# Data Rules(데이터 룰)
이 문서에서는 TE (ThinkingEngine)의 데이터 구성, 데이터 형식, 그리고 데이터의 제약사항에 대해 자세히 설명합니다. 또한 룰에 따라 데이터를 구축하고, 데이터 전송 문제를 조사하는 방법도 설명합니다.
LogBus 또는 RESTful API를 사용하여 데이터를 전송하는 경우, 이 문서의 데이터 룰에 따라 데이터를 정리해야 합니다.
# 데이터 구성
TE는 룰에 따른 JSON 데이터를 받아들입니다. SDK가 사용되고 있는 경우, 데이터는 전송용으로 JSON 데이터로 변환됩니다. LogBus 또는 POST 메소드를 사용하는 경우, 데이터는 일반적인 JSON 데이터여야 합니다.
JSON 데이터는 행동 단위이며, 즉, 1행의 JSON 데이터는 1개의 데이터에 해당합니다. 데이터의 의미에서는, 사용자가 1개의 행동을 하거나, 사용자 속성을 설정하는 것을 나타냅니다.
데이터의 형식과 제약사항은 다음과 같습니다. (읽기 쉽게 하기 위해 데이터의 형태를 정리하였지만, 실제 환경에서는 줄바꿈을 하지 마십시오)
- 아래는 이벤트 데이터의 샘플입니다.
{
"#account_id": "ABCDEFG-123-abc",
"#distinct_id": "F53A58ED-E5DA-4F18-B082-7E1228746E88",
"#type": "track",
"#ip": "192.168.171.111",
"#uuid": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"#time": "2017-12-18 14:37:28.527",
"#event_name": "test",
"properties": {
"argString": "abc",
"argNum": 123,
"argBool": true
}
}
- 아래는 사용자 속성 데이터의 샘플입니다.
{
"#account_id": "ABCDEFG-123-abc",
"#distinct_id": "F53A58ED-E5DA-4F18-B082-7E1228746E88",
"#type": "user_set",
"#uuid": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"#time": "2017-12-18 14:37:28.527",
"properties": {
"userArgString": "abc",
"userArgNum": 123,
"userArgBool": true
}
}
"#type"의 값은 "user_setOnce", "user_add", "user_unset", "user_append", "user_del"로 대체할 수 있습니다.
구조와 기능 측면에서, JSON 데이터는 두 부분으로 나눌 수 있습니다.
properties의 동일한 레이어의 다른 필드는 이 데이터의 다음 기본 정보를 구성합니다.
- 사용자의 Account ID를 나타내는 #account_id와 Guest ID를 나타내는 #distinct_id
- 시간(초 또는 밀리초까지)을 나타내는 #time
- 데이터 타입(이벤트 또는 유저 속성 설정)을 나타내는 #type
- 이벤트 이름(이벤트 데이터만)을 나타내는 #event_name
- 사용자 IP를 나타내는 #ip
- 데이터의 고유성을 나타내는 #uuid
위의 항목에 더하여, "#"로 시작하는 속성은 properties 내의 레이어에 배치해야 합니다.
properties 내의 레이어는 데이터의 내용, 즉 이벤트의 속성 또는 설정해야 하는 유저 기능입니다. 백그라운드 분석 중에 속성 또는 분석 객체로 직접 사용됩니다.
구조적으로 보면, 이 두 부분은 헤더와 콘텐츠와 유사합니다. 다음은 이 두 부분의 각 필드의 의미를 자세히 설명합니다.
# 1.1 데이터 구조
다음 그림에서 빨간색으로 표시한 것처럼, "properties"와 같은 계층의 몇몇 필드가 이 데이터의 정보 부분을 구성합니다.
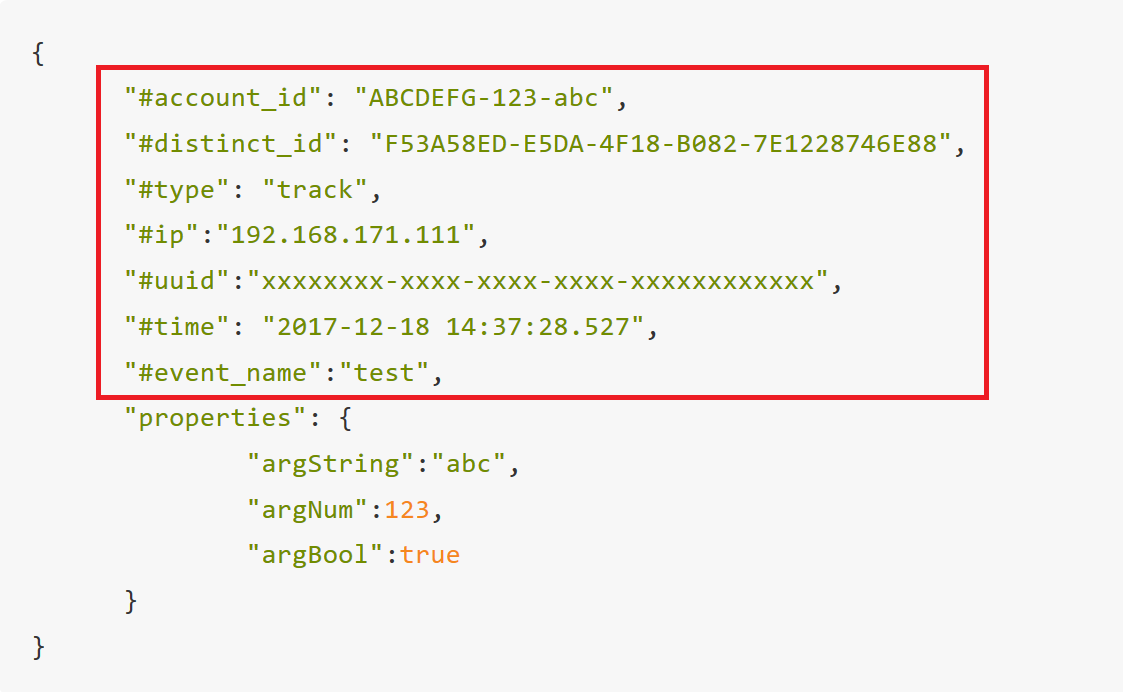
이 필드들은 이 데이터의 사용자와 시간을 나타내는 정보를 포함하고 있습니다. 그 특징은 모든 필드가 "#"로 시작한다는 것입니다. 각 필드의 의미와 구성 방법을 정리하겠습니다.
# 1.1.1 사용자 (#account_id 와 #distinct_id)
#account_id 와 #distinct_id는 TE에서 사용자를 식별하기 위한 두 개의 필드이며, 그 중 #account_id는 사용자가 로그인 상태에서의 ID이고, #distinct_id는 로그인하지 않은 상태에서 사용자를 식별하는 ID입니다. TE에서는 이 두 개의 필드를 기반으로 행동을 취하는 사용자를 판단합니다. 그 때 우선적으로 #account_id를 사용하여 판단합니다. 구체적인 규칙은 사용자 식별 규칙을 참조하십시오.
#account_id 와 #distinct_id는 적어도 하나를 전달해야 합니다. 사용자가 로그인했을 때 모든 이벤트가 트리거되는 경우, #account_id만을 전달할 수 있습니다. 사용자가 로그인하지 않은 상태에서 트리거되는 이벤트가 있는 경우(등록 전 포함), 두 필드 모두에 입력하는 것을 권장합니다.
#account_id 와 #distinct_id는 적어도 하나를 수신해야 합니다. 모든 이벤트가 사용자가 로그인한 상태에서 발생하는 경우, #account_id만을 수신할 수도 있습니다. 로그인하지 않은 상태(계정을 생성하지 않은 상태 포함)에서 이벤트를 발생시키는 경우, 두 필드 모두를 입력하는 것을 권장합니다.
# 1.1.2 데이터 타입 (#type 와 #eventname)#type은 이벤트 데이터와 사용자 속성의 변경 중 어느 것이든 데이터의 종류를 결정하는 데 사용됩니다. 그 선택은 #type으로 설정됩니다. #type은 두 가지 카테고리로 나뉩니다. Track은 이 데이터가 사용자의 이벤트 기록임을 의미합니다. user로 시작하는 경우 사용자 속성을 조작함을 의미합니다. 구체적인 의미는 다음과 같습니다.
- Track: 이벤트 테이블을 조작하고, 모든 이벤트는 트랙으로 업로드됩니다.
- user_set: 사용자 테이블을 조작하고, 하나 이상의 사용자 속성을 덮어쓰며, 속성에 이미 값이 있는 경우 이전 값을 덮어씁니다.
- user_setOnce: 사용자 테이블을 조작하고, 하나 이상의 사용자 속성을 초기화하며, 속성에 이미 값이 있는 경우 이 작업은 무시됩니다.
- user_add: 사용자 테이블을 조작하고, 하나 이상의 사용자 속성(숫자)을 누적 계산합니다.
- user_unset: 사용자 테이블을 조작하고, 하나 이상의 사용자 속성의 값을 비웁니다.
- user_del: 사용자 테이블을 조작하고, 해당 사용자를 삭제합니다.
- user_append: 사용자 속성의 속성 값(list type)에 요소를 추가하여 사용자 테이블을 조작합니다.
#type의 값이 track인 경우, 데이터가 이벤트인 경우, 이벤트 이름을 #eventname으로 설정해야 합니다. 이는 문자로 시작해야 하며, 다음 문자만 포함할 수 있습니다(대문자와 소문자는 구분됩니다), 숫자, 언더스코어""로, 최대 50 characters입니다. 사용자 기능을 변경하는 작업의 경우, #event_name 필드는 필요하지 않습니다.
또한, 사용자 속성은 높은 중요도를 가지며, 단기간에 자주 변경하는 것은 권장하지 않습니다. 자주 변경해야 하는 속성에 대해서는 이벤트 속성으로 넣는 것을 권장합니다.
# 1.1.3 시간(#time)#time은 이벤트가 생성된 시간이며 필수 필드입니다. 그 형식은 밀리초("yyyy-MM-dd HH:mm: ss.SSS") 또는 ("yyyy-MM-dd HH:mm:ss")이어야 합니다.
사용자 테이블에 저장되는 데이터도 #time을 설정해야 하지만, TE는 데이터를 수신한 순서대로 작업합니다.
예를 들어, 사용자가 지난 1일 동안의 사용자 테이블 작업 데이터를 재전송하면, 속성의 덮어쓰기와 초기화는 평소대로 진행됩니다. 따라서 #time 필드에 따른 판정은 이루어지지 않습니다.
# 1.1.4 위치(#ip)
#ip는 장치의 IP 주소이며 선택적 필드입니다. TE가 수신하면, IP 주소를 기반으로 사용자의 지리적 위치 정보를 계산합니다. 그러나 속성으로서, #county, #province, #city, 그 외의 지리적 위치 속성은 입력된 값이 우선됩니다.
# 1.1.5 데이터의 유일성(#uuid)
#uuid는 데이터 필드의 유일성을 나타내기 위해 사용되며 선택적 필드입니다. 형식은 uuid의 표준 형식이어야 합니다. TE에서는, 데이터 양에 따라 수신 측에서 짧은 시간 내에 같은 #uuid(=중복 데이터)가 나타나는지 확인하고, 중복 데이터는 버리고 저장하지 않습니다.
#uuid로 수행하는 확인은 주로 단기간의 데이터 중복으로 인한 네트워크 지터 문제를 해결하기 위해, 최근 수시간 동안 수신한 데이터만 확인하며, 수신 데이터는 전체 용량으로 확인할 수 없음을 이해해 주시기 바랍니다. 데이터의 중복 제거가 필요한 경우, 별도로 문의해 주세요.
# 1.2 데이터 원칙
그 외 부분은, properties 내 레이어에 포함된 데이터입니다. properties는 JSON 객체이며, 데이터는 키와 값이 쌍으로 표현됩니다. 사용자 이벤트 데이터라면, 이벤트 속성과 그에 해당하는 값을 표현합니다. 이러한 속성이나 값은, 분석에 직접 사용할 수 있습니다. 사용자 속성의 작업이라면, 설정이 필요한 속성과 값을 표현합니다.키는 속성 이름이며, 타입은 string입니다. 사용자 지정 속성은 문자로 시작해야 하며, 문자(대문자와 소문자는 무시), 숫자, 언더스코어"_"를 포함할 수 있습니다. 또한, #으로 시작하는 TE 프리셋 속성도 있습니다. 자세한 내용은 프리셋 속성을 참조하십시오. 그러나 대부분의 경우, 사용자 지정만 사용하는 것을 권장합니다.
값은 속성의 값이며, numeric value, text, time, Boolean, list, object, object group을 지정할 수 있습니다. 데이터 타입은 다음과 같습니다.
| TE데이터 타입 | 샘플 | 비고 | JSON데이터 타입 |
|---|---|---|---|
| Value | 123,1.23 | 데이터 범위는 -9E15에서 9E15입니다 | Number |
| Text | "ABC", "Shanghai" | 문자의 기본 제한은 2KB입니다 | String |
| Time | "2019-01-01 00:00:00","2019-01-01 00:00:00.000" | "Yyyy-MM-dd HH: mm: ss. SSS" 또는 "yyyy-MM-dd HH: mm: ss", 날짜를 표시하려면 "yyyy-MM-dd 00:00:00"을 사용할 수 있습니다 | String |
| Boolean | true,false | - | Boolean |
| 리스트 | ["a","1","true"] | 목록의 모든 요소는 문자열 타입으로 변환되며, 목록에는 최대 500개의 요소가 있습니다. | Array(String) |
| Object | {hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False} | 객체 내의 각 하위 속성(Key)은 고유한 데이터 타입을 가지고 있습니다. 값 선택 설명은 위의 해당 타입의 일반 속성을 참조하십시오. 객체 내에는 최대 100개의 하위 속성이 있습니다. | Object |
| 개체 그룹 | [{hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False}, {hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False}] | 개체 그룹 내의 각 하위 속성(Key)은 고유의 데이터 타입을 가지고 있습니다. 값 선택 설명은 위의 해당 타입의 일반 속성을 참조하십시오 개체 그룹에는 최대 500개의 개체가 있습니다 | Array(Object) |
모든 속성 타입은 처음으로 받은 값의 타입에 의해 결정된다는 점을 주의하십시오. 그 후의 데이터는 해당 속성과 동일한 데이터 타입이어야 합니다. 타입과 일치하지 않는 속성은 폐기되며, TE는 타입 변환을 수행하지 않습니다.
# 데이터 처리 규칙
TE는 데이터를 수신한 후 몇 가지 처리를 수행합니다. 실제 사용 시나리오를 사용하여 TE 처리 규칙을 설명합니다.
# 2.1 새 이벤트 수신
새로운 이벤트 데이터를 수신한 후, TE는 자동으로 새 이벤트와 그 속성의 관련 모델을 생성합니다. 새로운 속성을 수신한 경우, 그 속성을 처음으로 수신한 때의 속성 타입을 속성 타입으로 설정하며, 속성 타입은 그 이후 변경할 수 없습니다.
# 2.2 이벤트 속성 추가
기존 이벤트에 속성을 추가해야 하는 경우, 데이터를 업로드할 때 새로운 속성을 추가하기만 하면 됩니다. TE는 이벤트와 새로운 속성을 동적으로 연동하므로, 다른 처리는 필요하지 않습니다.
# 2.3 이벤트 속성의 불일치
이벤트 데이터를 수신할 때, 그 중의 어떤 속성 타입이 TE에 이미 있는 해당 속성 타입과 일치하지 않는 경우, 그 속성 값은 폐기됩니다(값은 null이 됩니다).
# 2.4 이벤트 속성의 폐기
이벤트 속성을 폐기하려는 경우, TE의 메타데이터에서 숨길 수 있습니다. 그 후의 데이터 전송에서는 속성을 전송할 수 없습니다. 한편, TE는 속성의 데이터를 삭제하지 않으며, 이 숨기기 작업은 되돌릴 수 있습니다. 속성이 숨겨진 후에 속성이 통신된 경우, 속성의 값은 계속 유지됩니다.
# 2.5 퍼블릭 이벤트 속성 설정
다른 이벤트에 대한 동일한 속성 이름은 동일한 속성으로 간주되며, 동일한 데이터 타입으로 간주됩니다. 따라서, 데이터 타입의 차이로 인한 속성 값의 손실을 피하기 위해, 모든 동일한 속성 이름은 동일한 데이터 타입이어야 합니다. 다른 의미를 부여하려면, 동일한 속성 이름이 아닌 다른 속성 이름을 설정해 주세요.
# 2.6 유저 속성 데이터 처리
유저 테이블 내의 유저 데이터 변경은, #type 필드가 user_set, user_setOnce, user_add, user_unset, user_append, user_del인 경우의 처리 방법입니다. 작업 유형은 #type 필드에 의해 결정되며, 작업 내용은 속성의 속성에 의해 결정됩니다.
# 2.6.1 덮어쓰기(user_set)
데이터의 유저 ID로 작업할 유저를 식별하고, properties에 따라 모든 속성을 덮어씁니다. 특정 속성이 존재하지 않는 경우, 그 속성을 새로 생성합니다.
# 2.6.2 초기화(user_setOnce)
데이터의 유저 ID로 작업할 유저를 식별하고, properties에 따라 값이 할당되지 않은(빈) 속성에 대해 설정합니다. 그 유저의 특정 설정이 필요한 속성이 이미 값을 가지고 있는 경우, 덮어쓰지 않고, 특정 속성이 존재하지 않는 경우, 새로 그 속성을 설정합니다.
# 2.6.3 누적(user_add)
데이터의 유저 ID로 작업할 유저를 식별하고, properties에 따라 숫자형 속성의 누적 작업을 수행합니다. 마이너스 값이 들어오는 경우, 원래의 속성 값에서 그 값을 빼게 됩니다. 반면, 그 유저의 특정 설정이 필요한 속성이 할당되지 않은(빈) 경우, 기본적으로 0으로 설정한 후 누적 작업을 수행하고, 그 속성이 존재하지 않는 경우, 새로 그 속성을 추가합니다.#### 2.6.4 속성 값 삭제(user_unset)
데이터의 유저 ID로 작업할 유저를 특정하고, properties에 기반하여, 모든 속성을 삭제(즉, NULL로 설정)합니다. 어떤 속성이 존재하지 않는 경우, 그 속성은 새로 생성되지 않습니다.
# 2.6.5 요소 추가(user_append)
데이터의 유저 ID로 작업할 유저를 특정하고, properties에 기반하여, 리스트형의 속성에 요소의 추가를 진행합니다.
# 2.6.6 유저 삭제(user_del)
데이터의 유저 ID로 작업할 유저를 특정하고, 그 유저를 유저 테이블에서 삭제합니다. 그러나, 그 유저의 이벤트 데이터는 삭제되지 않습니다.
# 데이터 제한
- 이벤트 수와 속성 수의 제한
성능상의 이유로, TE는 프로젝트의 이벤트 수와 속성 수를 기본적으로 제한합니다.
| 제한사항 | 이벤트 유형 상한선 | 이벤트 속성 상한선 | 사용자 특성 상한선 |
|---|---|---|---|
| 제안하는 최대 수 | 100 | 300 | 100 |
| 하드웨어 상한선 | 500 | 1000 | 500 |
Admin은 '프로젝트 관리' 페이지에서 각 프로젝트에서 사용되는 이벤트 개수와 속성 개수를 조회할 수 있습니다.
- Account_ID(#account_id), Guest_ID(#distinct_id)의 길이 제한
* 버전 3.1 이전에 생성된 프로젝트: 64자; 128자로 확장하려면 TE 스태프에게 연락하십시오
* 버전 3.1 및 이후 프로젝트: 128자
- 이벤트, 속성 이름의 제한```플레인 텍스트
- 이벤트 이름:
스트링타입, 문자로 시작, 숫자, 대소문자 및 밑줄''을 포함할 수 있음, 최대 길이 50 단어 - 속성 이름:
스트링타입, 문자로 시작, 숫자, 문자 (대소문자 무시) 및 밑줄''을 포함할 수 있음, 최대 길이는 50자. #으로 시작할 수 있는 속성은 미리 설정된 속성만 가능합니다.
- 데이터 타입별 제한
```플레인 텍스트
* 텍스트: 스트링의 상한선은 2KB입니다
* 숫자: 데이터 범위 -9E15에서 9E15까지
* 리스트: 최대 500개의 요소; 각 요소는 255 바이트의 상한선을 가진 스트링 타입입니다
* 오브젝트: 최대 100개의 하위 속성을 포함할 수 있습니다
* 오브젝트 그룹: 최대 500개의 오브젝트를 가질 수 있습니다
- 데이터의 가능 수신 시간 제한
* 서버 측 데이터 수신 이벤트의 상한선: 서버 시간으로부터 3일 전까지
* 클라이언트 데이터 수신 이벤트 상한선: 서버 시간으로부터 10일에서 3일 전까지
# 기타 규칙1. 스크램블을 피하기 위해 UTF-8로 데이터를 코딩해 주세요.
- TE의 속성 이름과 이벤트 이름은 대소문자를 구분하지 않습니다. 구분자로 '_'를 사용하는 것을 권장합니다.
- TE는 기본적으로 과거 3년간의 데이터만을 수신합니다. 3년 이상의 데이터는 입력할 수 없습니다. 3년 전의 데이터가 필요한 경우, 별도로 상의해 주세요.
# FAQ
데이터의 불일치로 인해 발생하는 일반적인 문제를 정리합니다. 데이터 전송의 문제가 발생한 경우, 이 섹션의 내용을 확인할 수 있습니다.
# TE가 데이터를 수신하지 않았습니다
SDK를 사용하는 경우:
- SDK가 정상적으로 통합되었는지 확인해 주세요
- SDK의 APPID와 URL이 올바르게 설정되었는지, 트랜스포트 포트 번호와 모드에 해당하는 접미사가 누락되지 않았는지 확인해 주세요.
LogBus 또는 POST 메소드를 사용하는 경우:
- SDK의 APPID와 URL이 올바르게 설정되었는지, 트랜스포트 포트 번호와 모드에 해당하는 접미사가 누락되지 않았는지 확인해 주세요.
- 데이터가 JSON 형식으로 전송되었는지 확인하고, JSON 데이터가 줄 단위로 전송되었는지 확인해 주세요.
- 데이터 구조를 다시 확인하고, 키가 '#'로 시작하는지, 필요한 필드가 누락되지 않았는지 확인해 주세요.
- 데이터 구조를 다시 확인하고, 값의 종류와 형식(특히 시간 형식)이 올바른지 확인해 주세요.
- '#event_name'의 값이 사양을 준수하고 있으며, 한자나 공백 등의 문자가 포함되어 있지 않은지 확인해 주세요.
- 'properties'가 '#'로 시작하지 않는지 확인해 주세요.
- 사용자 속성의 작업에서는 이벤트 테이블의 레코드가 생성되지 않습니다. user_set 등의 데이터만 접근되는 경우, SQL 쿼리를 제외하고, 이벤트 분석 모델에서 직접 데이터를 참조할 수 없습니다.
- 데이터의 업로드 시간을 확인해 주세요. 3년 이상의 선행된 시간의 데이터는 저장되지 않습니다. 업로드된 데이터가 과거 데이터인 경우, 저장 범위가 커버하지 않을 가능성이 있습니다.### 데이터가 누락되거나 일부 속성이 수신되지 않음
- 속성 값이 사양을 준수하고, 한자나 공백 등의 문자를 포함하지 않도록 해주세요.
- 데이터 원칙을 준수하고, 사전 설정 속성만이 "#"로 시작하는 속성 이름이 되도록 확인해주세요.
- 누락된 속성 타입이 TE의 속성 타입과 동일한지 확인해주세요. 수신된 속성의 종류는 TE의 메타데이터 관리에서 확인할 수 있습니다.
# 데이터 전송 오류, 데이터를 삭제하고 싶음
- 개인 구축을 이용하는 경우, 데이터 삭제 도구를 사용하여 데이터를 삭제할 수 있습니다. SaaS를 이용하는 경우, 별도로 문의해주세요.
- 데이터가 크게 변경된 경우, 새로운 프로젝트를 직접 생성하는 것을 권장합니다. 또한, 테스트 프로젝트 아래에서 데이터 검증을 진행하는 것을 권장합니다.