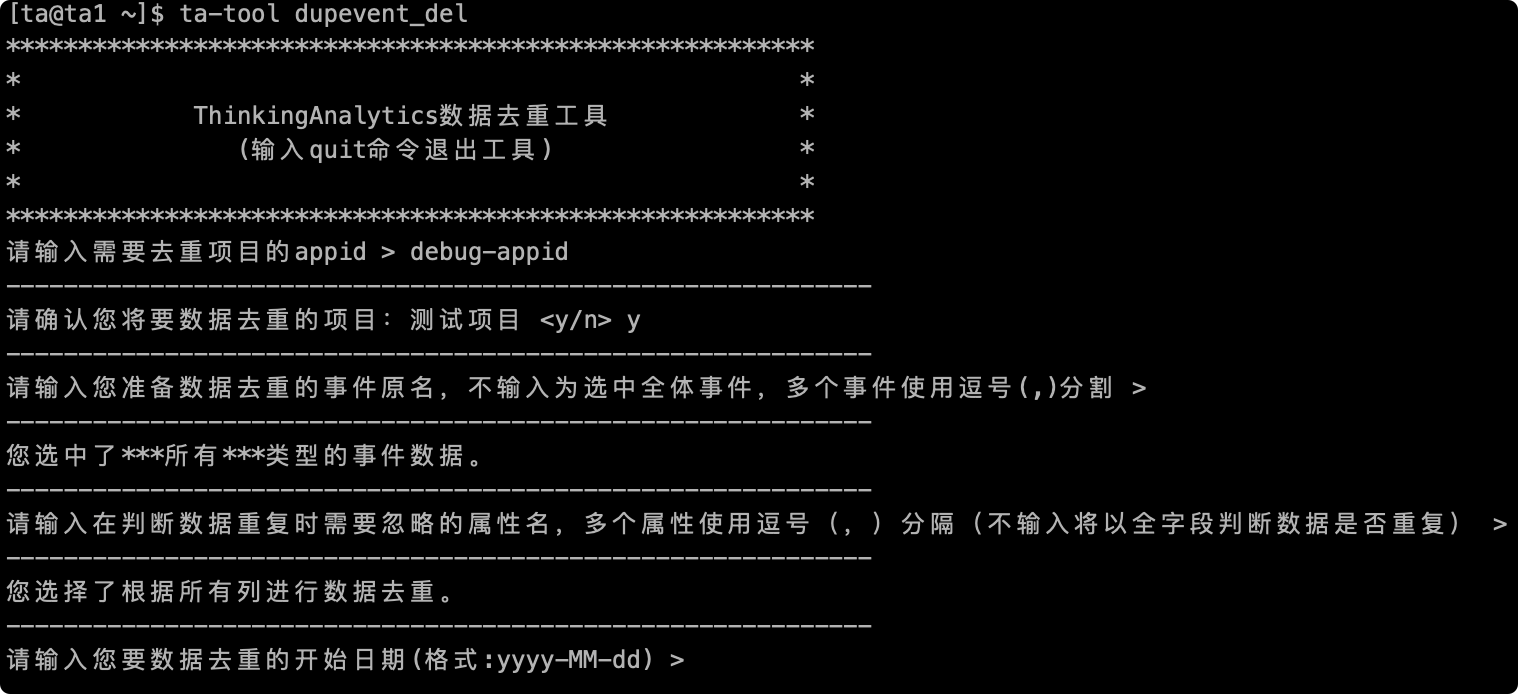
# 2.5再イベントデータを記入する時間範囲
次に重複データを入力する必要がある時間帯は、オプションの時間粒度が「日」で、yyy-MM-ddの形式で日付を入力してください。
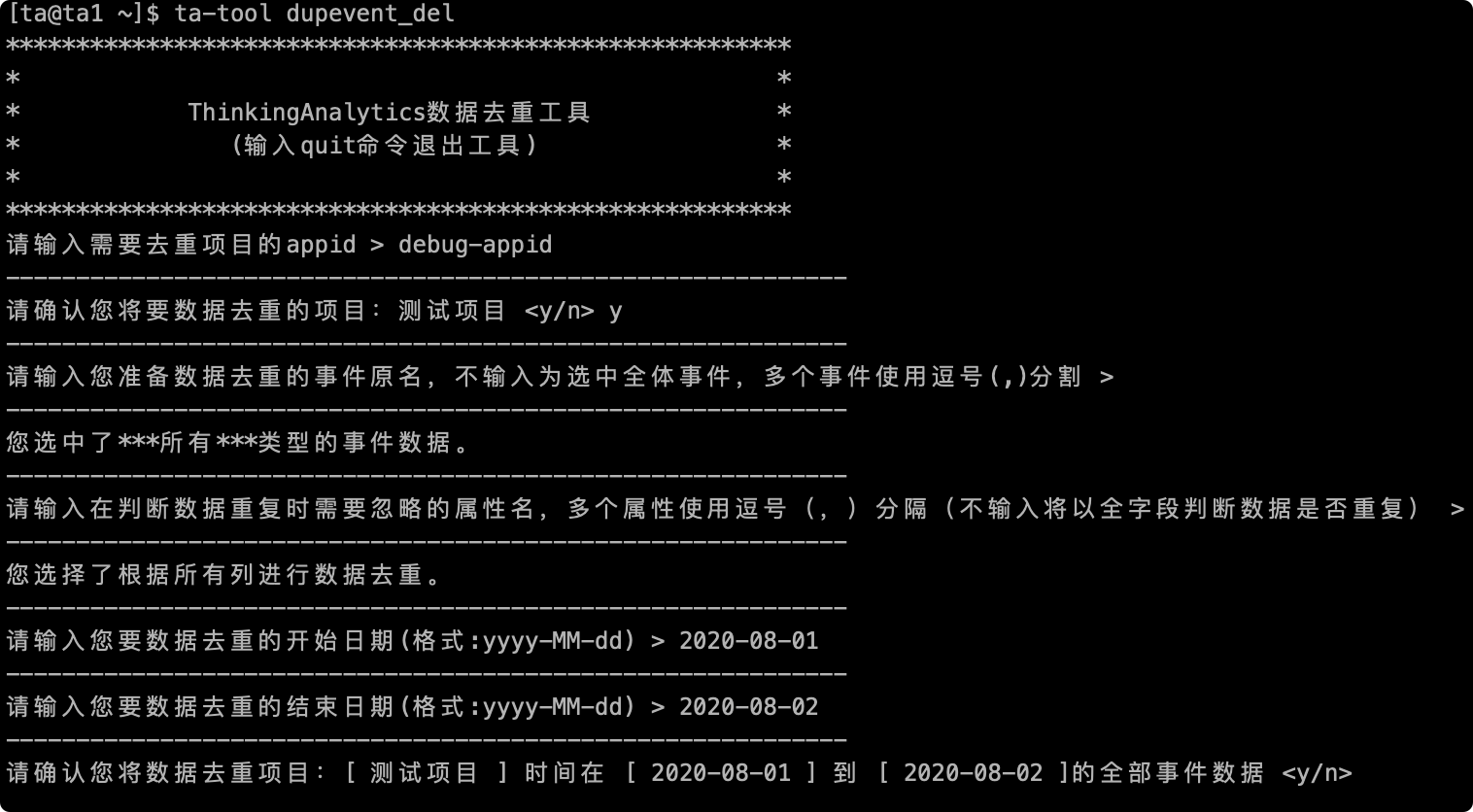
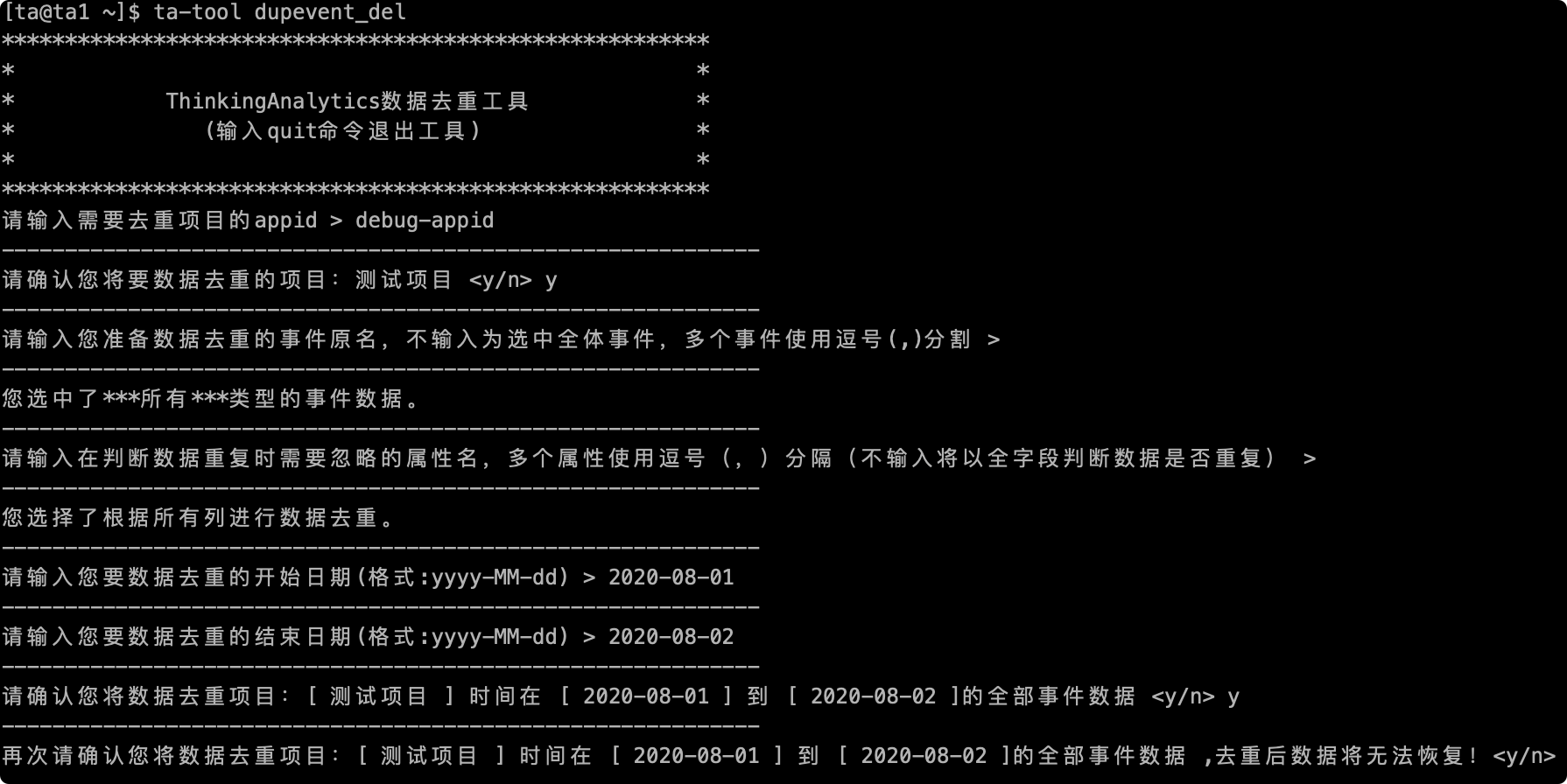
# 2.6最終確認
最後にデータが重複する前に、最後の確認を行います。重複項目の名前、重複イベントの名前、重複期間を含めて、「y」を入力してデータの処理を開始し、エラーがあれば「n」を入力してツールを終了して再入力できます
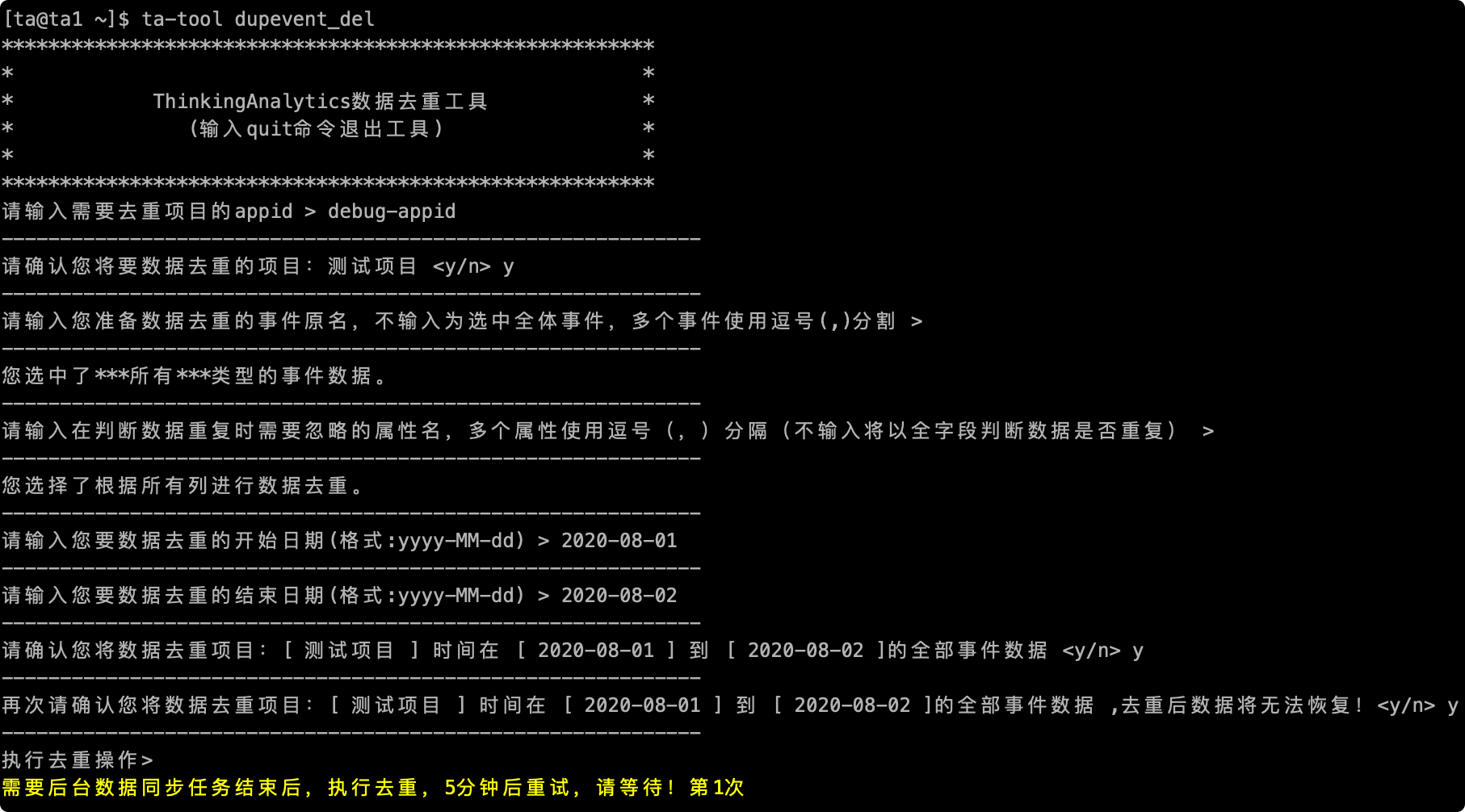
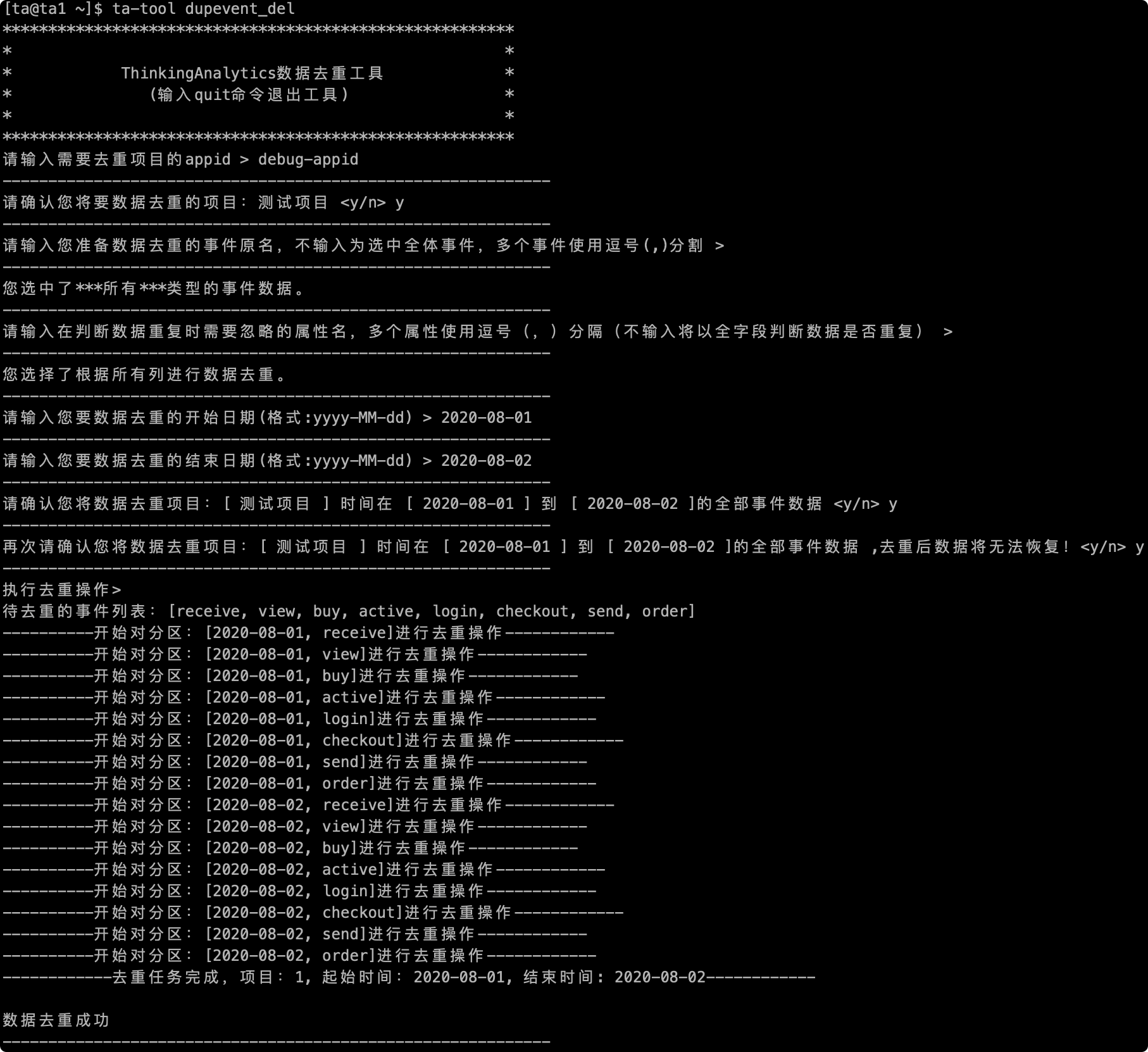
# 2.7完全な実行プロセス
確認後、データの再調整が行われます。次の図は、プロセス全体のスクリーンショットを再調整します
# 三、注意事項
# 1データ重複ツールを使用する前に、データ重複の原因を確認して、重複を避けると同時に重複データが入って、重複効果を保証できない。
# 2再調整にはクラスタ計算資源を占有する必要があり、頻繁な使用は推奨しない。
# 3次のようなスクリーンショットが発生した場合、クラスタがデータ統合を行っているので、彼自身が自動的に実行するのを待つことができ、長時間カードが次の場所にある場合は、メッセンジャーに連絡してチェックすることができる。