# LogBus 사용 가이드
이 문서는 데이터 수집 도구인 LogBus의 사용 방법을 설명합니다.
LogBus Windows 버전은 LogBus Windows 버전 사용 가이드를 참조하십시오.
데이터 액세스를 시작하기 전에 데이터 규칙을 참조하십시오. ThinkingEngine(이하 TE)의 데이터 포맷과 데이터 규칙을 이해한 후, 이 가이드에 따라 데이터 액세스를 실행하십시오.
LogBus로 업로드하는 데이터는 TE의 데이터 규칙을 준수해야 합니다.
# LogBus 다운로드
최신 버전: 1.5.15.7
업데이트 시간: 2021-12-10 다운로드 (opens new window)
Linux arm 버전 다운로드 (opens new window)
버전 업그레이드 방법
- Ver 1.5.0 이상
- ./logbus stop을 실행하여 LogBus를 중지하고, ./logbus update를 실행하여 최신 버전으로 업그레이드하십시오.
- Ver 1.5.0 이전
- 당사에 문의하십시오.
# 1. 개요
LogBus는 주로 백엔드 로그 데이터를 TE에 실시간으로 임포트하는 데 사용됩니다. 이는 Flume과 유사합니다. 또한, 서버 로그 디렉토리의 파일 흐름을 모니터링합니다. 디렉토리 내의 임의의 로그 파일에 새로운 데이터가 생성되면, 해당 데이터를 검증하고 실시간으로 TE로 전송합니다.
다음과 같은 사용자는 LogBus를 사용하여 데이터를 임포트하는 것이 좋습니다.
- 서버 SDK를 사용하는 경우
- 데이터의 정확성과 차원에 엄격하며, 클라이언트 SDK만으로는 데이터 요구사항을 충족할 수 없거나 클라이언트 SDK로 임포트할 수 없는 경우
- 백엔드 데이터의 푸시 프로세스를 개발하지 않는 경우
- 대량의 히스토리 데이터를 전송해야 하는 경우
# 2. 사용 전 데이터 준비
- 먼저 임포트할 데이터를 ETL에서 TE의 데이터 형식으로 변환하고, 로컬에 작성하거나 Kafka 클러스터로 전송합니다. 서버 측 SDK의 로컬 텍스트나 Kafka의 consumer를 사용하는 경우, 데이터는 이미 올바른 형식이므로 변환할 필요가 없습니다.
- 업로드된 데이터 파일의 저장 디렉토리 또는 Kafka의 주소와 topic을 특정하고, LogBus를 설정합니다. LogBus는 파일 디렉토리의 파일 변경을 모니터링합니다.(새 파일 또는 tail 파일을 모니터링) 또는 Kafka의 데이터를 구독합니다.
- 모니터링 디렉토리에 저장된 업로드된 데이터 로그의 이름을 변경하지 마십시오. 이름 변경은 새 파일 생성과 동일하며, LogBus는 이러한 파일을 재업로드할 수 있으므로, 데이터 중복이 발생할 수 있습니다.
- LogBus 데이터 임포트 컴포넌트에 데이터 버퍼가 포함되어 있으므로, LogBus 디렉토리가 디스크에 차지하는 용량이 커질 수 있으므로, LogBus 설치의 디스크 용량이 충분한지 확인하십시오. 하나의 프로젝트에 데이터를 임포트(APP_ID를 추가)하는 경우, 최소 10G의 스토리지를 확보해야 합니다.
# 3. LogBus의 설치와 업그레이드
# 3.1 LogBus의 설치
LogBus 도구 (opens new window)를 다운로드하고 압축을 풉니다.
압축 해제 후의 디렉토리 구조:
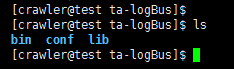
bin: 실행 프로그램 폴더
conf: 설정 파일 폴더
lib:기능 폴더
# 3.2 LogBus의 업그레이드
v1.5.0 이상을 사용하는 경우, ./logbus stop으로 LogBus를 중지하고, ./logbus update로 LogBus를 최신 버전으로 업그레이드합니다. 그 후, LogBus를 재시작합니다.
# 3.3 docker 버전
docker 컨테이너에서 logbus를 사용하는 경우, LogBus docker 사용 가이드 (opens new window)를 참조하십시오.
# 4. LogBus의 파라미터 설정
- 압축 해제 후
conf디렉토리에는 설정 파일logBus.conf.Template이 있습니다. 이 파일에는 LogBus의 모든 구성 파라미터가 포함되어 있으며, 처음 사용할 때 이름을logBus.conf로 변경합니다. - 파일 logBus.conf를 열고 파라미터를 설정합니다.
# 4.1 프로젝트와 데이터 소스 설정(필수 설정)
- 프로젝트APP_ID
##APPID는 공식 사이트 tga의 토큰에서 가져오며, TE 플랫폼의 프로젝트 설정 화면에서 프로젝트의 APPID를 획득하여 입력합니다. 여러 APPID는 ","로 구분합니다.
APPID=APPID_1,APPID_2
- 감시 파일 설정(선택해 주세요. 필수 설정)
# 4.1.1. 데이터 소스가 로컬 파일인 경우
##LogBus가 데이터 파일의 경로 및 파일명(파일명은 모호 매칭을 지원)을 읽어들입니다. 읽기 권한이 필수입니다.
다른 APPID는 쉼표로 분할하고, 같은 APPID의 다른 디렉토리는 공백으로 분할합니다.
##TAIL_FILE의 파일명은 java의 표준적인 정규 표현식과 와일드카드 둘 다를 지원합니다.
TAIL_FILE=/path1/dir*/log.* /path2/DATE{YYYYMMDD}/txt.*,/path3/txt.*
##TAIL_MATCHER는 TAIL_FILE 경로의 모호한 매칭 모드를 지정합니다. regex는 정규 표현식이고 glob는 와일드카드입니다.
##regex는 정규 모드에서, java의 표준적인 정규 표현식을 지원한다. 그러나, 일차원의 디렉토리와 파일 이름의 애매한 매칭만 지원.
##glob은 와일드카드 모드에서, 다층의 디렉토리의 애매한 매칭을 지원하며, DATE{} 형식의 매칭을 지원하지 않습니다.
##미그룹화에서 regex 정규 표현식으로 매핑
#TAIL_MATCHER=regex
TAIL_FILE은 여러 경로의 여러 디렉토리 내 여러 파일을 감시하는 것을 지원합니다.

해당 파라미터 설정:
APPID=APPID1,APPID2
TAIL_FILE=/root/log_dir1/dir_*/log.* /root/log_dir2/log/DATE{YYYYMMDD}/log.*,/test_log/*
구체적인 규칙은 다음과 같습니다.
- 같은 APP_ID의 여러 감시 경로를 공백으로 구분합니다.
- 다른 APP_ID의 감시 경로는 반각 쉼표로 구분하며, 쉼표로 구분된 감시 경로는 APP_ID에 해당합니다.
- 감시 경로의 서브디렉토리(파일이 있는 디렉토리)는 날짜 형식, 정규 표현식 감시, 와일드카드 매칭을 지원합니다.
- 파일명은 정규 표현식으로 감시 및 와일드카드를 지원합니다.
감시가 필요한 로그 파일을 서버의 루트 디렉토리에 저장하지 마십시오.
날짜 형식의 서브디렉토리 규칙(regex 모드만 지원):
날짜 형식의 디렉토리는 DATE{}로 날짜 템플릿을 둘러싸야 하며, DATE는 대문자여야 합니다. 아래에는 몇 가지 식별 가능한 날짜 템플릿 및 감시에 해당하는 파일 샘플 예시를 보여줍니다. 이에 국한되지 않으며, 날짜 템플릿은 표준 날짜 형식이면 됩니다.
/root/logbus_data/DATE{YYYY-MM-DD}/log.*---> /root/logbus_data/2019-01-01/log.1/root/logbus_data/DATE{YYMMDD}/log.*--->/Root/logbus_data/190101/log.1/root/logbus_data/DATE{MM_DD_YYYY}/log.*--->/Root/logbus_data/01_01_2019/log.1/root/logbus_data/DATE{MMDD}/log.--->/root/logbus_data/01*01/log.1
# 4.1.2. 데이터 소스가 kafka인 경우
버전 1.5.2 이후, 파라미터 KAFKA_TOPICS는 정규 표현식을 지원하지 않습니다. 여러 토픽을 감시할 때, 공백으로 토픽을 구분할 수 있습니다. 여러 APP_ID가 있는 경우, 반각 쉼표로 각 APP_ID의 감시 topic을 구분합니다. 파라미터 KAFKA_GROUPID는 유일해야 합니다. 버전 1.5.3부터 파라미터 KAFKA_OFFSET_RESET이 추가되었으며, Kafka의 파라미터 kafka.consumer.auto.offset.reset을 설정할 수 있으며, 값은 earliest와 latest를 취할 수 있으며, 기본적으로 earliest로 설정됩니다.
주의: 데이터 소스의 Kafka 버전은 0.10.1.0 이상이어야 합니다.
단일 APP_ID 예시:
APPID=appid1
######kafka 설정 파일
#KAFKA_GROUPID=tga.group
#KAFKA_SERVERS=localhost:9092
#KAFKA_TOPICS=topic1 topic2
#KAFKA_OFFSET_RESET=earliest
클라우드 서비스를 선택:tencent/ali/huawei
#KAFKA_CLOUD_PROVIDER=
#KAFKA_INSTANCE=
#KAFKA_USERNAME=
#KAFKA_PASSWORD=
#SASL 인증
#KAFKA_JAAS_PATH=
#KAFKA_SECURITY_PROTOCOL=
#KAFKA_SASL_MECHANISM=
다중 APP_ID 예시:
APPID=appid1,appid2
######kafka 설정 파일
#KAFKA_GROUPID=tga.group
#KAFKA_SERVERS=localhost:9092
#KAFKA_TOPICS=topic1 topic2,topic3 topic4
#KAFKA_OFFSET_RESET=earliest
클라우드 서비스를 선택:tencent/ali/huawei
#KAFKA_CLOUD_PROVIDER=
#KAFKA_INSTANCE=
#KAFKA_USERNAME=
#KAFKA_PASSWORD=
#SASL 인증
#KAFKA_JAAS_PATH=
#KAFKA_SECURITY_PROTOCOL=
#KAFKA_SASL_MECHANISM=
# 4.2 전송 파라미터 설정(필수 설정)
##전송 설정
전송 업로드 URL
##http 전송은
PUSH_URL=http://ta-receiver.thinkingdata.io/logbus
##온프레미스 서비스를 사용하는 경우, 전송 URL을:http://데이터 수집 주소/logbus로 변경
##appid 체크를 유효하게 할까요, 디폴트는 비활성화입니다
#IS_CHECK_APPID=false
##1회당 최대 전송량
#BATCH=10000
##최소 전송 프리퀀시(단위: 초)
#INTERVAL_SECONDS=600
##전송 스레드 수, 실제 스레드 수는 설정의 스레드 수+1, 기본값은 2개의 스레드
#NUMTHREAD=1
## 각 데이터에 속성 uuid를 추가(켜면 전송 효율이 저하됨)
#IS_ADD_UUID=true
##파일 전송의 압축 형식: gzip, lzo, lz4, snappy, none
#COMPRESS_FORMAT=none
# 4.3 Flume의 메모리 파라미터 설정(설정 선택)
# 플룸 파이프라인 용량 설정
# 파이프라인 용량, 여기는 PC의 설정에 따라 결정한다.
CAPACITY=1000000
# 파이프라인에서 sink로의 전송량이 BATCH 파라미터보다 크다.
TRANSACTION_CAPACITY=10000
##flume의 최고 메모리를 지정하고, 단위는 M입니다.
#MAX_MEMORY=2048
# flume의 채널 설정 파일, 파일과 메모리가 있습니다(선택 사항, 기본값은 파일)
# CHANNEL_TYPE=file
# 4.4 감시 문서 삭제 설정(설정 선택)
# 감시 디렉토리의 파일을 삭제. 주석의 삭제는 파일 삭제 기능을 켜는 것에 해당
# 일 단위(day) 또는 시간 단위(hour)로 삭제
# UNIT_REMOVE=hour
# 얼마나 오래된 파일을 삭제
# OFFSET_REMOVE=20
# 업로드된 감시 파일을 삭제. 몇 분 단위로 삭제.
# FREQUENCY_REMOVE=60
# 4.5 커스텀 분석기(설정 선택)
버전 1.5.9부터, 커스텀 데이터 분석을 지원합니다. 원본 데이터 형식과 TE 데이터 형식이 일치하지 않는 경우 변환 형식을 커스터마이징할 수 있습니다.
세부 사항은 다음과 같습니다:
- 다음 코드를 추가합니다:
Maven:
<dependency>
<groupId>cn.thinkingdata.ta</groupId>
<artifactId>logbus-custom-interceptor</artifactId>
<version>1.0.3</version>
</dependency>
Gradle:
// https://mvnrepository.com/artifact/cn.thinkingdata.ta/logbus-custom-interceptor
compile group: 'cn.thinkingdata.ta', name: 'logbus-custom-interceptor', version: '1.0.3'
- CustomInterceptor 인터페이스의 transFrom 메소드를 구현합니다. 메소드의 첫 번째 파라미터는 원본 데이터 내용이고, 두 번째 파라미터는 sourceName입니다.(APP_ID를 구별하고 싶을 때 사용합니다. 예를 들어, 하나의 APP_ID만 설정하면 sourceName은 r1이고, 여러 APP_ID를 설정하면 sourceName은 r1, r2 순서가 됩니다.)
public interface CustomInterceptor {
TaDataDo transFrom(String var1, String var2);
}
구현된 인터페이스 메소드는 다음과 같습니다:
public TaDataDo transFrom(String s, String s1) {
return JSONObject.parseObject(s, TaDataDo.class);
}
- 다음 두 개의 필드를 설정합니다:
##다음의 두 필드는 커스텀 분석기를 사용합니다(두 필드 모두 설정해야 합니다)
##파서의 전체 한정 이름을 커스텀하고(패키지 이름+클래스 이름), 설정하지 않을 경우 기본 파서를 사용
#CUSTOM_INTERCEPTOR=cn.thinkingdata.demo.DemoCustomInterceptor
##커스텀 분석 대상 jar의 절대 경로(jar의 파일명을 포함하여)
#INTERCEPTOR_PATH=/var/interceptor/custom-interceptor-1.0-SNAPSHOT.jar
# 4.6 데이터 내의 #app_id에 의한 프로젝트 분할(설정 선택)
주의:이 기능을 사용하려면, TE 버전 3.1 이상이 필요합니다.
##1.5.14부터 APPID_IN_DATA 설정을 추가. 사용 중 데이터의 #app_id로 프로젝트를 배분할 때, APPID_IN_DATA=true는 설정 가능합니다.
##APPID 설정은 필요 없으며, TAIL_FILE도 한 단계만 설정 가능
##주의: TE의 최소 버전은 3.1입니다
#APPID_IN_DATA=false
# 4.7 설정에 따라 해당 프로젝트에 자동 배포(설정 선택)
##1.5.14는 이전 기능을 변경하고, TE3.1 이상의 버전과 함께 사용해야 합니다.
## 매핑할 속성 이름을 지정하고, 예를 들어 name, APPID_MAP 필드와 함께 사용해야 합니다
##APPID_MAP_ATTRIBUTE_NAME=name
##APPID와 속성 값의 대응 관계를 제공하며, 예를 들어 아래 설정은 데이터의 properties 필드의 name 필드 값이 a나 b일 때 데이터는 appid_1에 배포하고, c와 d일 때, appid_2에 배포
##APPID_MAP={"appid_1":["a","b"],"appid_2":["c","d"]}
##DEFAULT_APPID는 데이터에 name 필드 또는 name 필드의 가치가 없다면 위의 설정에 없는 경우에 배포하는 프로젝트를 나타냅니다
##DEFAULT_APPID=appid_3
# 4.8 설정 파일 예제
##################################################################################
## thinkingdata 데이터 분석 플랫폼의 데이터 수집 도구 logBus의 설정 파일
##주석이 없는 것은 필수 파라미터이고 주석이 있는 것은 선택 사항 파라미터는 자신의 상황에 맞게 적절한 설정을 하세요
##환경 조건: java8+, 자세한 내용은 tga 공식 사이트를 참조하십시오
##http://doc.thinkinggame.cn/tgamanual/installation/logbus_installation.html
##################################################################################
##APPID는 tga 공식 사이트의 token에 있습니다
##다른 APPID는 쉼표로 구분합니다
APPID=from_tga1,from_tga2
#-----------------------------------source----------------------------------------
######file-source
##LogBus는 데이터 파일이 위치한 경로와 파일 이름을 가져옵니다(파일 이름은 모호한 일치를 지원). 읽기 권한이 필요합니다.
##다른 APPID는 쉼표로 구분하고, 같은 APPID의 다른 디렉토리는 공백으로 구분합니다.
##TAIL_FILE의 파일 이름은 자바의 표준 정규 표현식과 와일드카드 모두를 지원합니다.
#TAIL_FILE=/path1/log.* /path2/txt.,/path3/log. /path4/log.* /path5/txt.*
##TAIL_MATCHER는 TAIL_FILE의 경로에 대한 모호한 매칭 모드를 지정합니다. regex는 정규 표현식, glob는 와일드카드입니다.
##regex는 정규 모드로, 자바의 표준 정규 표현식을 지원합니다. 하지만, 한 단계의 디렉토리와 파일 이름의 모호한 매칭만을 지원합니다.
##glob는 와일드카드 모드로, 다층의 디렉토리 모호한 매칭을 지원하며, DATE{} 형식의 매칭은 지원하지 않습니다.
##기본값은 regex 정규 표현식으로 매칭합니다.
#TAIL_MATCHER=regex
######kafka-source
##kafka, topics 정규 표현식을 사용합니다.
#KAFKA_GROUPID=tga.flume
#KAFKA_SERVERS=ip:port
#KAFKA_TOPICS=topicName
#KAFKA_OFFSET_RESET=earliest/latest
#------------------------------------sink-----------------------------------------
##전송 설정
##전송 주소
##PUSH_URL=http://${데이터 수집 주소}/logbus
##한 번에 최대 전송량(지정된 수량에 도달하면 데이터 전송 지시를 내림)
#BATCH=1000
##최소 전송 빈도(단위: 초)(시간이 지났지만, batch 수를 충족하지 않음. 현재 데이터량을 전송)
#INTERVAL_SECONDS=60
##### http 전송
##파일 전송의 압축 형식: gzip, lzo, lz4, snappy, none
#COMPRESS_FORMAT=none
#------------------------------------other-----------------------------------------
##모니터링 디렉토리의 파일을 삭제합니다. 주석을 해제하면(아래 두 필드 모두를 on으로 설정) 파일 삭제 기능이 활성화됩니다. 1시간마다 파일 삭제 앱을 실행합니다.
##offset 이전의 파일을 삭제합니다.
##얼마나 이전 파일을 삭제할지 지정합니다.
#OFFSET_REMOVE=
##일 단위(day) 또는 시간 단위(hour)로 삭제
#UNIT_REMOVE=
#------------------------------------interceptor-----------------------------------
##다음 두 필드는 커스텀 분석기 사용 시 설정해야 합니다(두 필드 모두 설정 필요).
##분석기의 전체 한정 이름을 커스터마이징합니다(패키지 이름+클래스 이름), 설정하지 않을 경우 기본 분석기를 사용합니다.
#CUSTOM_INTERCEPTOR=
##커스텀 분석기의 jar 위치
#INTERCEPTOR_PATH=
# 5. LogBus 시작
처음 시작하기 전에, 다음 체크를 수행해야 합니다.
- Java 버전 확인
bin 디렉토리에는 check_java와 logbus라는 두 개의 스크립트가 있습니다.
check_java는 Java 버전이 요구 사항을 충족하는지 감지하고 스크립트를 실행합니다. Java 버전이 충족되지 않는 경우 'Java version is less than 1.8' 또는 'Can't find java, please install jre first.'와 같은 힌트가 표시됩니다.
JDK 버전을 업데이트하거나, 다음 섹션을 참조하여 LogBus에 독립적인 JDK를 설치하십시오.
bin 디렉토리에는 check_java와 logbus의 두 개의 스크립트가 있습니다.
- LogBus의 독립 JDK 설치
노드를 배포하는 경우, 환경상의 이유로 JDK 버전이 LogBus의 요구 사항을 충족시키지 못하고, LogBus의 JDK 버전으로 교체할 수 없습니다. 이 경우, 이 기능을 사용할 수 있습니다.
bin 디렉토리에는 install_logbus_jdk.sh가 있습니다.
이 스크립트를 실행하면, LogBus 작업 디렉토리에 Java 디렉토리가 추가됩니다. LogBus는 기본적으로 이 디렉토리의 JDK 환경을 사용합니다.
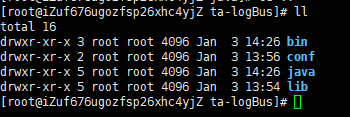
- logBus.conf의 설정을 완료하고, 파라미터 환경을 실행하여 명령을 체크합니다.
logBus.conf의 설정은, LogBus 설정을 참조하십시오.
설정이 완료되면 env 명령을 실행하여 설정 파라미터가 정확한지 체크합니다.
./logbus env

붉은색 이상 정보를 출력하면, 설정에 문제가 있음을 나타내며, 설정 파일에 예외가 없을 때까지 다시 수정해야 합니다.
LogBus.conf의 설정을 변경한 후, LogBus를 재시작하여 새로운 설정을 활성화해야 합니다.
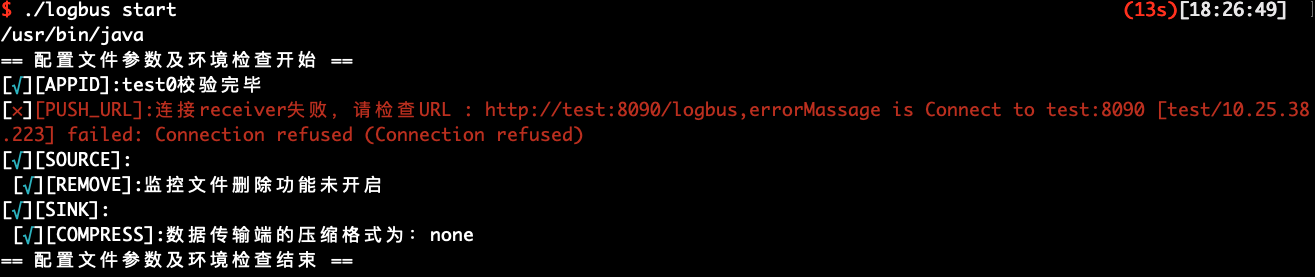
- LogBus를 시작
./logbus start

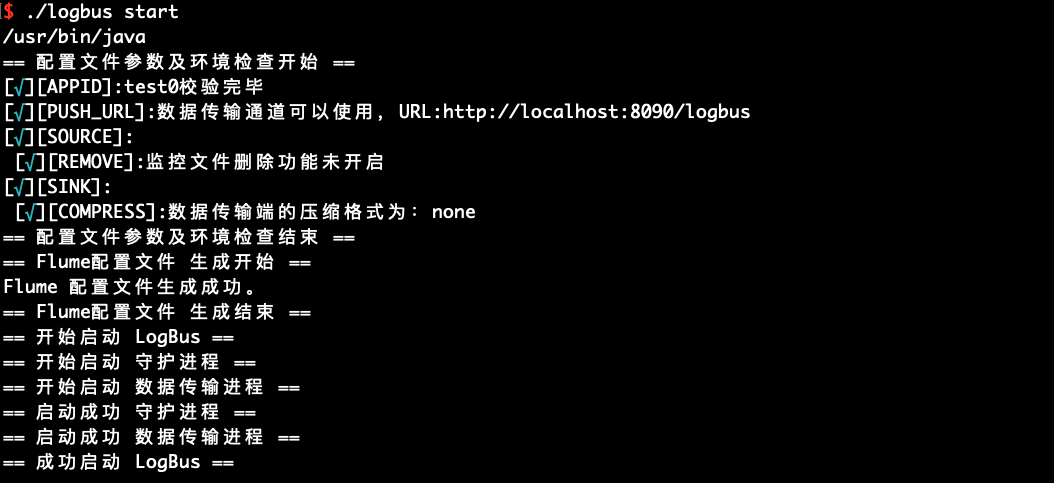
성공적으로 시작하면, 위 그림과 같은 알림이 표시되고, 실패하면 이상 정보가 표시됩니다.
# 6. LogBus 명령어의 액세스 상세
# 6.1 도움말 정보
파라미터, --help, -h 없이 실행할 경우, 다음과 같은 도움말 정보가 표시됩니다.

LogBus의 명령어를 소개합니다:
사용법: logbus <명령어|보조 명령어> [옵션]
명령어:
start logBus시작
restart logBus재시작
stop logBus종료
reset logBus읽기 기록 리셋
stop_force logBus강제 종료.
보조 명령어:
env 운영 환경 검증.
data_debug 디렉토리에 있는 파일의 데이터 형식의 상세 검증 설정.
show_conf 현재 logBus의 설정 정보 표시.
version 버전 표시.
update logbus를 최신 버전으로 업데이트.
progress 현재 파일의 전송 속도 집계
status 현재의 전송 속도 집계. 메모리 점유율, CPU 소모 등의 정보
옵션:
-appid <appid> 프로젝트 appid
-h,--help 도움말 파일을 표시하고 종료.
-path <path> 테스트 파일의 절대 경로 지정
-url <url> 테스트 주소 지정
예시:
./logbus start logBus 시작.
./logbus stop logBus 안전 종료.
./logbus restart logBus 재시작.
./logbus data_debug 디렉토리에 있는 파일의 데이터 형식의 상세 검증 설정.
# 6.2 파일 데이터 형식 검사 data_debug
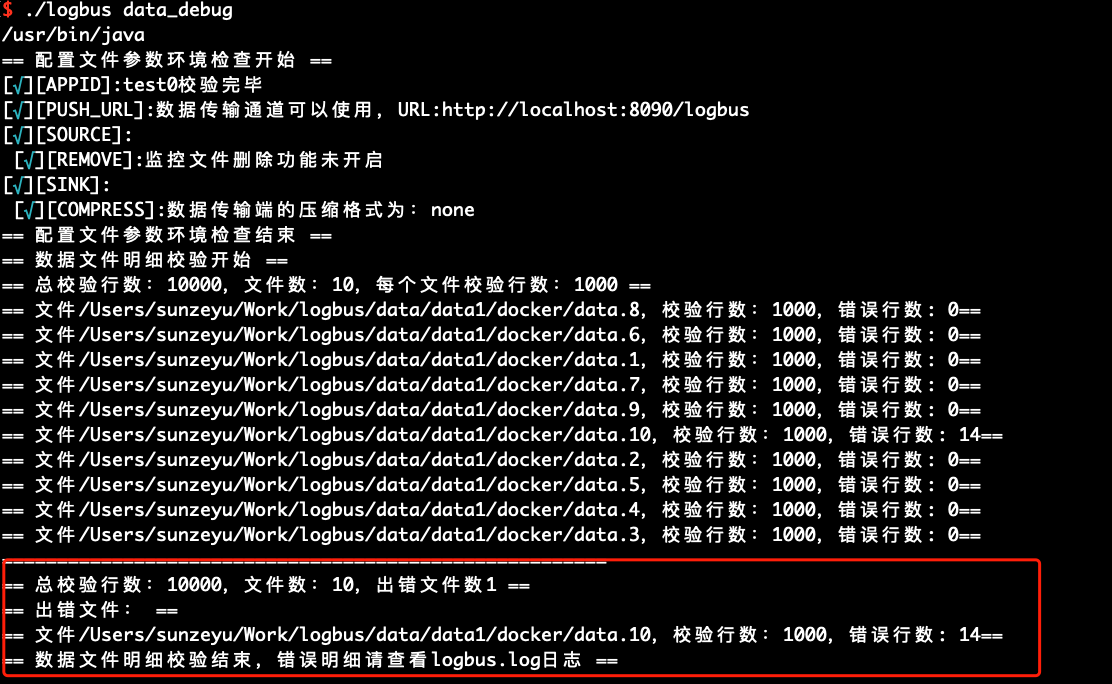
LogBus를 처음 사용하는 경우, 데이터를 정식으로 업로드하기 전에 데이터 형식을 검사하는 것이 좋습니다. 데이터는 데이터 규칙을 준수해야 하며, data_debug 명령으로 데이터 형식의 검사를 수행합니다.
이 기능은 클러스터의 리소스를 소모하며, 매번 10000건을 한도로 합니다. 파일별로 검사량을 균등하게 분배하고, 파일의 시작부터 검사를 진행합니다.
./logbus data_debug
데이터 형식이 올바른 경우, 다음 그림과 같이 데이터가 정확하다는 것을 나타냅니다.

데이터 형식에 문제가 있는 경우, 형식 오류를 경고하고, 형식 오류의 포인트를 간단히 해석합니다.
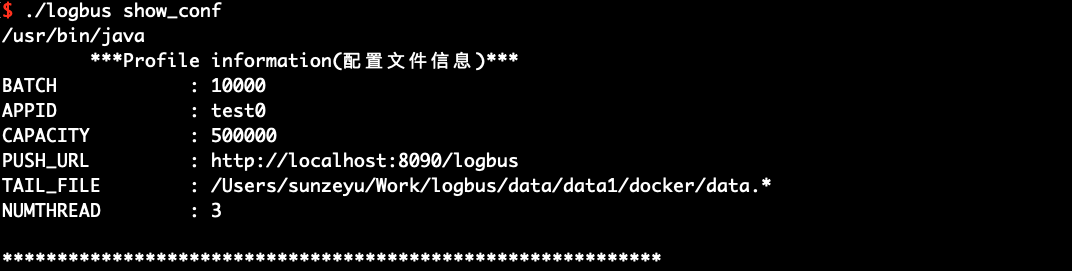
# 6.3 설정 정보의 표시 show_conf
show_conf 명령을 사용하여, 다음 그림과 같이 LogBus의 설정 정보를 표시합니다.
./logbus show_conf
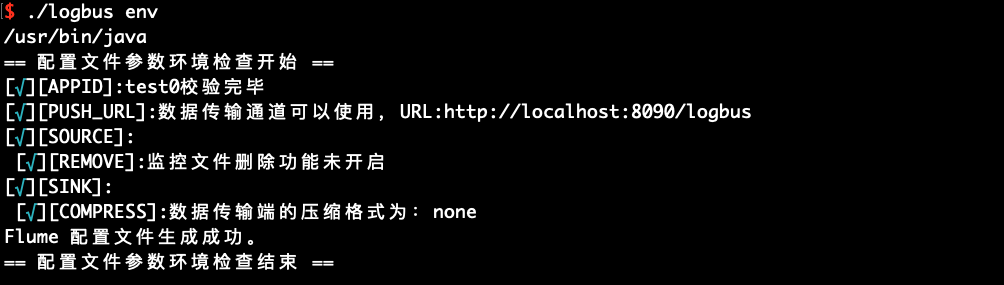
# 6.4 환경 체크의 실행 env
env를 사용하여 실행 환경의 체크를 할 수 있습니다. 출력된 정보 뒤에 별표가 붙어 있는 경우, 설정에 문제가 있음을 나타내며, 별표 힌트가 사라질 때까지 수정해야 합니다.
./logbus env
# 6.5 시작 start
형식의 검사, 데이터 채널의 검사 및 환경의 검사가 완료되면, LogBus를 시작하여 데이터 업로드를 수행합니다. LogBus는 자동으로 파일에 새로운 데이터가 작성되었는지를 감지하고, 새로운 데이터가 있는 경우, 데이터를 업로드합니다.
./logbus start
# 6.6 정지 stop
LogBus를 정지하고 싶을 때는 stop 명령을 사용해 주세요.
./logbus stop

# 6.7 강제 정지 stop_force
즉시 LogBus를 정지하고 싶을 때는 stop_force 명령을 사용해 주세요. 하지만, 이 명령은 데이터를 잃을 가능성이 있습니다.
./logbus stop_force
# 6.8 재시작 restart
restart 명령을 사용하여 LogBus를 재시작할 수 있습니다. 설정 파라미터를 수정한 후 새로운 설정을 활성화합니다.
./logbus restart
# 6.9 클리어 reset
reset명령을 사용하여 LogBus를 리셋할 수 있지만, 주의해서 사용해야 합니다. 이 명령을 실행하면 데이터 전송 기록이 삭제되어 LogBus가 모든 데이터를 다시 업로드하게 됩니다. 이상한 조건에서 이 명령을 사용하면 데이터가 중복될 수 있습니다. TE 매니저와 연락한 후 사용하는 것이 권장됩니다.
./logbus reset
리셋 명령을 실행한 후, start를 실행하여 데이터 전송을 다시 시작해야 합니다.
LogBus 1.5.0 버전 이상에서는 다음의 확인 정보를 추가하고, 확인 후에 LogBus의 리셋을 시작합니다.

# 6.10 버전 표시 version
현재 사용 중인 LogBus의 버전 번호를 알고 싶다면 version 명령을 사용합니다. LogBus에 이 명령이 없다면 오래된 버전을 사용하고 있는 것입니다.
./logbus version
# 6.11 LogBus 버전 업데이트update
LogBus1.5.0은 온라인으로 버전을 업데이트하는 기능이 추가되었고, 이 명령을 실행하면 LogBus가 최신 버전으로 업데이트됩니다.
./logbus update
# 6.12 현재 업로드 진행 상황 확인progress
LogBus1.5.9는 현재 업로드의 진행 상황을 확인하는 기능이 추가되었습니다. 이 명령을 실행하면 현재 전송의 진행 상황을 확인할 수 있습니다. -appid를 사용하여 프로젝트를 지정하거나, 파일의 전체 경로 이름을 직접 추가하여 검색을 지정할 수 있습니다.
./logbus progress /data/logbus-1.log /data/logbus-2.log -appid {APPID}
# 6.13 LogBus의 일반적인 문제 확인doctor
LogBus 버전 1.5.12는 LogBus의 일반적인 문제를 체크하는 명령이 추가되었고, 이 명령을 실행하면 현재 LogBus에 문제가 있는지 체크할 수 있습니다.
./logbus doctor
# 6.14 LogBus의 현재 업로드 속도 및 상태 확인status
LogBus1.5.13은 LogBus의 현재 업로드 속도와 상태를 표시하는 명령이 추가되었고, 이 명령을 실행하면 현재 LogBus의 업로드 속도와 상태를 확인할 수 있습니다.
./logbus status