# Cohorts
User cohorts is one of the tools provided by the system to subdivide users. A cohort can be understood as a set of users grouped together from the entire user population. You can create a cohort using a batch of users or a certain data condition (i.e., the rules for selecting users), and then use it in analysis and operation. Each cohort can subdivide users into two categories: belong to cohort and not belong to cohort.
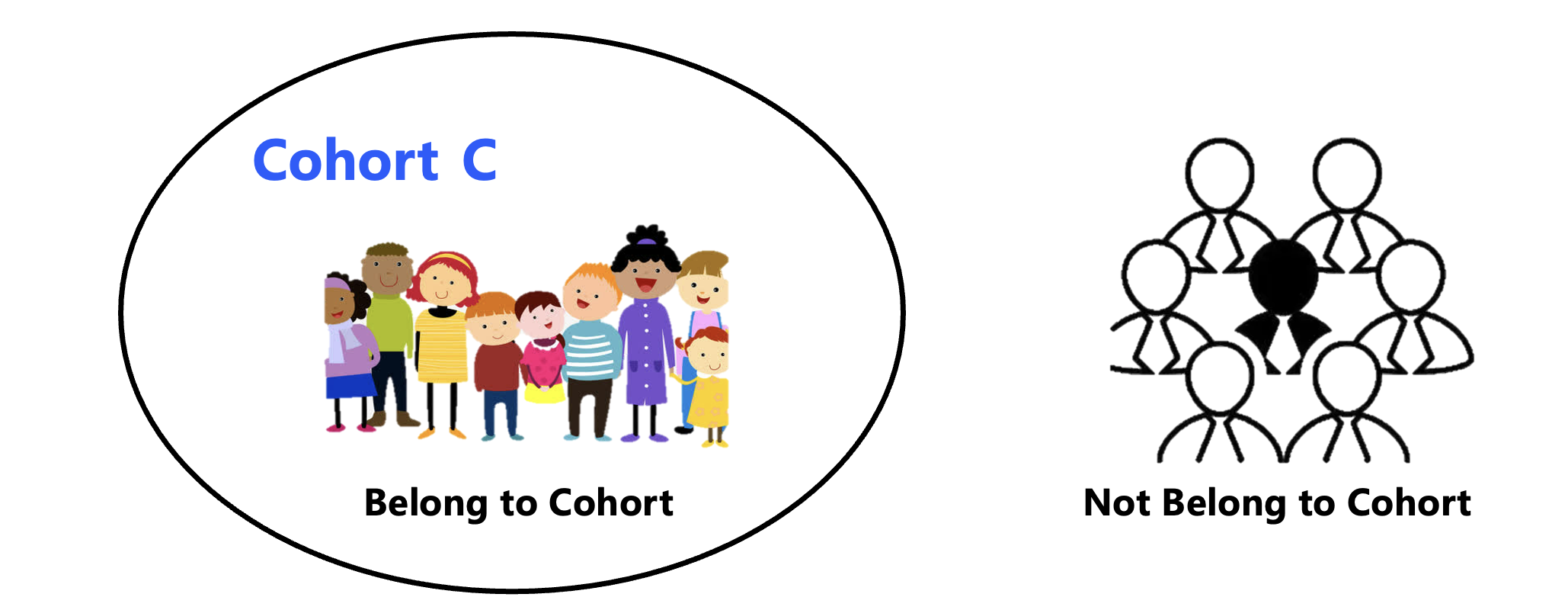
Compared with tags that label users, a cohort is more like selecting users into a highly dedicated set. Generally, it is recommended that a cohort be only used for one scenario. For example, the cohort of "users participating a certain campaign" can be used the influence of the campaign, while the cohort of "users obtaining more than 500 rewards points over the past 3 days" can be used for daily rewards issuance.
# Create cohort
At Users-Cohorts, you may create a 「behavioral cohort」, 「ID cohort」or 「SQL cohort」:
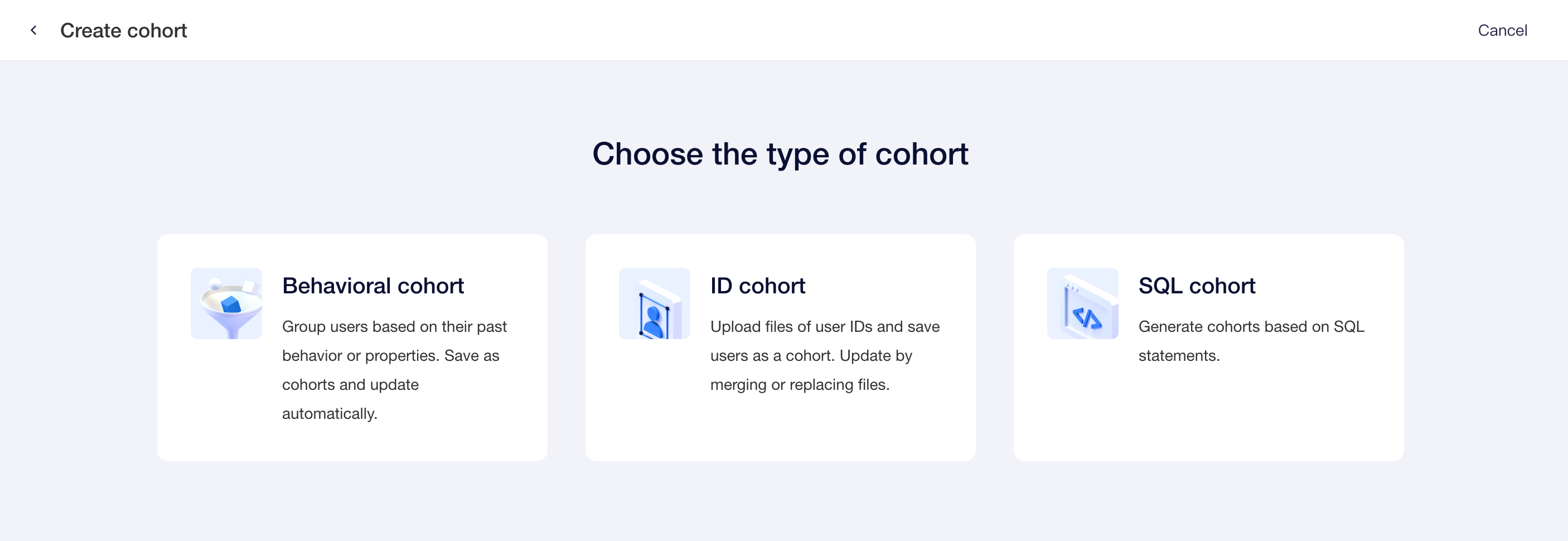
Create a「result cohort」in the result table of an analysis:

You can create a cohort using multiple methods. The comparisons of different types of cohorts are shown in the following table:
Definition mode | Cohort type | Description |
|---|---|---|
| ID set (Directly save the ID sets contained in a cohort as another cohort. The cohort defined in such a manner almost has no changes within the ranger of identifier). | ID cohort |
|
| Result cohort | The cohort created based on result data relating to the "number of individuals" in TE analytical or operational data tables. Generally, it is used for further drill-down analysis of analytical results or refined operation of users with exceptional data. For example, a cohort of "users who conducted additional purchases but did not make payments during the promotional campaign on December 25" can be created to analyze the conversion outcomes of these users during the campaign. By default, the upper limit of the number of personally created is 50. | |
| Data condition (Computational rules are saved as the cohort definition. In each rule-based computation, whether a user should be incorporated into the cohort is determined by whether the current rules are met. By default, the upper limit of the number of projects for cohort of this kind is 200.) | Behavioral cohort |
|
| SQL cohort |
|
When you create a cohort, you also need to select user entities and timezone of the cohort apart from its ID set or data conditions.
User identities
A cohort is a tool to subdivide users, while "user" identifiers are numerous, such as device, account, role and platform IDs. In project configuration, you may add user identifiers (properties) other than user IDs as user entities. These user entities can also be subdivided by cohort.
When creating a cohort, user entities should be selected; the computation result will be the set of such user entities, and the "number of individuals" in the cohort that you see is also the number of user entities. Please note that when event properties are selected as user entities, a behavioral cohort can not use such conditions as 「Have not done」or 「Have not done in sequence」.
Timezone
When multiple timezone switches are turned on in your project (project settings), you also need to first select the settlement timezone for your cohort when creating it. If event data is used in definitions of behavioral or SQL cohort, the time range in the defaulted event condition is the time range of the cohort timezone; if a reported event entails another timezone, the timezone offset will be first performed before determining whether event conditions are met.
Please note that if a different timezone is selected when viewing dashboards and reports, the cohort data being used is estimated results and the settlement timezone will not be changed accordingly.
# Update cohort
A cohort is pre-computed data (differing from ad-hoc queries). That is to say, the system will pre-compute cohort and then use result data in subsequent analysis and operation instead of computing the cohort in an ad-hoc manner every time the cohort is used. Pre-computation significantly reduces the complexity and repeatability of computation, thereby increasing the efficiency of data use. However, the timeliness of data will also be undermined (for cohorts defined by data conditions). For the majority of analytical scenarios, cohorts updated with a daily granularity can simply meet the needs. The operational scenarios, however, have higher requirements on cohort timeliness.
Behavioral and SQL cohorts are cohorts defined by data conditions. The system supports multiple update modes, as described below:
Update Mode | Description |
|---|---|
| Scheduled |
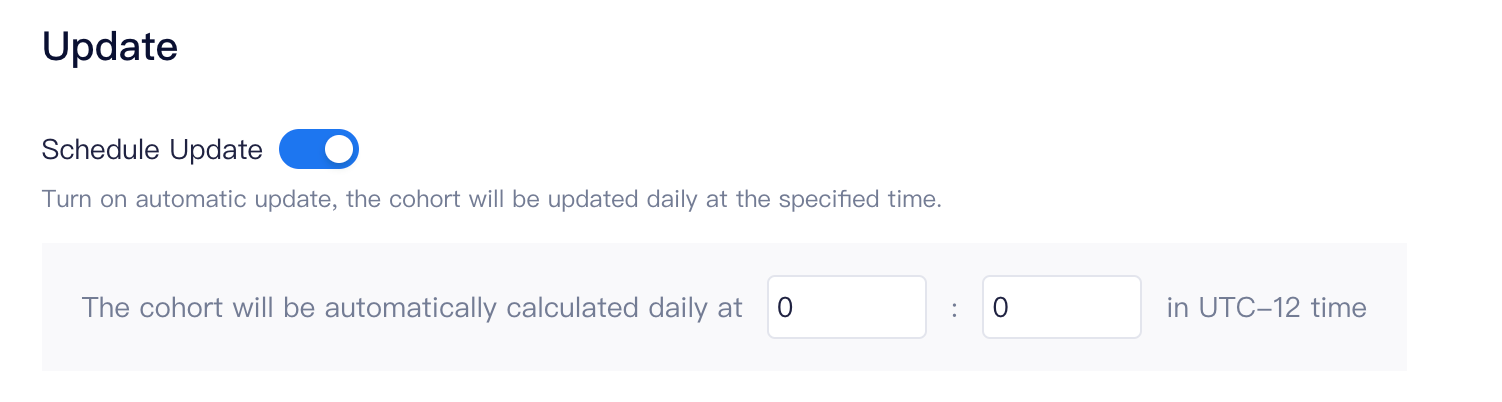
When creating or editing a behavioral or SQL cohort, if you enable the auto update button, the system will automatically update the cohort daily at the pre-scheduled time. Such an update mode is not supported by ID and result cohorts.
 |
| Manual | Behavioral and SQL cohorts can be updated manually. If you need cohort data, you may manually trigger an update. ID cohorts are updated by re-importing new files. Manual update is not supported by result cohort.  |
| Update with Dependents | If an Engage Task uses this cohort to create a Custom Cohort, a calculation will be performed before the push.  |
| System trigger | Cohort update triggered by other features of the system. If your project has deployed the operation module, the system will automatically trigger cohort updates based on the configuration of operation tasks. |
| Create computation | Upon the creation of all cohorts, computation will be immediately executed. |
| Edit computation | After changes of conditions and timezone of a behavioral cohort are saved, computation will be immediately executed. |
Please be noted that user and event data in the system are updated in real time. You can use the "Today" event condition in cohort definition so that only today's data as of the time of computation is used. If you need to use the data of an entire day, please use event condition as of the previous day.
# Manage cohort
Cohorts created under the analysis, operation, user and API modules can all be viewed from User-User Cohort interface. If the cohort creation module allows the cohort to be managed openly, you can also delete, update and edit a cohort from the module.
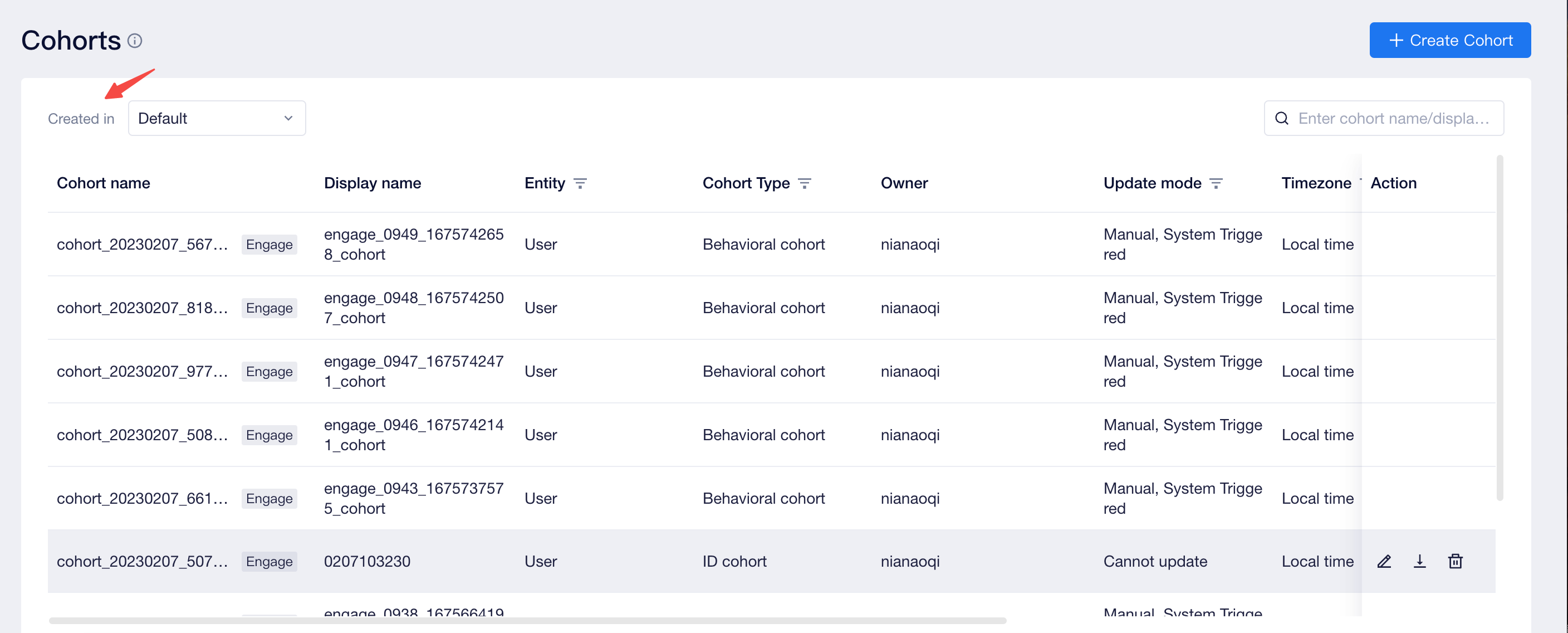
In cohorts, you can create sources to rapidly filter cohorts created by analysis, operation and API modules, and the sources of creation of non-user modules will also be labeled behind cohort names in order to facilitate lookup.
Management operations that can be implemented in cohorts are as follows. Different management operations have different requirements on cohort type, settings and operator permissions, as shown in the following table:
| Management operation | A management operation can be implemented when the following conditions are simultaneously met |
|---|---|
| Manual update  |
|
Edit cohort
 |
|
| Download imported data and errors  |
|
| Create copy | Behavioral cohort, SQL cohort Viewers have the permission to create new cohorts, edit and delete cohorts |
| Delete cohort |
|
As the cohort can be used by assets like reports, cohorts (created by the operation module) and alert, modification and deletion of the cohort may lead to exceptional volatility of data of these assets and even an inability of computation. When the deleted or edited cohort is reliant upon an asset, its scope of impact will be notified and the operator should judge influences first before proceeding with the ongoing operation.
# User list of cohort
Following cohort computation, you can view the number of users in the current cohort; you may also click the number of users to view the list of users of the current cohort.

In the user list, the definition of cohort conditions (behavioral cohort or SQL cohort) and user list can be viewed. The table displays a maximum of 1,000 lines of user data. If you need more data to be displayed, click the download button on the upper right corner of the table. A maximum of 500,000 rows of user data can be downloaded.
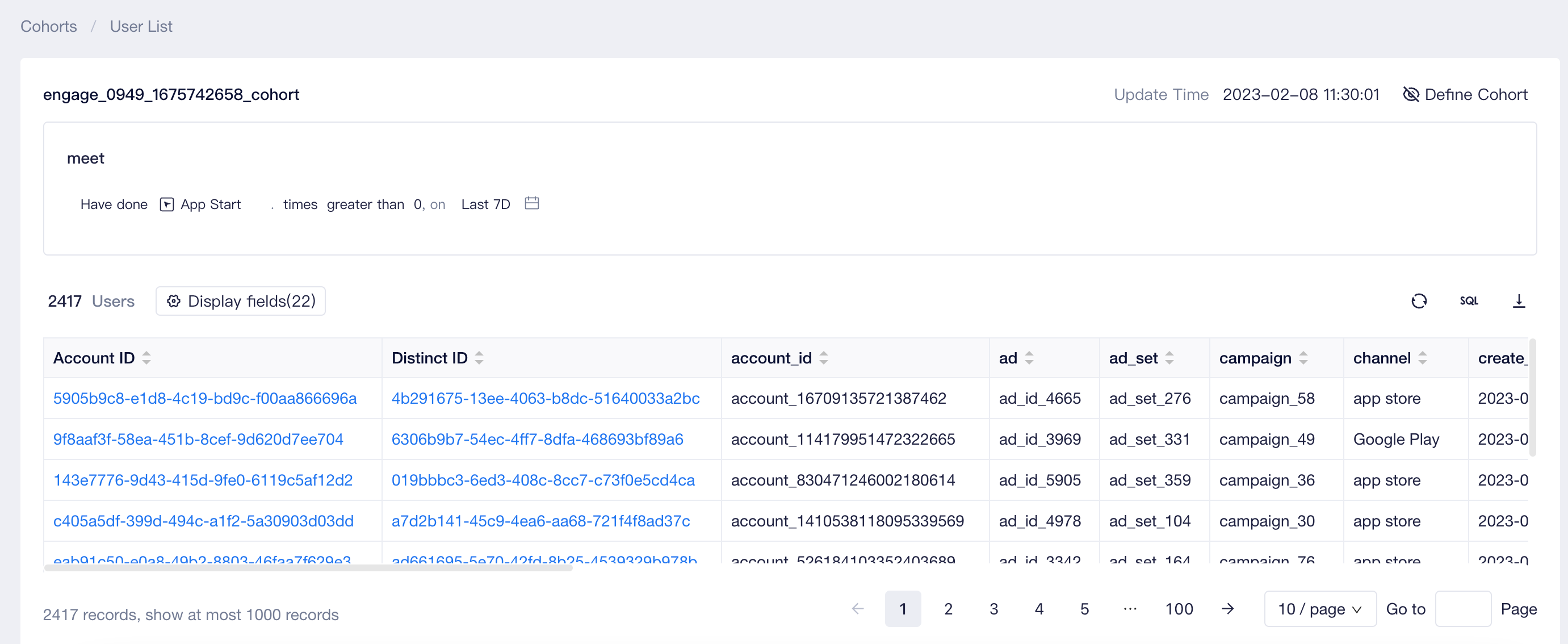
Please note that clicking the 「update」 on the upper right corner of the table on the user list page will only trigger re-query of cohort results instead of re-computing the cohort itself. However, the user property data of the cohort will change.
# User permissions
- Analysis roles
Company Root | Admin | Analyst | Regular Member | |
|---|---|---|---|---|
| View cohort list | ● | ● | ● | ○ |
| Create new, edit, delete self-created behavioral/ID cohort | ● | ● | △ | ○ |
| Create new, edit and delete self-created SQL cohort | ● | ● | △ | ○ |
| Create new, edit and delete self-created result cohort | ● | ● | ▲ | ○ |
| Edit and delete cohorts created by others | ● | △ | ○ | ○ |
- Operation roles
Operation admin | Operation | Data engineer | |
|---|---|---|---|
| View cohort list | ● | ▲ | △ |
| Create new, edit, delete self-created behavioral/ID cohort | ● | ▲ | △ |
| Cohort drill-down - view user list | ● | ▲ | △ |
Description of permissions:
● Compulsory availability for roles
▲Availability by default for roles, but unavailability is allowed
△ Unavailability for roles by default, but availability is allowed
○ Compulsory unavailability for roles