# SQLクエリ
# I. SQLクエリの概要
分析モデルを使用して実装するのが難しい高度な分析では、SQLクエリを使用して実装できます。TEシステムはPrestoクエリエンジンを使用し、標準SQLを使用してシステム内のすべてのデータをすばやくクエリできます。
加えて、動的パラメータの機能を提供して、ユーザーがSQL文を修正することなく、パラメータ値を調整する方法で、文の一部のパラメータ内容を変更して新しいクエリ条件に適応し、一度に作成し、何度も使用することを実現します。
SQLクエリの結果をレポートに保存して、カンバンに入れてデータを表示することをサポートすると同時に、カンバンで探索モジュールを利用してSQLレポートの動的パラメータをリアルタイムで修正することをサポートして、他のモデルと同様に条件を調整する能力を実現する。
# II。SQLクエリの場所と使用ロール
「行動分析」モジュールの下の「SQLクエリ」からアクセスできます
| 会社ハイパーチューブ | 管理者 | アナリスト | 一般メンバー | |
|---|---|---|---|---|
| SQLクエリ | ● | ● | △ | △ |
権限の説明:
●キャラクター必須
▲キャラクターはデフォルトであり、なくてもよい
△キャラクターはデフォルトではなく、あります
○役は必ずなし
なお、システムに付属するアナリストロールには「SQLクエリを使用する」権限はなく、使用する場合は、新しく作成したアナリスト以上の権限のロールにSQL使用権限を追加して、ユーザーに提供
# III。SQLクエリのページ概要
SQLクエリのページは、主に上半分の文作成ボックスと下半分のタブで構成され、タブページは4つのTABページに分けられ、それぞれ「テーブル構造」、「クエリ履歴」、「クエリ結果」と「文ブックマーク」タブ
# 3.1ステートメント作成ボックス

文作成ボックスの中核は文の入力ボックスで、入力ボックスにSQLクエリ文を作成するには、次の点に注意する必要があります
- フィールド名は二重引用符
""で囲んでください。デフォルトでも構いませんが、クエリフィールド名に特別な記号(例$、#)が付いている場合は、二重引用符 - 文字列は単一引用符で
''囲んでください - を使用でき
SELECT文とWITH句 - イベントテーブルをクエリするときは、パーティションキー
"$part_date"と"$part_event"データ時間とクエリイベントをフィルタリングして、クエリの効率 - リスト型の属性は、基礎となるストレージに文字列で格納され、
\t分割要素を使用して、リスト型に変換するには、コピー属性名機能(リスト属性のコピー内容にリストに変換する式が含まれている)を使用するか、関数split("属性名", chr(0009))分解する
カーソルが入力ボックスにある場合は、次のショートカットキーを使用できます
Ctrl+Enter:実行文Ctrl+Shift+F:書式設定文Ctrl+Z:取り消しCtrl+Y:回復
ステートメント作成ボックスのツールバーは入力ボックスの下にあります。ツールバーの左側にある[動的パラメーターの追加]ボタンをクリックして、ステートメントの最後に動的パラメーターを挿入できます。ツールバーの右側にあるICONは、左から右にそれぞれ次のようになります
- ヘルプ: SQLクエリのショートカットキーと関連するヘルプドキュメント
- 書式設定:クエリ文を書式設定します
- コピー文:入力ボックス内のクエリ文をクリップボードにコピー
- ブックマークの追加:クエリ文をブックマークとして保存し、その後のクエリや変更
- 計算:入力ボックス内のクエリ文
# 3.2タブページ
# 3.2.1テーブル構造
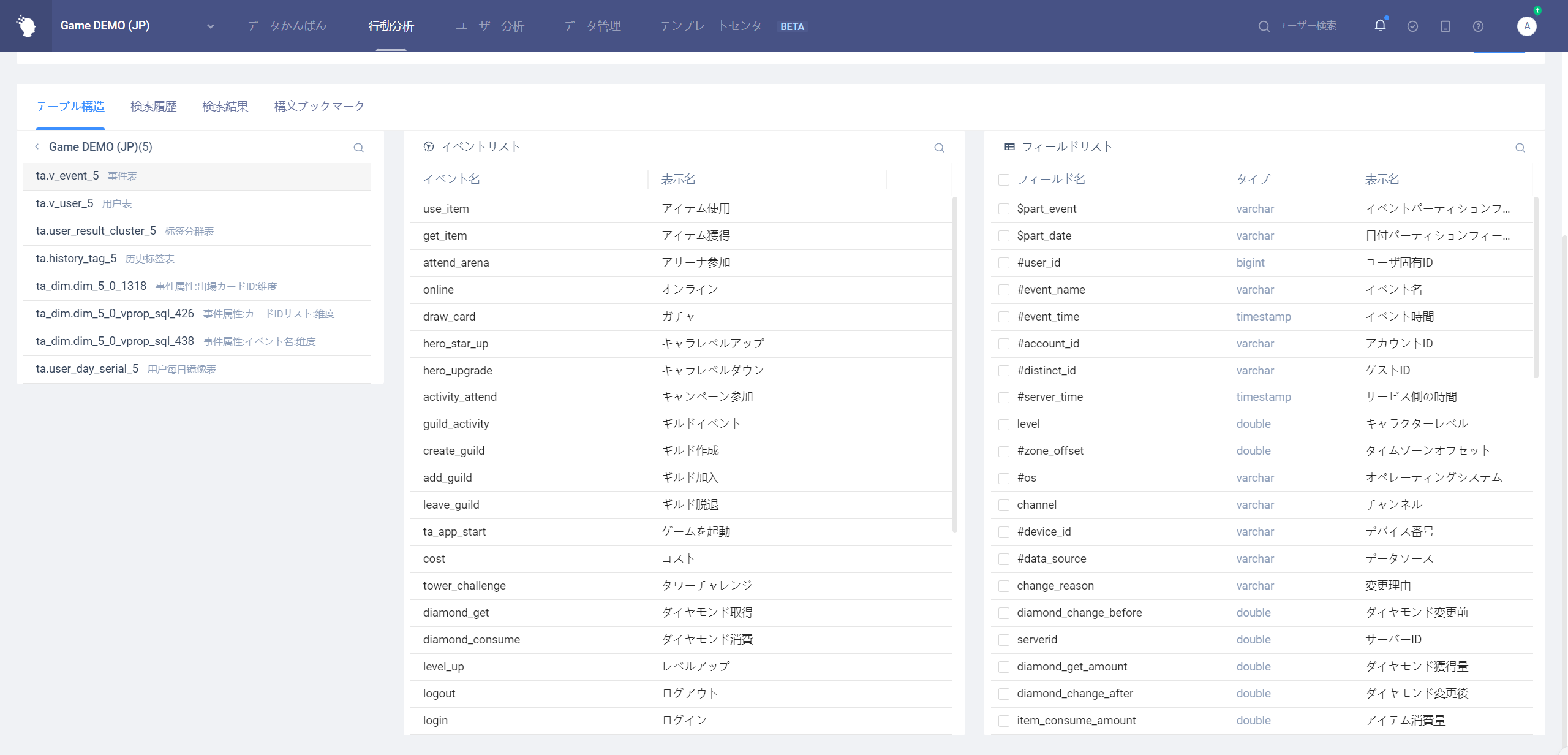
「テーブル構造」タブは主にデータテーブルの構造を
# 3.2.1.1データシートの概要
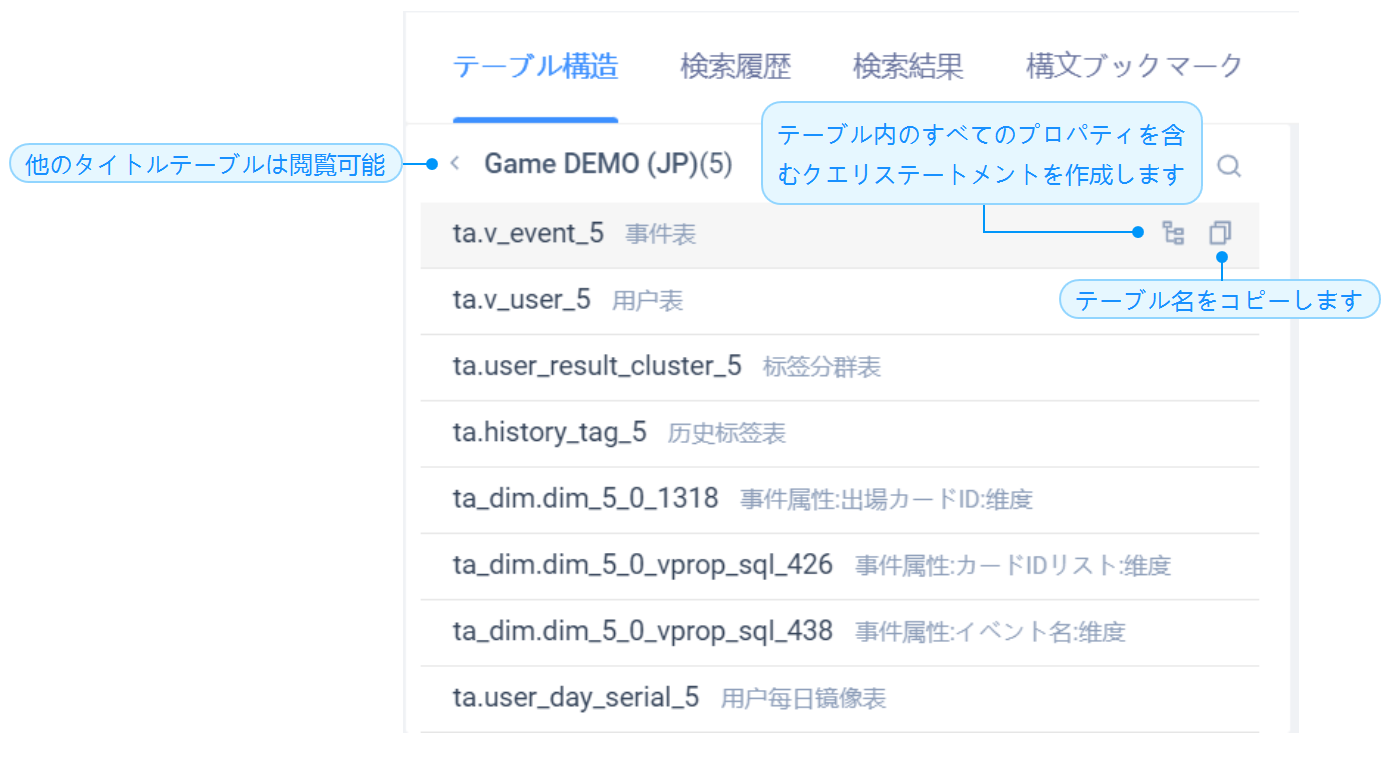
「テーブル構造」タブページの一番左側にあるのはデータテーブルの概要で、アクセス権のあるすべての項目のテーブルを見ることができ、概要の関連テーブルをクリックすると、タブページの右側にそのテーブルのフィールド情報
データシートの概要で表示およびクエリできるデータシートの種類は次のとおりです
- イベントテーブル
- ユーザーテーブル
- ディメンションテーブル
- グループラベルテーブル
- 暫定表(セクション4.4を参照)
- カスタムテーブル(二次開発ツールを使用して生成)
- ユーザーの毎日のミラーリングテーブル(TEスタッフに連絡して開く必要があります)
- Prestoに関連付けられている外部データソース(Presto Connectorsを使用して実装すると、TEスタッフに連絡して関連付け方法を確認できます)
概要の左上隅にある[戻る]ボタンをクリックすると、同じ「SQLクエリを使用する」権限を持つ他のプロジェクトのデータテーブルを表示し、クエリ
テーブルの「テーブル解析」ボタンをクリックすると、そのテーブルのすべてのフィールドを含むクエリ文が生成され、入力ボックスの末尾に改行して挿入されます。この文で、データテーブルの詳細データを迅速に入手し、テーブル構造を理解
「テーブル名をコピー」ボタンをクリックし、テーブル名をクリップボードにコピー
# 3.2.1.2フィールドリスト
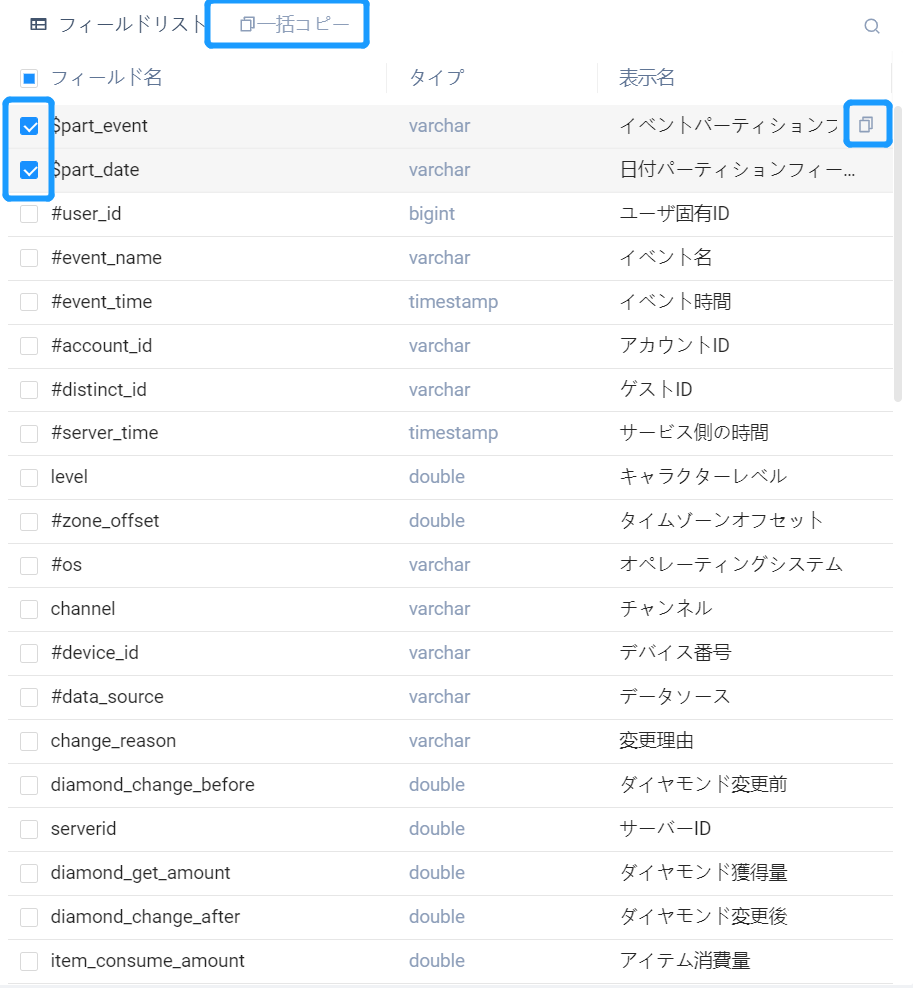
フィールドリストは、選択したテーブルのすべてのフィールドの情報を表示します(属性名、属性タイプ、属性中国語名
- フィールドの「コピー」ボタンをクリックすると、フィールドのフィールド名をコピーできます。フィールド名は二重引用符
「」囲まれ - フィールドの前のチェックボックスをクリックすると、複数のフィールドが選択され、複数のフィールドが一括コピーされ、各フィールドは二重引用符
""で囲まれ、フィールド間はカンマで、分割 - リストタイプのプロパティには、コピー時にフィールド(格納時のタイプは文字列)をリストに変換する式
# 3.2.1.3イベント一覧
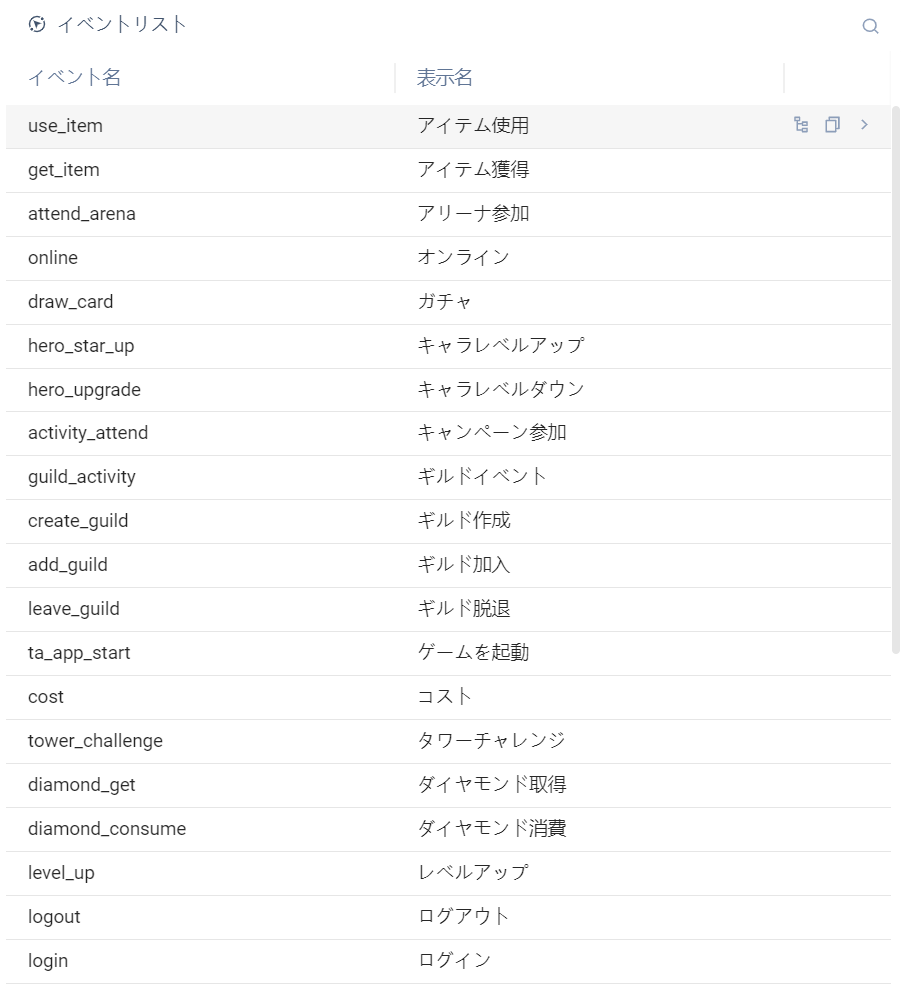
イベントリストは、イベントテーブルが選択されたときにのみ表示され、選択された項目のすべての表示状態の実際のイベント(仮想イベントを除く)が表示され、イベントデータを見るときには、このリストを使用してイベントの対応する属性情報を取得
- 「イベント解決」ボタンをクリックすると、そのイベントのすべてのフィールドを含むクエリ文が生成され、入力ボックスの末尾に改行して挿入されます。この文で、そのイベントの詳細データ
- 「イベント名をコピー」ボタンをクリックして、そのイベントのイベント名をクリップボードにコピー
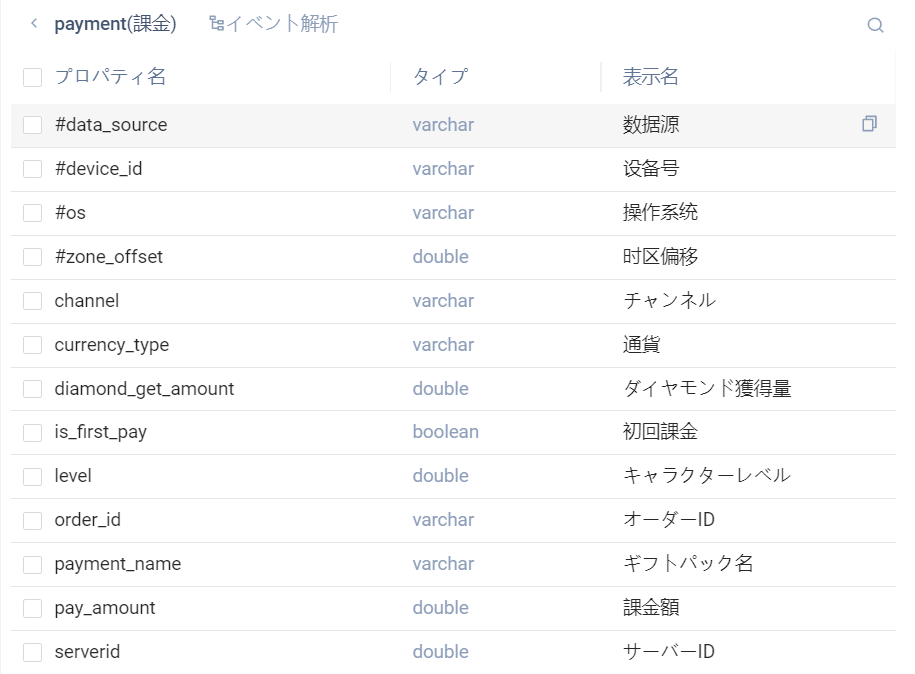
テーブル内のイベントがある行または行末の矢印をクリックすると、そのイベントのすべてのプロパティ
- 上部の「イベント解決」をクリックすると、そのイベントのすべてのフィールドを含むクエリ文
- フィールドの「コピー」ボタンをクリックすると、フィールドのフィールド名をコピーできます。フィールド名は二重引用符
「」囲まれ - フィールドの前のチェックボックスをクリックすると、複数のフィールドが選択され、複数のフィールドが一括コピーされ、各フィールドは二重引用符
""で囲まれ、フィールド間はカンマで、分割 - リストタイプのプロパティには、コピー時にフィールド(格納時のタイプは文字列)をリストに変換する式
# 3.2.1.4タググループリスト
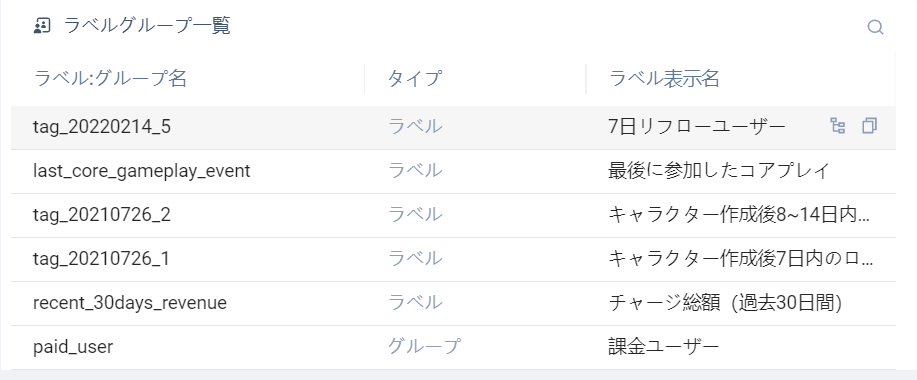
ラベルグループリストは、ラベルグループテーブルを選択したときにのみ表示され、選択した項目のすべてのラベルとグループが表示されます。ラベルグループリストから必要なラベルグループの情報を取得
- 「ラベルグループ解析」ボタンをクリックすると、ラベルまたはグループのクエリ文が生成され、入力ボックスの末尾に改行して挿入され、それに基づいて修正して、ラベルグループの関連クエリを完了
- 「ラベルサブグループ番号をコピー」ボタンをクリックすると、ラベルサブグループ番号
# 3.2.2問い合わせ履歴
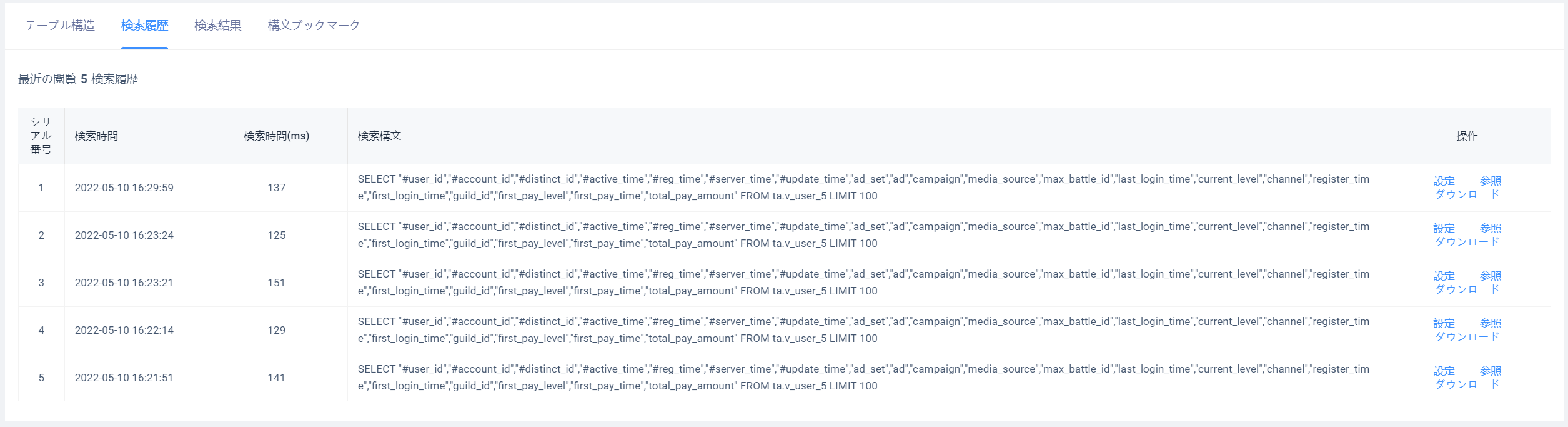
クエリ履歴タブには、実行したクエリ文が主に表示されます
- 「設定」をクリックすると、クエリの文が文入力ボックスの内容を
- 「クエリ」をクリックすると、クエリ結果にジャンプし、そのクエリの結果データ
- 「ダウンロード」をクリックすると、今回のクエリ結果の
. csv形式テキスト
[クエリ履歴]タブでは、すべてのプロジェクトで自分のSQLクエリ履歴のみが表示され、他人の履歴は表示されません。同時に、各ユーザーの約30日間の約100件の照会履歴しか記録されず、範囲を超えたものは定期的に空に
# 3.2.3問い合わせ結果
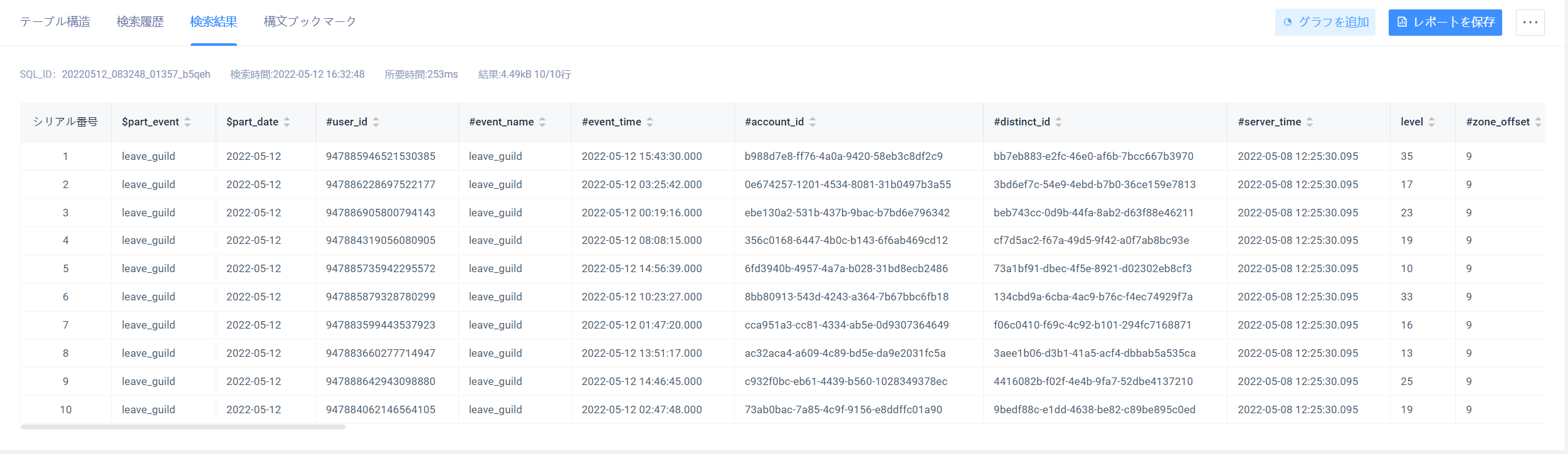
[クエリ結果]タブでは、前回のクエリの結果を表示するか、[クエリ履歴]ページで表示する履歴クエリ結果を選択します。このページでは、結果データをダウンロードしたり、結果をテンポラリテーブルに保存して後で使用することができます
- 「データをダウンロード」をクリックすると、今回のクエリ結果の
. csv形式テキスト - 「一時テーブルを保存」をクリックすると、今回のクエリの結果が一時テーブルとして保存されます。この一時テーブルは現在の項目、つまりページの左上に表示される項目に属します(一時テーブルは中国語の列名をサポートしていないことに注意してください)
- 「レポートを保存」をクリックすると、このクエリ文がレポートとして保存されます。このレポートは現在の項目、つまりページの左上に表示される項目に属します。具体的には4.3節
WARNING
なお、クエリ結果ページには最大で上位1000件のレコードしか表示されておらず、1000件を超えるレコードはダウンロード機能でローカルに降りてからクエリを行うことができ、ダウンロード機能が最大サポートする100万件のデータのダウンロード
# 3.2.4ステートメントブックマーク

ステートメントブックマークタブには、すでに保存されているすべてのステートメントブックマークが表示されます。ブックマークを更新するには、新しいブックマークを作成し、履歴ブックマークを削除することをお勧めします
- 「設定」をクリックすると、ブックマークの内容が置換文入力ボックスの内容
- 「名前を変更」をクリックすると、そのブックマークの名前を改名できます
- 「削除」をクリックすると、ブックマークは完全に削除されます
# 四、SQLクエリの使用シーン
# 4.1問い合わせデータ
ステートメント入力ボックスにSQLステートメントを作成し、ツールバーの右側にある[計算]ボタン、またはショートカットCtrl+Enter(入力ボックスにカーソルが必要)をクリックすると、データのクエリが実行されます。
この時点で行われたクエリは実際のクエリであり、キャッシュは読み込まれず、クエリは現在のリアルタイムデータです。
クエリをクリックすると、クエリの進捗バーが表示されます。このクエリをキャンセルしたい場合は、「計算をキャンセル」をクリックします。キャンセルされた計算は、「クエリ履歴」で再実行できます。
# 4.2動的パラメータ
動的パラメータは文の一部の内容を調整する能力を提供し、利用者はクエリのたびに修正が必要な部分を動的パラメータに設定し、クエリの際にパラメータを調整するだけで、文を修正する必要がなく、動的調整を実現できる。

上図では、クエリ時間とクエリデータのチャネルは動的パラメータに設定されており、計算のたびにパラメータリストでパラメータの値を変更するだけで、実行時にパラメータの対応部分の内容も同様に変更され、クエリ条件がこれらのパラメータの制御を受ける
動的パラメータの式規則はパラメータタイプ:パラメータ名}、文入力ボックスに直接式を入力するか、ツールバーで「動的パラメータの追加」をクリックして追加できます。
ステートメント内の同じ名前のパラメーターをパラメーターと見なし、使用中に複数のパラメーター変数を作成できます。
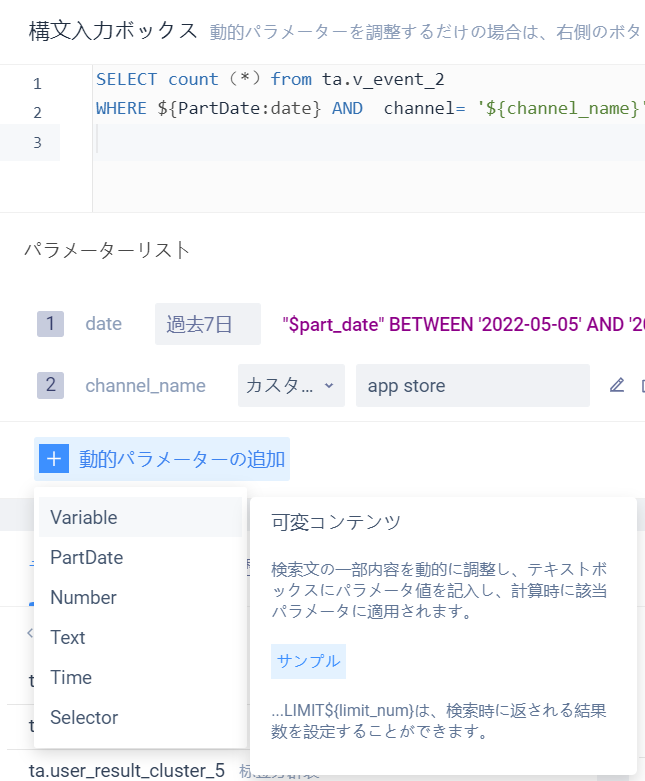
上図のパラメータ「クエリ時間」が文で複数回使用された場合、このパラメータの変更はすべての使用場所に適用されます。複数のテーブルの共同検査では、同じパラメータを複数回使用すると、各テーブルのフィルタリング条件をよく統一できます。
動的パラメータはレポートに保存でき、レポートには動的パラメータの情報が記録されます。パラメータのメモやエイリアスなど、カンバンの探索モジュールでは、閲覧者はこれらのパラメータを見て、動的な調整を行うことができます。
ステートメントで動的パラメーターが使用されている場合、レポートを保存すると、クエリのパラメーター値がパラメーターのデフォルトとして記録されます。動的パラメーターのタイプがイベント時間で、クエリ時に動的時間が選択されている場合、カンバンで表示するたびに動的に時間が変化します。
# 4.3レポートの保存
レポートを保存するには「クエリ結果」ページで行う必要があり、保存を要求するレポートが実行可能な文である必要があることに相当する。
レポートを保存する他のモデルと比較して、SQLクエリし次の図のように保存時に多くの設定を行うことができます
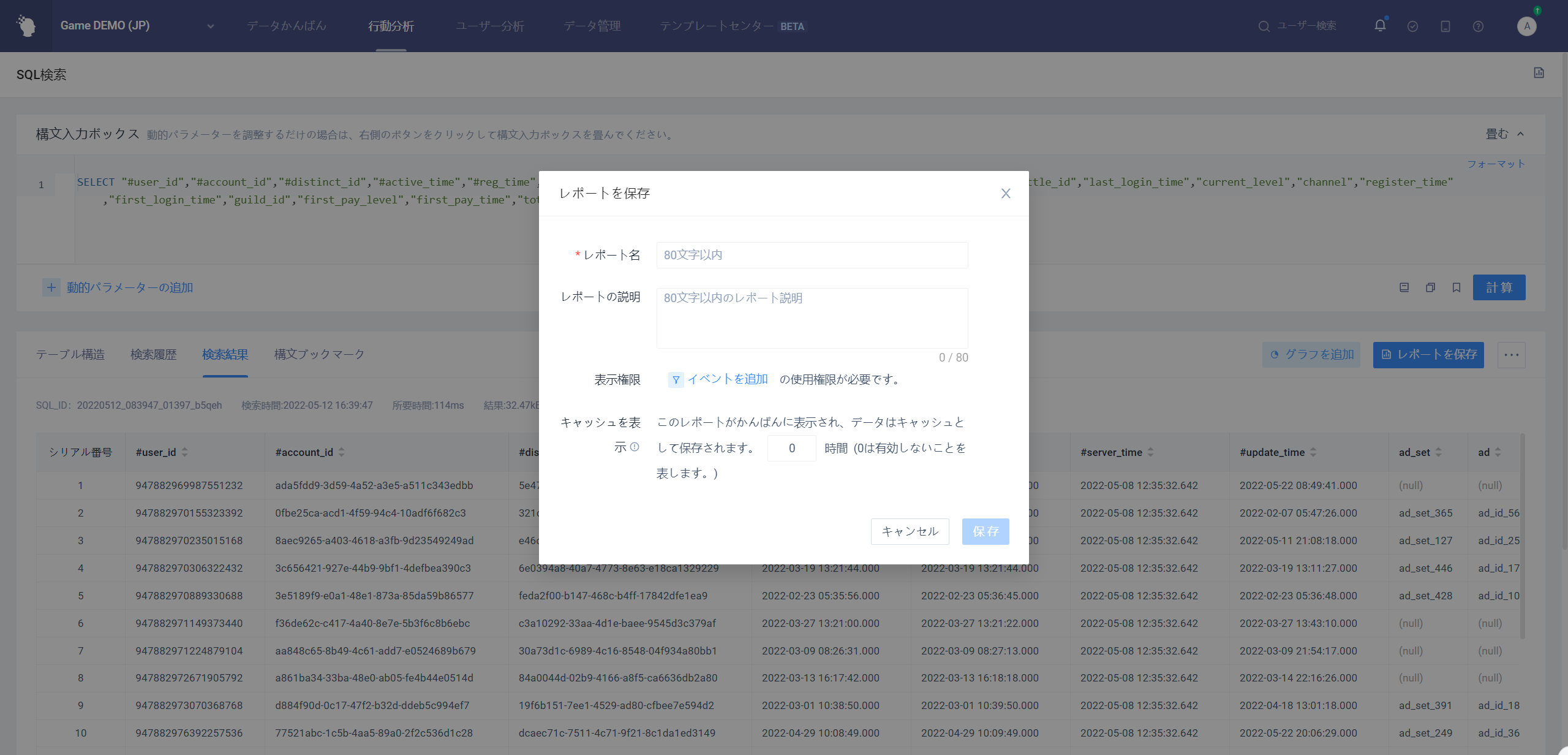
主な違いは、表示権限とカンバンキャッシュの設定が追加され
ビューの権限
表示権限は、レポートをカンバンで表示する権限を持つユーザーを制御します。カンバンでレポートを表示するには、すべての表示権限を満たす必要があり。
- イベント権限:SQLレポートは、デフォルトでメンバーのプロジェクト内のデータ権限によって制御されます。メンバーがイベントAの可視権限を持っていない場合、メンバーはイベントAに基づいて作成されたSQLレポートを表示できません。SQLレポートの保存時に、追加の権限制御の設定がサポートされています。つまり、共有された共有者に選択されたイベントを持つ権限(つまり、メンバーのイベント権限)が必要です。たとえば、ユーザーの支払い金額を照会する場合、追加追加追加で「支払い」イベントを要求する権限
- プロジェクト間権限:クエリ文に他のプロジェクトが(現在のプロジェクトに対して)現れた場合にのみ現れ、デフォルトはオン、つまりプロジェクト内メンバーこのレポートを見るには、レポートに関係するすべてのすべてプロジェクトのメンバー表示でき
カンバンキャッシュ
- カンバンキャッシュSQLレポートがカンバンに格納されているときに表示されるキャッシュが保持される時間で、カンバンキャッシュを設定することで、スローSQLレポートと非リアルタイムレポートのクエリ頻度を減らし、クラスターコンピューティングリソース
- カンバンキャッシュが設定されている場合(0を超えると設定されている場合)、クエリ時間が300秒未満の場合でも、レポートは手動で更新でき、更新後に新しいデータのキャッシュ時間が再計算
- カンバンタイミングリフレッシュは、すべてのSQLレポートに対して有効で、レポートのクエリ時間とレポートにキャッシュが設定されているかどうかに関係なく、カンバンタイミングリフレッシュ時に同期的にリフレッシュされます
- レポートを保存するときのクエリが300秒を超えると、カンバンキャッシュを設定しなければならず、同時に手動で更新できず(カンバンタイミング更新はまだ有効)、そのレポートの探索モジュールに入ることができず、クエリ文を最適化し、クエリ範囲を狭めてクエリを高速化して制限を受けないようにすることをお勧めします。
他のモデルのレポートと同様に、作成されたSQLクエリレポートは「レポート」インターフェイスで表示できます。
# 4.4暫定表
WARNING
より前に作成された一時テーブルは、個人にのみ有効であるため、レポートでは使用できません。私たちは新しいバージョンのプロジェクト一時表に変換し、個人一時表の後の「変換」ボタンをクリックして変換
クエリ結果ページで、結果データストアをテンポラリテーブルとして作成できます。格納されたテンポラリテーブルは、現在のアイテム、つまりページの左上隅で識別されるアイテムに関連付けられます。作成されたテンポラリテーブルは、そのアイテムのSQLクエリ権限を持つ他のユーザーが使用でき
一時テーブルを削除する必要がある場合は、データテーブルの概要で一時テーブルを選択し、その後の「一時テーブルを削除」ボタンをクリックして削除
# V. Presto SQLの特殊な使用法と高度な関数
この章では、Presto SQLの特殊な使用法と、より高度な関数の使用法を紹介します。Presto SQLの詳細を知りたい場合は、PrestoPrestoの公式ドキュメント (opens new window)
# 5.1 try関数とtry_cast関数
try(expression)
try関数は式の例外を返し、例外値をNULLに返しますtry関数を使用しないと、文に例外が発生した場合にエラーが発生し、クエリが失敗します。
を使用してcoalesce関数を使用してNULL値を置き換えることもできます。たとえば、フィールドa整数に変換し、変換に失敗した場合は0に変換
coalesce(try(cast("a" as integer)), 0)
以上のタイプ変換はtry_cast関数を使って実現でき、try_castの役割はcast関数と一致し、すべて値をタイプ変換する。違いはtry_castはタイプ変換エラー時にNULLを返し、クエリ失敗を避けることである。
coalesce(try_cast("a" as integer), 0)
# 5.2時刻/日付関数
を使用current_date,current_time,current_timestamp,localtimeandlocaltimestampは括弧なし、Prestoも括弧なしの書き方をサポート
# 5.2.1文字列と時間の変換
の前に直接キーワードtimestampなどのtimestamp''など、対応する時間を
date_parseとdate_formatはそれぞれ文字列遷移時間と時間遷移文字列で、使用法はすべて着信変換が必要なフィールドと対応するformatで、以下は文字列$part_date遷移時間と時間#event_time遷移文字列:
date_parse("$part_date", '%Y-%m-%d')
date_format("#event_time", '%Y-%m-%d %T')
上記の関数のformat形式はMySQLの形式を使用し、JAVA形式を使用する場合は関数ととparse_datetime
# 5.2.2時間計算関数
関数date_addは時間をオフセットし、unitは単位、valueはオフセットで、valueが負の場合は前方オフセット
date_add(unit, value, timestamp)
関数date_diffは、2つの時間の差を計算するために使用され、アルゴリズムはtimestamp2-timestamp1で、単位はunitの整数
date_diff(unit, timestamp1, timestamp2)
2つの関数のunitの値の範囲は、以下の表
| ユニット | 説明 |
|---|---|
| ミリ秒 | ミリ秒 |
| 第二 | 秒 |
| 1分 | 分です |
| 1時間 | 時間です |
| 一日 | 日 |
| 1週間 | 週間 |
| 月 | 月 |
| クォーター | 四半期ごと |
| 年 | 年 |
# 5.3窓開け関数
Prestoはウィンドウ関数をサポートしています。first_valueやlast_valueなど、いくつかの非常に実用的な関数は、最初または最後に何かをしたときの値を計算するのに適しています。
例えば、各ユーザーが初めて商品を購入する行為をしたときに購入した商品を計算します
SELECT user_id,first_purchase_product FROM
(SELECT user_id,first_value(product_name) over(partition by user_id order by time) AS first_purchase_product FROM log.purchase)
GROUP BY user_id,first_purchase_product
first_valueとlast_valueと組み合わせてover句と組み合わせてover句のpartition byに似groupbyにいます。つまり、order byはソートするフィールドを決定します。
# 5.4 JSON解析
いくつかの特殊なシナリオでは、複雑なデータ構造を文字列で記録し、バックグラウンドにアップロードすることをお勧めします。その後の使用では、JSON解析関数を使用してSQLで使用できるデータを変換または抽出
# 5.4.1文字列からJSONへ
json_parseは、JSON形式に準拠した文字列をSQLのJSON型データに変換できます。
json_parse(JSON '{"abc":[1, 2, 3]}')
# 5.4.2 JSONターン他のタイプ
JSONに変換されたデータは、CAST他のSQLタイプのデータに変換できます。たとえば、JSONに変換されたばかりの文字列を再びMAPに変換します
CAST(json_parse('{"abc":[1, 2, 3]}') AS MAP(varchar,array(integer)))
文字列をJSONに再変換する場合は、json_formatを使用できます:
json_format(json_parse('{"abc":[1, 2, 3]}'))
# 5.4.3 JSONデータの直接抽出
多くの場合、JSONの一部のデータを抽出するだけでよく、このときjson_extract_scalarを使用して抽出し、文字列を返します
json_extract_scalar(json, json_path)
そしてjson_extract_scalarはJSONの文字列を直接抽出でき、手動でJSONタイプに変換する必要はなく、例えば以下、abcabcの最初の要素を抽出
json_extract_scalar('{"abc":[1, 2, 3]}','$.abc[0]')
# VI。ベストプラクティス
# 6.1補完他モデル
モデルの制限のため、一部の分析シナリオは実装上、表示要求やソート要求などの要求を完全に満たすことができない。この場合、SQLクエリを使用して完全なカスタマイズを行うことができる。
たとえば、最近の有料ランキングでは、モデルでカスタム並べ替えがサポートされていないため、SQLクエリを使用して並べ替えを実装できます
SELECT
"#account_id"
, sum("recharge_value") "Total_Payment"
FROM
ta.v_event_2
WHERE ("$part_event" = 'recharge' AND ${PartDate:date1} )
GROUP BY "#account_id"
ORDER BY sum("recharge_value") ASC
# 6.2プロジェクト間のデータ集計
他のモデルはプロジェクトによって厳密に管理されているため、プロジェクト間のデータクエリまたはデータ集計はSQLクエリでのみ実行できます。
比較的よく見られるシナリオは、異なるアプリケーション、業務、地域のデータが異なるプロジェクトに保管されていることで、これらのデータをまとめて見たい場合、SQLクエリを使用すると便利に実現できる。
以下はプロジェクトID 1とプロジェクトID 2のデータを共同で照会するケースで、集約プロジェクトでは以下の文をレポートとして保存し、カンバンに入れて分析すると、プロジェクト間のデータ集約が実現できる
SELECT a."$part_date","Product_A_DAU","Product_B_DAU" FROM
(SELECT "$part_date",count(*) AS "Product_A_DAU" FROM ta.v_event_1 WHERE ${PartDate:date1} GROUP BY "$part_date") a
JOIN
(SELECT "$part_date",count(*) AS "Product_B_DAU" FROM ta.v_event_2 WHERE ${PartDate:date1} GROUP BY "$part_date") b
ON a."$part_date" = b."$part_date" ORDER BY a."$part_date" ASC
ケースでは、動的パラメータ${PartDate: date1}2か所で使用され、両方のテーブルのクエリ時間を同時に制御し、計算サイクルを統一することに相当します。これは、プロジェクト間のクエリでよく使用される方法です。
# 6.3複雑なデータ構造の利用
場合によっては、MapやJSONなどの複雑なデータ構造を後続の分析で使用する必要があります。この場合、これらの複雑なデータ構造を文字列で記録し、SQLクエリで利用することをお勧めします。
次のケースは複雑な構造属性hero_jsonの解析で、その中のhero_idとhero_levelを抽出して、後続の分析を実現する
SELECT
json_extract_scalar(hero_json, '$.hero_id') hero_id
, json_extract_scalar(hero_json, '$.hero_level') hero_level
FROM
ta.v_event_2
WHERE ("$part_event" = 'fight_success' AND ${PartDate:date} )