# Data Rules
This section details the data structure, data types and data constraints of the TA background. Through this section, you will learn how to construct data that conforms to the rules and investigate data transmission issues.
If you are using LogBus or RESTful API to upload data, you need to format the data according to the data rules in this section.
# I. Data Structure
The TA background accepts JSON data that meets the rules: if SDK access is used, the data will be converted into JSON data for transmission. If data is uploaded using LogBus or POST methods, the data needs to be regular JSON data.
JSON data is in units of behavior: that is, a row of JSON data corresponds to a piece of data in the physical sense. In the data sense, it corresponds to the user generating a behavior or setting a user feature.
The data format and requirements are as follows (for convenience of reading, the data is typeset, please do not wrap in real environment):
- The following is a sample of event data:
{
"#account_id": "ABCDEFG-123-abc",
"#distinct_id": "F53A58ED-E5DA-4F18-B082-7E1228746E88",
"#type": "track",
"#ip": "192.168.171.111",
"#uuid": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"#time": "2017-12-18 14:37:28.527",
"#event_name": "test",
"properties": {
"argString": "abc",
"argNum": 123,
"argBool": true
}
}
- The following is a sample user feature setting:
{
"#account_id": "ABCDEFG-123-abc",
"#distinct_id": "F53A58ED-E5DA-4F18-B082-7E1228746E88",
"#type": "user_set",
"#uuid": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"#time": "2017-12-18 14:37:28.527",
"properties": {
"userArgString": "abc",
"userArgNum": 123,
"userArgBool": true
}
}
The value of "#type" can be replaced with "user_setOnce", "user_add", "user_unset", "user_append", "user_del"
Structurally and functionally, a piece of JSON data can be divided into two parts:
Other fields in the same layer of properties constitute the basic information of this piece of data, including only the following items:
- Represents the account ID of the triggering user
#account_idand guest ID#distinct_id - Represents trigger time
#time, accurate to seconds or milliseconds - Represents the data type (event or user feature setting)
#type - Represents
#event_nameof event type (only with event data) - Represents user IP
#ip - Represents data uniqueness
#uuid
Note that in addition to the above items, the rest of the properties beginning with "#" need to be placed in the inner layer of properties.
The inner layer of properties is the content of the piece of data, that is, the attributes in the event, or the user features that need to be set, which are directly used as attributes or analysis objects during background analysis.
From a structural point of view, these two parts are somewhat similar to the header and content, and the meaning of each field in these two parts will be described in detail later.
# 1.1 Data Information Part
The red box in the figure below identifies that several fields on the same layer as 'properties' constitute the information part of the piece of data:
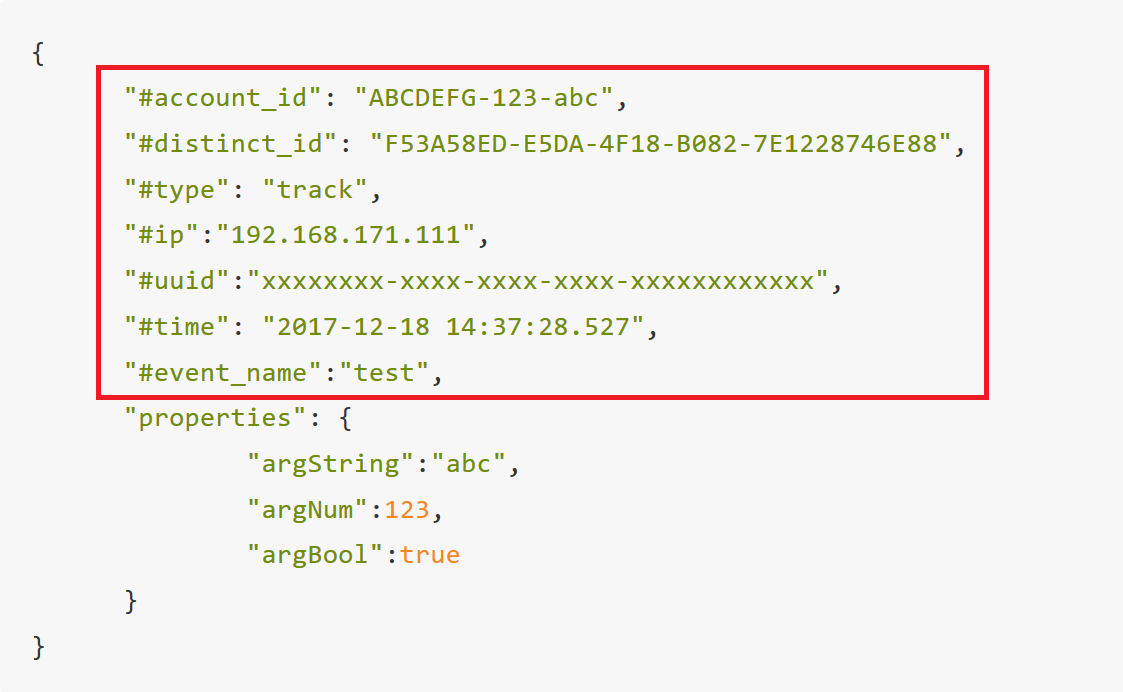
These fields contain data information such as the trigger user and trigger time of this data. Their characteristic is that all fields begin with "#". This section will sort out the meaning of each field and how to configure it.
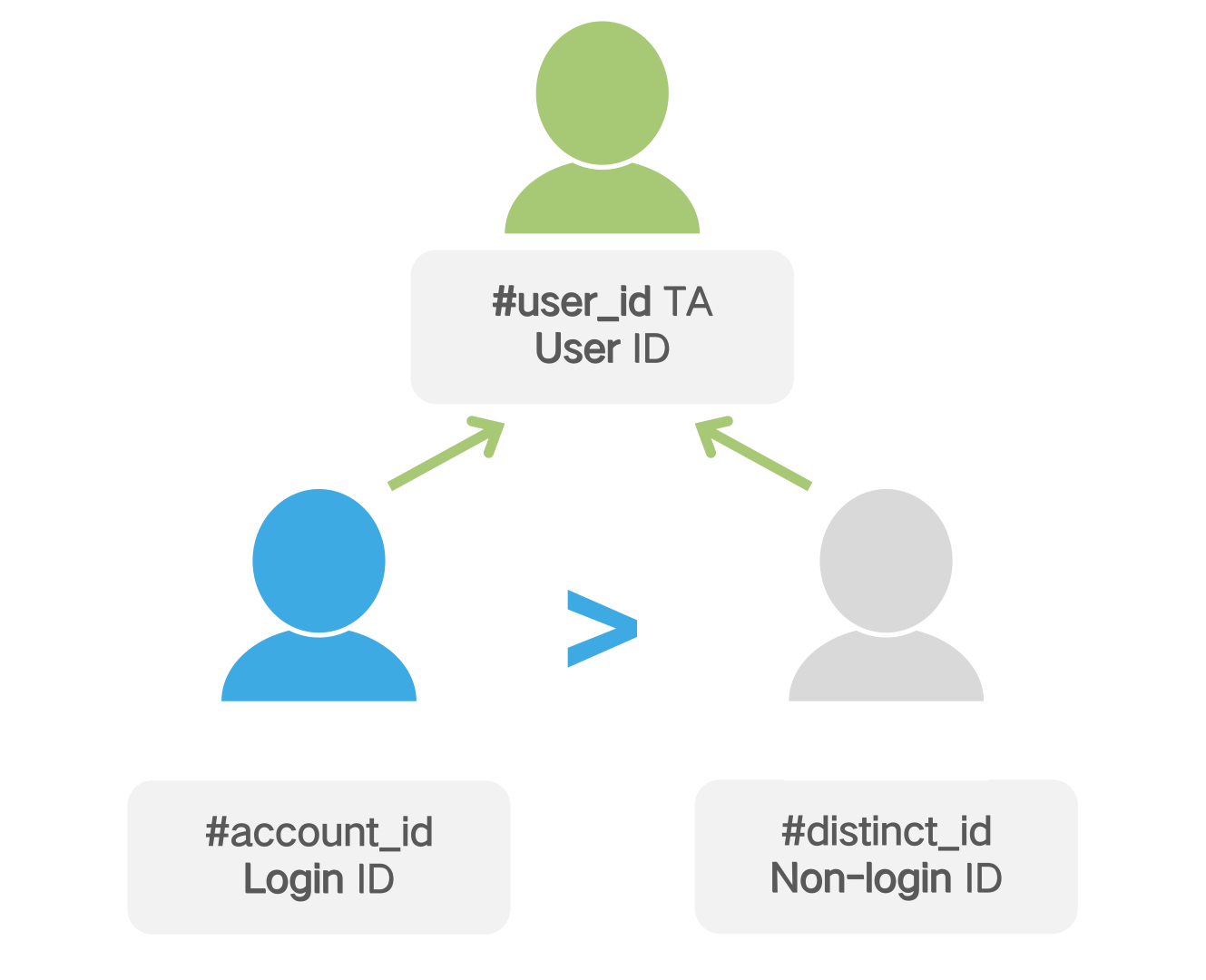
# 1.1.1 User Information ( #account_id and #distinct_id )
#account_idand #distinct_id is used to identify the user's two fields, wherein #account_idis the user's ID in the login state, #distinct_idthe user is not logged in state identification, TA will be based on the two fields to determine the behavior of the user trigger, which is preferentially determined according to #account_id, specific rules see user identification rules chapter.
#account_idand #distinct_idAt least one must be passed in. If all events are triggered when the user is logged in, it is feasible to pass in only #account_id. If there are events that are triggered when the user is not logged in (including before registration), it is recommended to fill in both fields.
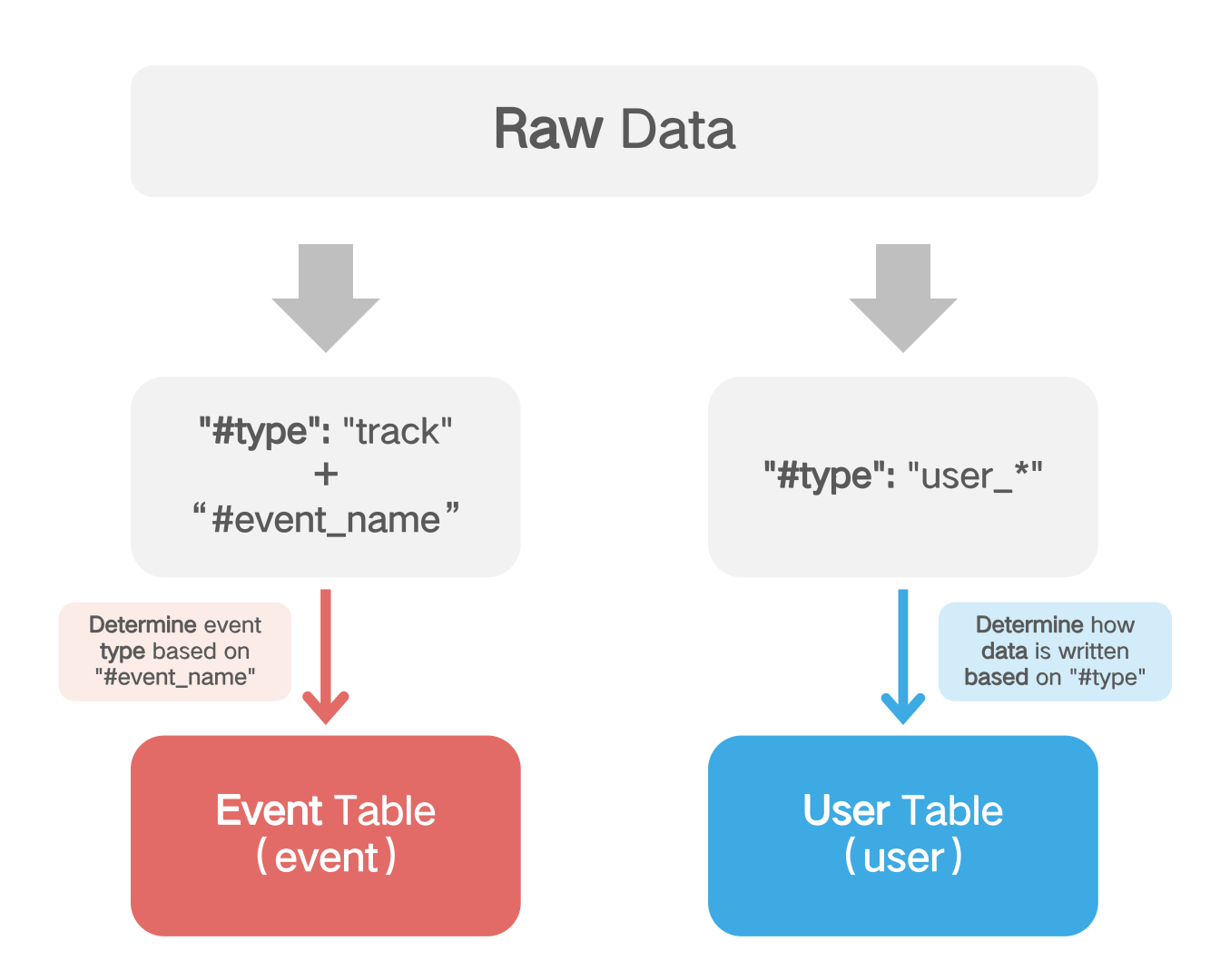
# 1.1.2 Data Type Information ( #type and #event_name )
#Typedetermines the type of data, whether it is the user's behavior record or the operation processing of modifying user features. **Each piece of data needs to be configured with **the #type**field **. #Typevalues are divided into two categories. Trackmeans that this data is a user behavior record, and the beginning of user_means to operate on user features. The specific meaning is as follows:
- Track: An event is passed to the event table, and all events uploaded as tracks.
- user_set: Operate on a user table to overwrite one or more user attributes and overwrite previous values if the attributes already have values.
- user_setOnce: Operate on the user table to initialize one or more user attributes and ignore this operation if the attributes already have values.
- user_add: Operate on user tables to accumulate one or more numeric user attributes.
- user_unset: Operate on the user table and empty the attribute values of one or more user attributes for that user.
- user_del: Delete the user by operating on the user table.
- user_append: Operate on the user table by adding elements to the user's list type attribute values.
When the value of #typeis track, that is, when the data is a behavior record, **the name of the event must be configured **#event_name, must start with a letter, and can only contain: letters ( case sensitive ) , numbers, and underscore "_", with a maximum length of 50 characters. Please be careful not to configure with spaces. If this data is an operation to modify user features, the #event_namefield is not required.
It should be noted that the user feature is a user attribute with node significance. It is not recommended to make frequent modifications in a short period of time. For attributes that need to be changed frequently, it is recommended to put them in events as event attributes.
# 1.1.3 Trigger Time ( #time )
#Timeis the time when the event is generated, which **must be configured **, and the format must be accurate to milliseconds ("yyyy-MM-dd HH: mm: ss. SSS ") or second (" yyyy-MM-dd HH: mm: ss ") string.
Although the operation data for the user table also needs to be configured with #time, the operation for the user feature will operate in the order in which the data is received in the background.
For example, if the user retransmits the User table operation data from the past day, both the overwriting and initialization of the attribute will proceed as usual, and will not be judged according to the #time field
# 1.1.4 Trigger Location ( #ip )
#Ipis the IP address of the device, optional configuration, TA will calculate the user's geographic location information based on the IP address, if you pass in the 'properties' #country, #province, #city and other geographic location attributes, it will be based on the value you passed.
# 1.1.5 Data Unique ID ( #uuid )
#Uuidis used to indicate the uniqueness of the data field, optional configuration, the format must be the standard format of uuid. TA will check whether the same #uuiddata (i.e. duplicate data) appears in a short period of time at the receiving end according to the amount of data, and the duplicate data will be directly discarded and no longer stored.
**It should be noted that the receiving end check performed by **#uuidwill only check the data received in recent hours, mainly to solve the problem of network jitter caused by short-term data duplication, the received data can not be checked with the full amount of data. If you need to deduplicate the data, please contact the TA staff.
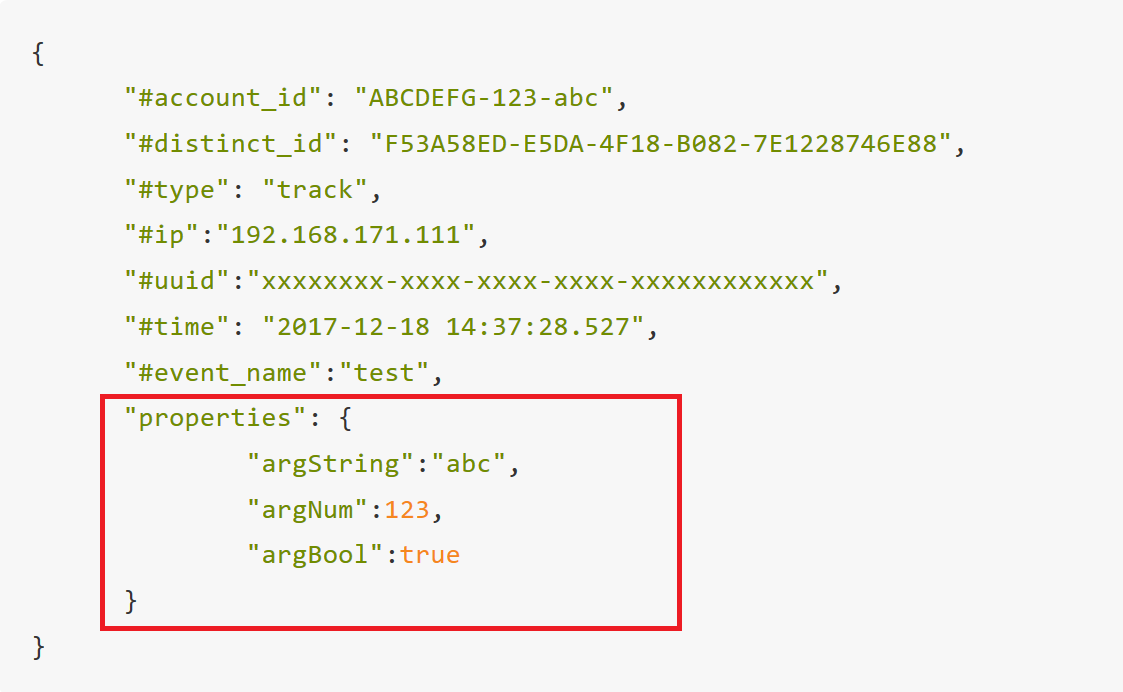
# 1.2 Data Principal Part
The other part of the data is the data contained in the inner layer of properties. Propertiesis a JSON object, and the data inside is represented as a key value pair. If it is user behavior data, it represents the attributes and indicators of the behavior (equivalent to fields in the behavior table). These attributes and indicators can be directly used in analysis. If it is the operation processing of user feature, it represents the attribute content that needs to be set.
The key value is the name of the attribute. The type is string. The custom attribute must start with a letter and can only contain: letters (ignoring case) , numbers, and underscores "_", and the maximum length can only be 50 characters; There are also TA preset attributes starting with #. You can learn more in the chapter on Preset Attributes , but it should be noted that in most cases, only custom is recommended the property does not use #.
The Value is the value of the attribute and can be a numeric value, text, time, Boolean, list, object, object group. The data type is represented in the following table:
| TA data type | Sample value | Value selection description | Data type |
|---|---|---|---|
| Value | 123,1.23 | The data range is -9E15 to 9E15 | Number |
| Text | "ABC", "Shanghai" | The default limit for characters is 2KB | String |
| Time | "2019-01-01 00:00:00","2019-01-01 00:00:00.000" | "Yyyy-MM-dd HH: mm: ss. SSS" or "yyyy-MM-dd HH: mm: ss", if you want to indicate the date, you can use "yyyy-MM-dd 00:00:00" | String |
| Boolean | true,false | - | Boolean |
| List | ["a","1","true"] | All elements in the list will be converted to string type , up to 500 elements in the list | Array(String) |
| Object | {hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False} | Each child attribute (Key) in the object has its own data type. For value selection description, please refer to the general attributes of the corresponding type above Up to 100 child attributes within the object | Object |
| Object group | [{hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False}, {hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False}] | Each child attribute (Key) in the object group has its own data type. For value selection description, please refer to the general attributes of the corresponding type above Up to 500 objects in the object group | Array(Object) |
It is important to note that the type of all attributes will be determined by the type of value received for the first time. Subsequent data must be of the same type as the corresponding attributes. Attributes that do not match the type will be discarded (the remaining type-compliant attributes of that data will be retained) and TA will not make type compatible conversions.
# II. Rules for Data Processing
After the TA server receives the data, it does some processing. This section will combine the actual usage scenarios, TA processing rules:
# 2.1 Receive New Event Data
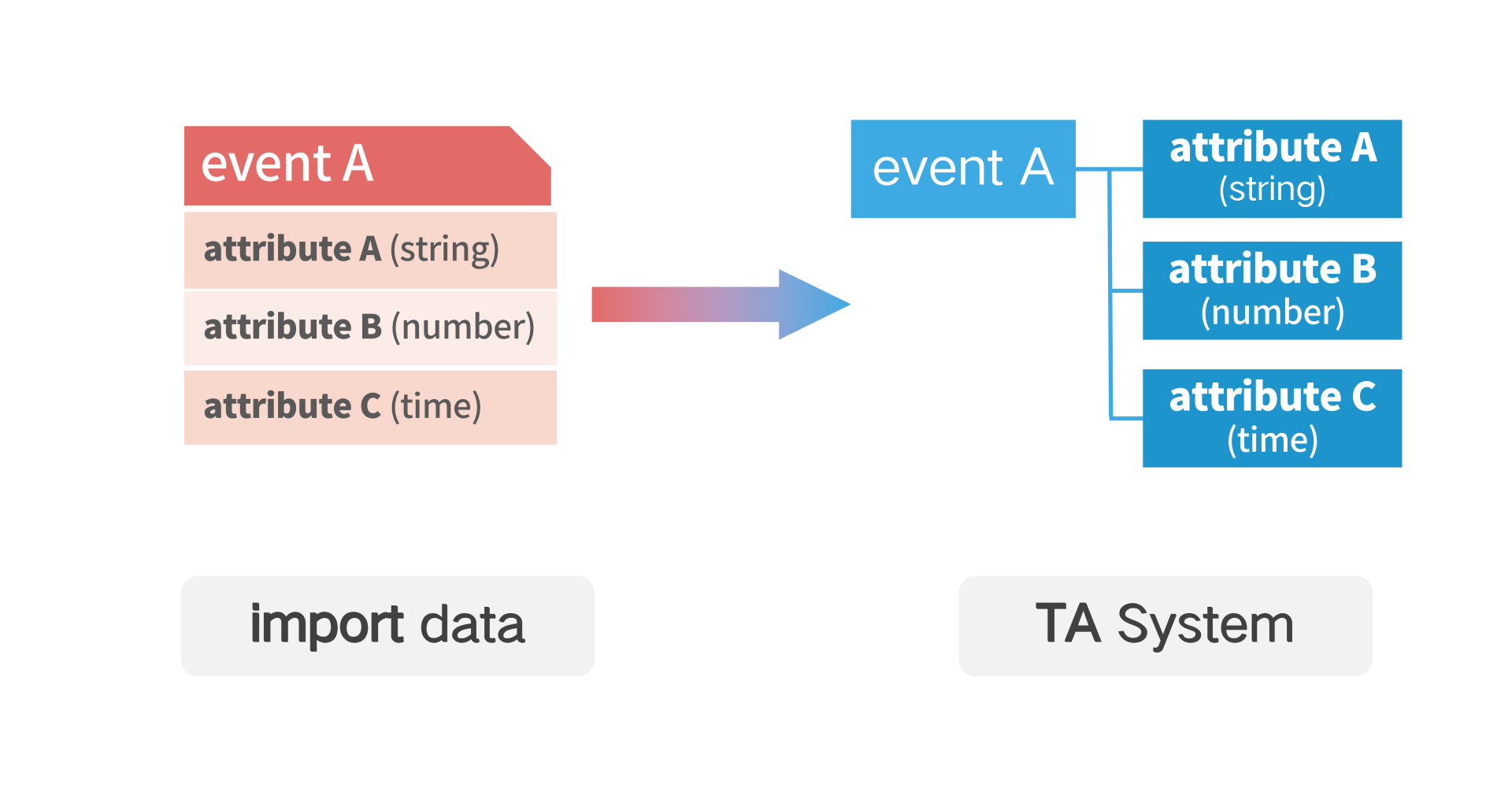
If attributes need to be added to an existing event, simply pass in the new attributes together when uploading data, and the TA will dynamically associate the event with the new attributes without additional configuration.
# 2.2 Add Event Attributes
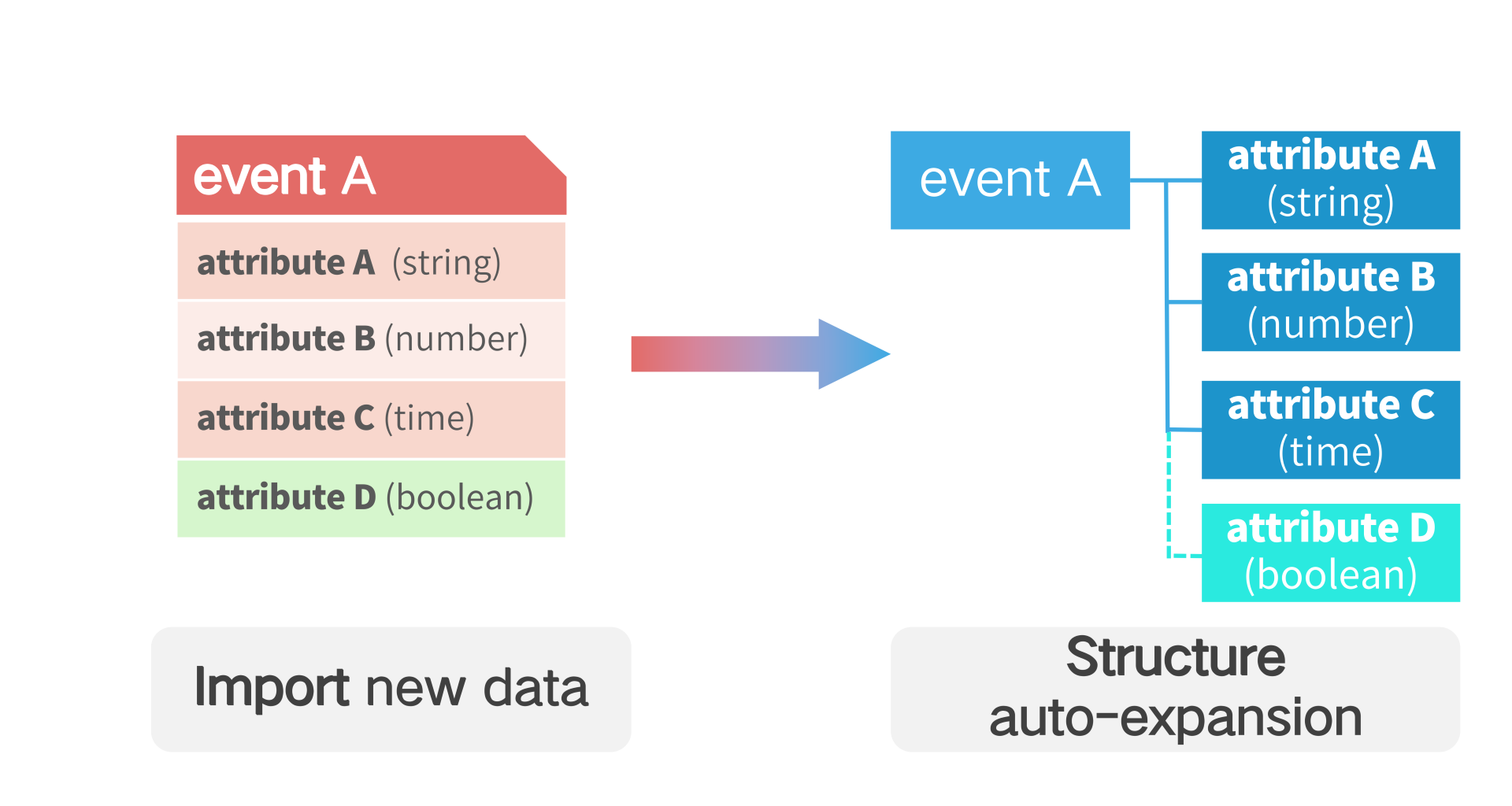
If you need to add attributes to an existing event, simply pass in the new attributes when you upload the data, and the TA will dynamically associate the events with the new attributes without any additional configuration.
# 2.3 Handle Inconsistent Attributes
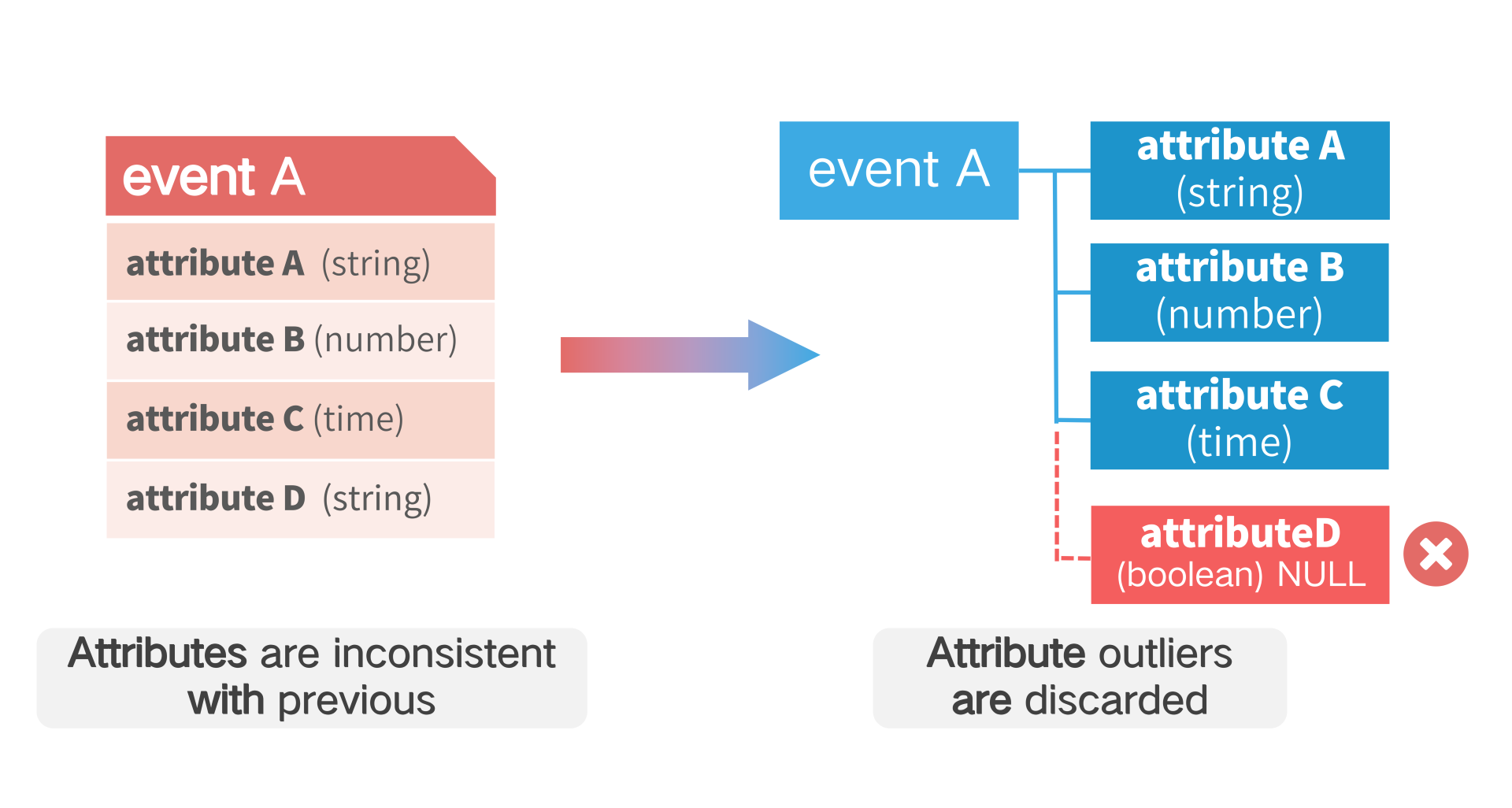
When an event data is received where the type of an attribute does not match the type of the attribute already in the background, the value of the attribute is discarded (i.e. null).
# 2.4 Abandonment Event Attributes
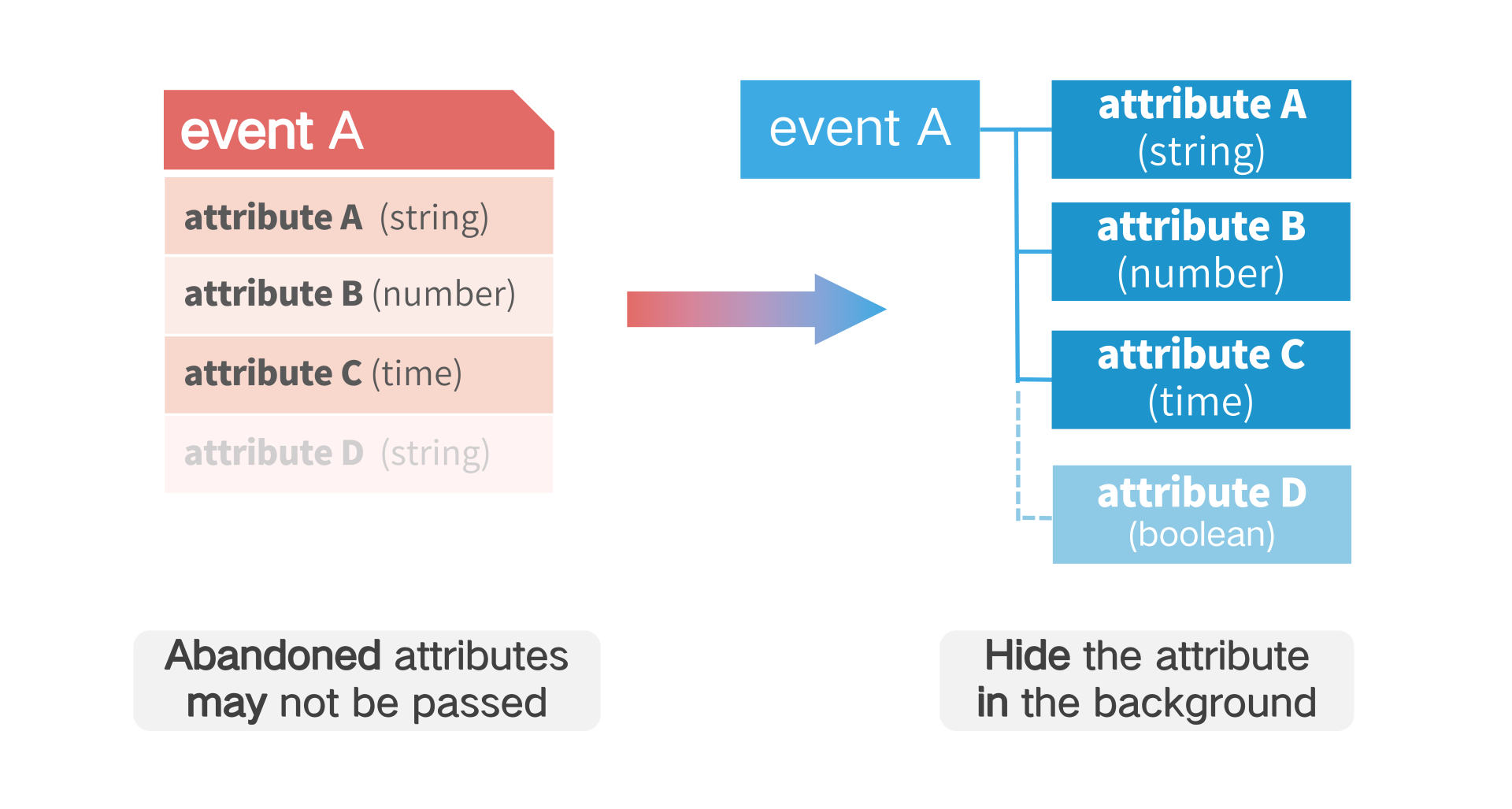
If an attribute of an event needs to be discarded, it only needs to be hidden in the metadata management of the TA, and the subsequent data transmission can not transfer the attribute. The TA does not delete the data of the attribute, and the hiding operation is reversible. If the attribute is transferred after the attribute is hidden, the value of the attribute will still be retained.
# 2.5 Multi-event Common Attributes
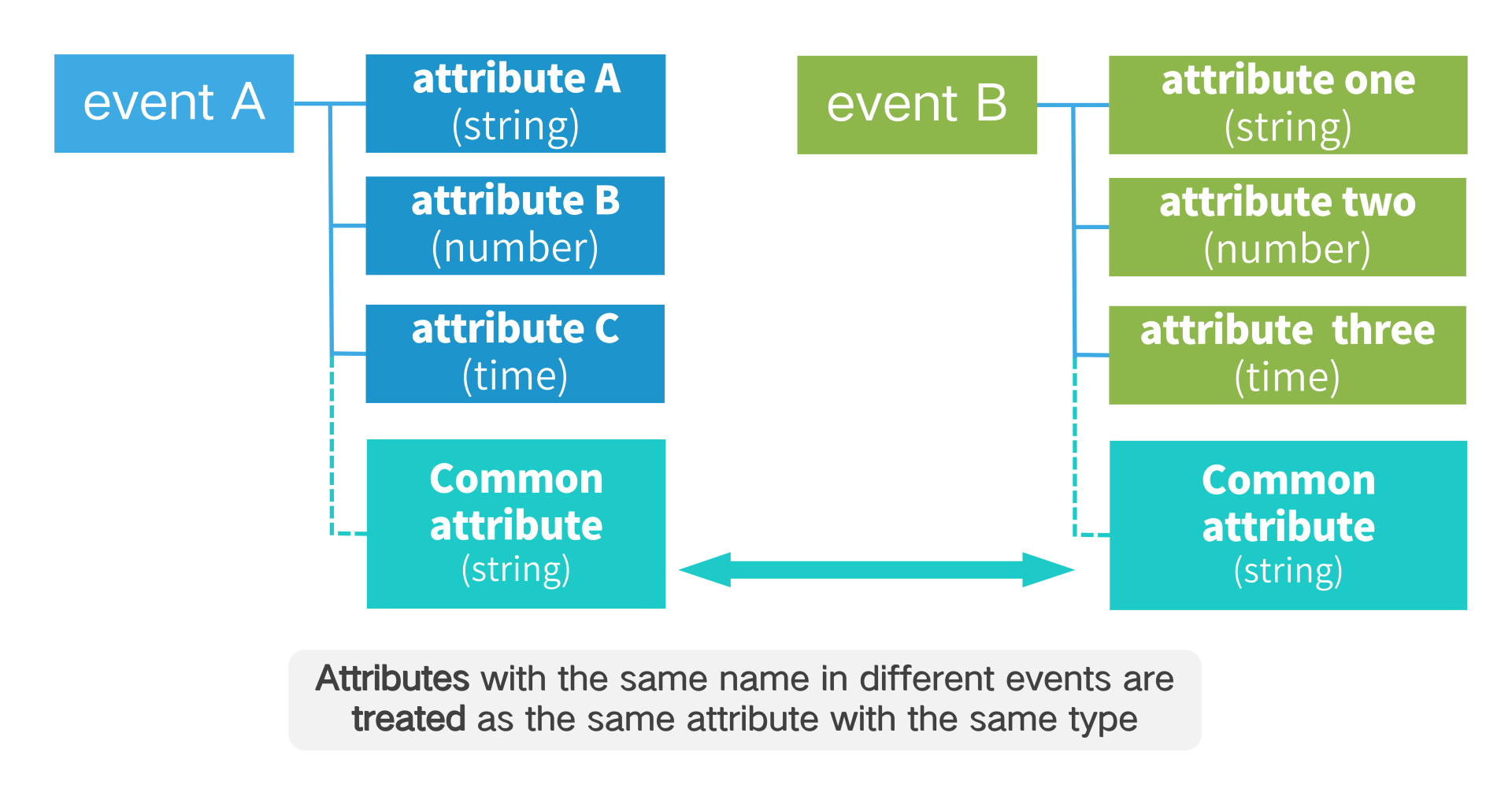
The same-name attributes of different events are considered to be the same attributes and have the same type, so it is necessary to ensure that all the same-name attributes have the same type in order to avoid discarding the value of the attributes due to the different types.
# 2.6 User Table Operation Logic
Modify the user's data in the user table, that is, the #typefield in the reported data is user_set, user_setOnce,, user_add, user_unset,, user_appendor user_delThe data can be regarded as an instruction in essence, that is, the user's user table data referred to in the piece of data is operated. The type of operation is determined by the #typefield, and the content of the operation is determined by the attributes in the properties.
The following is the specific logic of the main user table attribute operations:
# 2.6.1 Override User Features (user_set)
According to the user ID in the data to determine the operation of the user, and then according to the properties in the properties, covering all properties, if a property does not exist, the new property.
# 2.6.2 Initializing User Features (user_setOnce)
According to the user ID in the data to determine the user to operate, and then according to the attributes in the properties, the unassigned (empty) attributes are set. If a property that needs to be set by the user already has a value, it will not be overwritten. If a property does not exist, create the new property.
# 2.6.3 Accumulating User Features (user_add)
Determine the user to operate according to the user ID in the data, and then accumulate the numeric attributes according to the attributes in the properties. If the incoming negative value is equivalent to the original attribute value minus the incoming value, if the user needs to set a property Not assigned (empty), the default setting will be 0 before the accumulation operation, and if the property does not exist, the new property will be created.
# 2.6.4 Clear User Feature Values (user_unset)
According to the user ID in the data, determine the user to operate, and then according to the properties in the properties, empty all the properties (i.e. set to NULL). If a property does not exist, the property **will not be **created.
# 2.6.5 Add Elements of List User Features (user_append)
Determine the user to operate according to the user ID in the data, and then add elements to the list attribute according to the attribute in the properties
# 2.6.6 Delete User (user_del)
The user ID in the data to determine the operation of the user, the user is deleted from the user table, the user's event data **will not **be deleted.
# III. Data Restrictions
- Limitations on the number of event types and attributes
For performance reasons, the TA will limit the number of event types and attributes of the project by default:
| Restrictions | Event type upper limit | Event property upper limit | User feature cap |
|---|---|---|---|
| Suggested no more than | 100 | 300 | 100 |
| Hardware cap | 500 | 1000 | 500 |
Administrators can enter the 'Project Management' page to query the event types and attribute numbers that have been used by each project, and contact TA staff to apply for raising the upper limit of event types and attributes.
- Account ID (#account_id), visitor ID (#distinct_id) length limit
* Projects created before Version 3.1: 64 characters; To expand to 128 characters, contact TA staff
* Version 3.1 and subsequent projects: 128 characters
- Event, Property Name Restrictions
* Event name: `String` type, beginning with a letter, may contain digits, upper and lower case letters and underscores'\', Maximum length 50 words
* Attribute name: `String` type, beginning with a letter, may contain numbers, letters (ignore case) and underscores'\', Maximum length is 50 characters. Only preset properties can begin with #.
- Text, Numeric Value, List, Object, Object Group Attribute Data Range
* Text: The upper limit of the string is 2KB
* Number: Data range -9E15 to 9E15
* List: Up to 500 elements; Each element is a string type with an upper limit of 255 bytes
* Object: Contains up to 100 sub-attributes
* Object groups: up to 500 objects
- Data Reception Time Limit
* Upper limit of server-side data reception events: three to three days prior to server time
* Client Data Receiving Event Upper Limit: 10 to 3 days prior to server time
# IV. Other Rules
- Please code the data in UTF-8 to avoid scrambling.
- The property name and event name of TA are not case-sensitive. It is recommended to use'_' as a separator.
- TA Background only receives data for the last three years by default. Data over three years cannot be entered. If data before three years is required, TA staff can be contacted to relax the time limit.
# V. FAQ
This section summarizes common problems caused by data inconsistencies. If data transmission problems occur, you can check them first according to the contents of this section.
# 5.1 TA Background Did Not Receive Data
If using SDK transport:
- Please confirm that SDK is successfully integrated.
- Check if the APPID and the URL of the transport are set correctly, and if the suffix corresponding to the transport port number and mode is missing.
If you are using the LogBus or POST method to transfer:
- Please confirm whether the APPID and transmission URL are set correctly, and whether the suffix corresponding to the transmission port number and transmission method is missing.
- Please check whether the data is transmitted in JSON format and ensure that the JSON data is row by row.
- Please check whether the key value in the data information section starts with "#" and whether necessary fields are missing.
- Please check whether the type and format (time format) of the value value in the data information part are correct.
- Please check whether the value of "#event_name" conforms to the specification and does not contain characters such as Chinese characters and spaces.
- "Properties" please do not start with "#".
- In addition, please note that the user feature setting does not generate behavior records, so if only
user_setand other data are uploaded, the data cannot be directly queried in the background behavior analysis model (except SQL queries). - Please pay attention to the time of uploading data. Data that is too early (more than three years) will not be entered; if the uploaded data is historical data, it may be that the query period does not cover the time of uploading data, please adjust the query period.
# 5.2 Data is Missing, Some Attributes Are Not Received
- Please make sure that the attribute key value of the data principal part conforms to the specification and does not contain characters such as Chinese characters and spaces.
- Please make sure that in the attributes in the data principal section , the key value starting with "#" belongs to the preset attribute.
- Please check whether the type of the missing attribute is the same as the type of attribute in the background when uploading. You can view the type of the received attribute in metadata management in the background.
# 5.3 Data Transmission Error, Want to Delete Data
- Users of customized services can use the data deletion tool to delete data; If you are a user of a cloud service, contact TA staff for data deletion
- If the data is greatly changed, it is recommended to directly create a new project, and it is recommended that users conduct complete data tests under the test project before formally transmitting the data.