# Preparations before Data Ingestion
TIP
The section of Basic knowledge offers TE data rules that must be understood before data ingestion.
The section of Information required data ingestion has listed the system parameters that should be configured before data ingestion.
The TE (ThinkingEngine) system provides a full-end data ingestion scheme.
Generally speaking, one has to complete three steps before accessing TE: firstly, sorting out the data tracking scheme based on service requirements. Analysts of Thinking data would help you finish the task; secondly, the R&D staff should complete data ingestion according to the data tracking scheme; finally, the correctness of data ingestion should be verified. The data ingestion procedure is shown in the following figure:
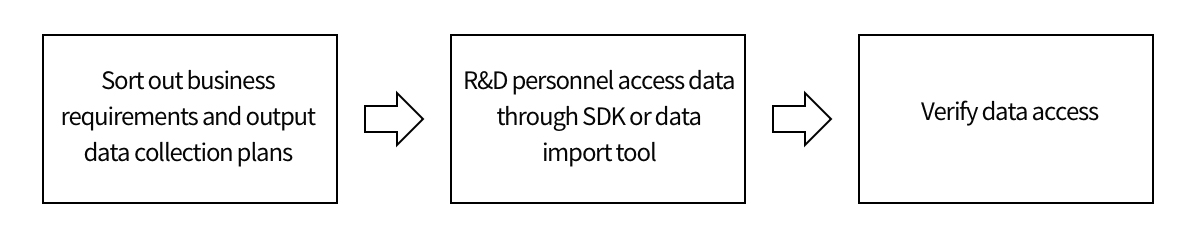
It is important to understand the basic knowledge about the TE system before data ingestion. This document would offer an overall introduction to the knowledge related to data ingestion. Meanwhile, it would also specify how to obtain help when you want to gain more information.
This document is targeted at all colleagues who participated in data ingestion, including business personnel, R&D staff, testing personnel, etc.
# I. Overview
TE provides a full-end data ingestion scheme, introducing the following major ingestion methods:
- Client SDK: able to track device information and user behavior information having no communication with the server, which is easy to use
- Server SDK: more accurate content tracking; applicable to core service data tracking
- Data import tool: used for importing historical data in general situations; combining the server-side SDK with LogBus is also a frequently used server-side data tracking scheme
For general apps and Web development, we provide:
- React Native SDK quick start guide
- Flutter SDK quick start guide
- Original SDK: Android SDK, iOS SDK
- Third-party framework: Flutter, Reactive Native
- H5 development:JavaScript SDK, H5 and original SDK connection
For the development of mini-games, we provide:
- Support from mainstream game engines: Cocos Creator
For the development of mobile games, we provide:
As for the service-side tracking scheme, we recommend the scheme of Server SDK+ Logbus. This scheme has robust performance in terms of the stability, timeliness and efficiency of data importing.
If you need to import certain historical heterogeneous data or supplement some data into the TE system, you can import the data with DataX. Different from the Logbus scheme, DataX is not a resident service. The timeliness of data could not be ensured for the generation of new data could not be monitored and new data could not be imported timely. The advantage of DataX is its ability to import the heterogeneous data of multiple data sources with simple operations.
If you have used Filebeat and Logstash to collect logs and want to import log data into the TE system, you can use Filebeat +Logstash scheme.
You can choose the scheme that is suitable for the technical structure and service requirements of your products according to the status quo of your business when designing the data tracking scheme. If you have any questions about the tracking scheme, please consult our analysts or technical support colleague in the support group chat.
# II. Basic Knowledge
# 2.1 TE data model
Before data ingestion, we need to understand what is the data in TE.
Indeed, designing data tracking scheme is a process of determining which user behavior event should be collected according to the objectives of service analysis. For example, if we need to analyze the status quo of user recharging, we need to track the payment behavior data of users. User behavior data can be divided into who, when, where, how and what, as shown in the following figure:
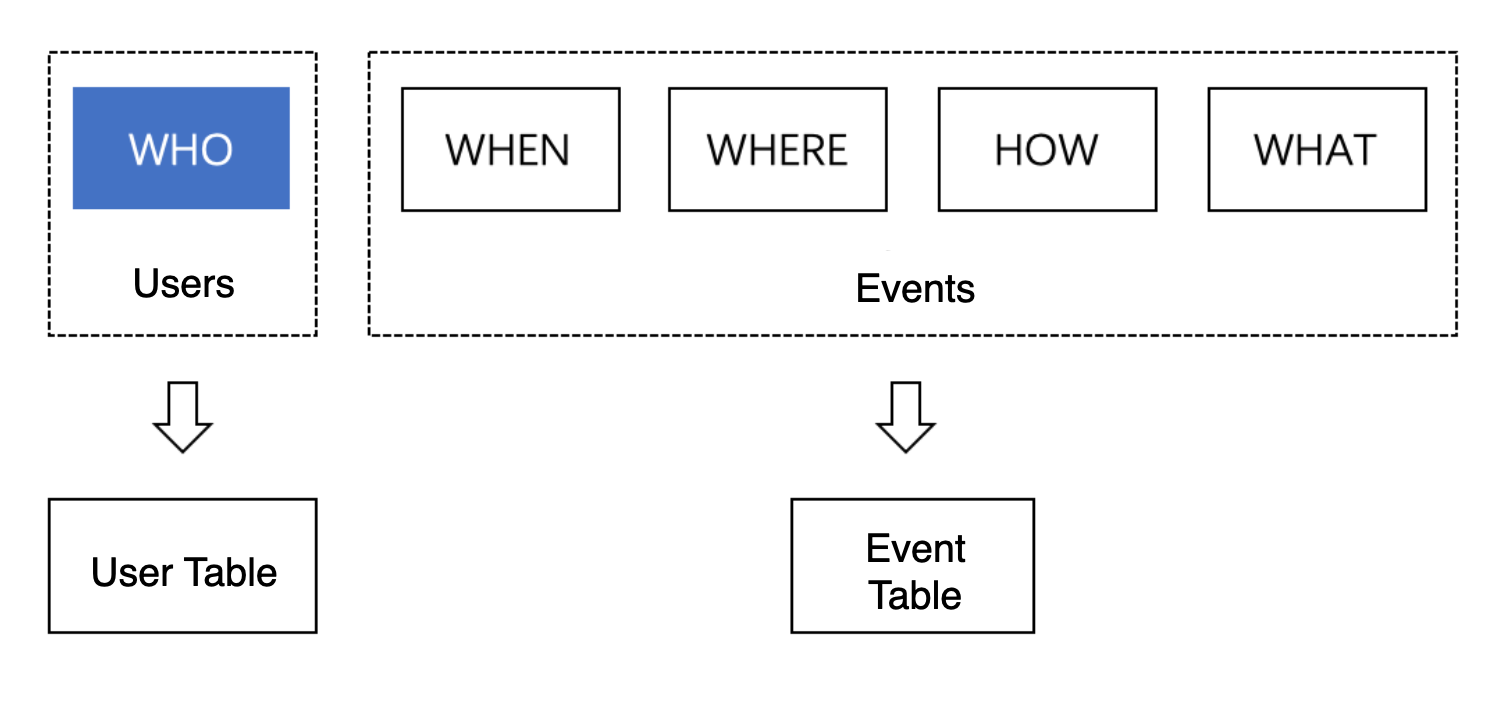
User behavior data could be organized as user-related data and event-related data in TE and stored in the user table and list table respectively. User data could mainly be used to describe the user state and properties that would not change frequently. Event data is used to describe information related to specific behavior events.
In the data tracking scheme, you should determine when should user data tracking be triggered and when should event tracking be triggered.
All of our data ingestion guidance would introduce the method for tracking event data and user data respectively.
# 2.2 User identification rules
It should be clarified to which user each piece of user data or event data belongs. In scenarios without an account system, the ID related to the device could be used as the unique identifier of the user. However, in scenarios with an account system, a user may generate data on multiple devices. Therefore, the data in multiple terminals should be included in the analysis, which does not apply to the unique ID related to devices.
To handle the above two scenarios, two user Ids should be used in the data ingestion process of identifier users:
- Distinct ID (#distinct_id): the client side would generate a random distinct ID by default to identify users. It also provides an interface to read and modify default distinct IDs.
- Account ID (#account_id): when the client logs in, the account ID could be set. The data in multiple devices could be correlated through the account ID.
Each piece of data must contain a distinct ID or account ID. A distinct ID could be generated by the client-side SDK by default. After you call the login interface to set the account ID, all the data would carry distinct ID and account ID simultaneously during the data tracking process. You need to upload at least one of account ID and distinct ID when tracking data through the server.
In the TE background, the unique ID of a user should be identified as the TE user ID (#user_id field). When receiving the data, we will create a new user according to specific User identification Rules, or bind the data with an existing user.
User identification rules are very important. If the user ID is not set correctly, the data might be bound with the wrong user, which would undermine the analysis effect. Please read the rules carefully before data ingestion and specify the user identification scheme in the data tracking scheme.
# 2.3 Data format
No matter which method is applied for data ingestion, the unified data format, and the same data restrictions should be used to send data to the receiving end. Chapter data rules offer a detailed description of the data format and corresponding data restrictions.
When connecting data through SDK, you only need to call the corresponding interface. SDK would process the data with the required format before reporting the data. If you connect data through data import tools or Restful API, you need to collate the data format according to the description in Data Rules before reporting the data.
Special attention should be paid to the naming rules and data type to ensure that the data format conforms to relevant requirements.
- Naming rules: the event name and property name both could only contain letters, figures, and underline _, starting with letters with a maximum length of 50 characters
Note: The property name is insensitive to the upper case and lower case, while the event name is sensitive to the upper and lower case.
- Data type of property value
| TE data type | Sample value | Instructions on values | Type of data |
|---|---|---|---|
| Numerical value | 123,1.23 | Data range: -9E15 to 9E15 | Number |
| Text | "ABC","Shanghai" | The upper limit of characters is 2KB by default | String |
| Time | "2019-01-01 00:00:00","2019-01-01 00:00:00.000" | "yyyy-MM-dd HH:mm:ss.SSS” or "yyyy-MM-dd HH:mm:ss". If it is necessary to indicate the date, "yyyy-MM-dd 00:00:00” could be used | String |
| Boolean | true,false | - | Boolean |
| List | ["a","1","true"] | Elements in the list would all be converted into character strings, with at most 500 elements in the list | Array(String) |
| Object | {hero_name:"Liu Bei",hero_level:22,hero_equipment: {"hero_name":"Liu Bei","hero_level":22,"hero_equipment": ["Male and female swords","Delu"],"hero_if_support":False} | Each sub-property (Key) in the object has its own data type. For detailed instructions on the values, please refer to the general properties of the corresponding above-mentioned types. There are at most 100 sub-properties inside the object | Object |
| Object group | {hero_name:"Liu Bei",hero_level:22,hero_equipment: ["Male and female swords","Delu"],"hero_if_support":False}, {"hero_name":"Liu Bei","hero_level":22,"hero_equipment": ["Male and female swords","Delu"],"hero_if_support":False}] | Each sub-property (Key) in the object has its own data type. For detailed instructions on the values, please refer to the general properties of the corresponding above-mentioned types. There are at most 500 OBJECTS inside the object group | Array(Object) |
In the TE background, you may notice that certain property names start with #, which is used as preset properties. It is unnecessary to set preset properties especially. SDK would track such properties by default. For detailed information, please refer to Preset properties and system fields.
You should be especially noted that when the data format or type is not set correctly, the data could not be stored. Therefore, during and after the data ingestion process, you may need to verify or observe the correctness of data tracking through the Tracking plan module and modify the problems that occurred timely.
# III. Information Required for Data Ingestion
Before the R&D staff performs data ingestion officially, you should ensure the following information has been obtained:
- Project APP ID: when you create a project in the TE background, the APP ID of the project would be generated, which could be checked on the project management page.
- Confirm the address of the data receiving end
If you are using a SaaS version, please check the receiver URL on this page
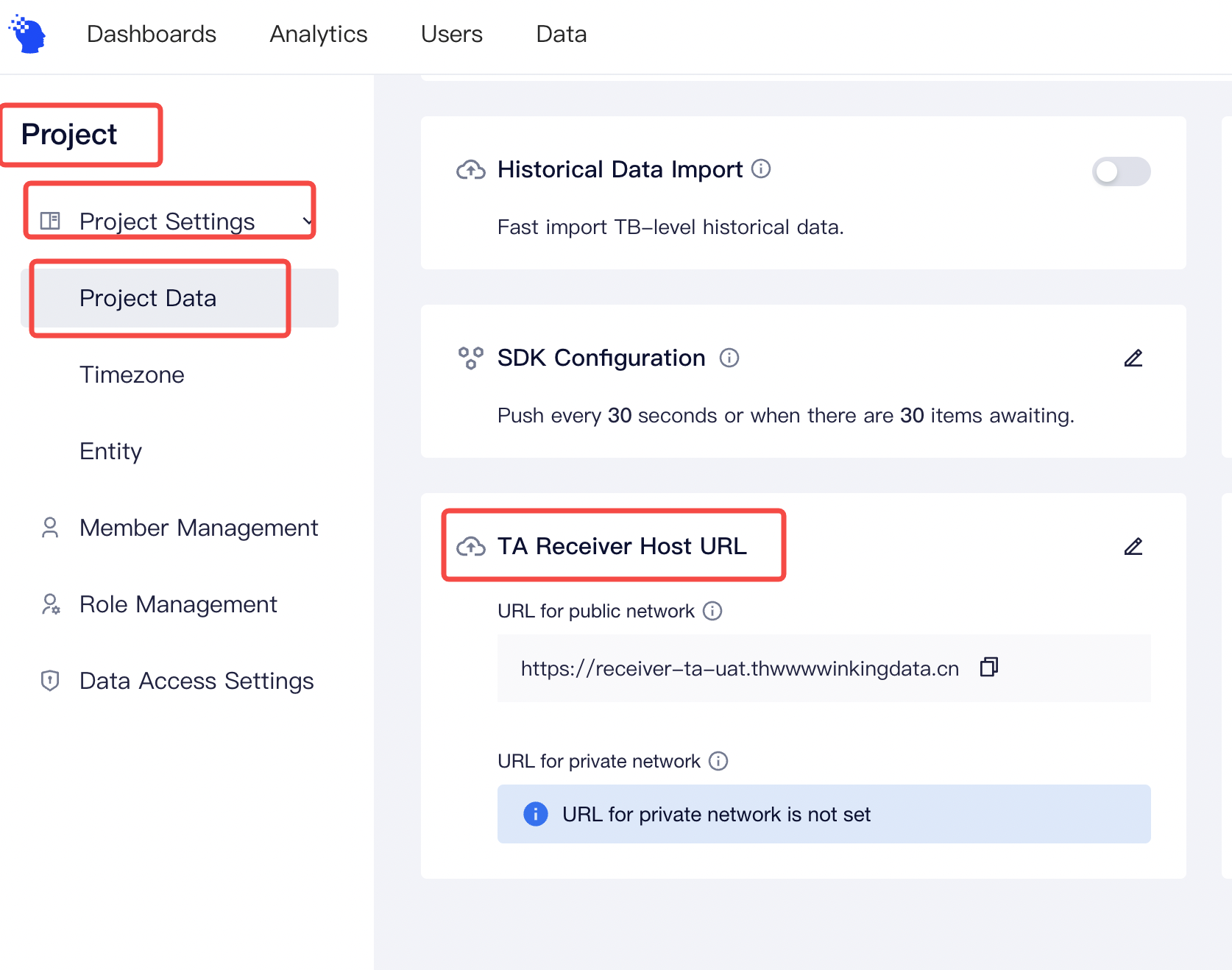
If you use the private deployment version, you can customize the data tracking URL .
- Verify the address of the receiving end: visit https://YOUR_RECEIVER_URL/health-check with the browser. If the page returns ok, it means the address is right.
- Data tracking scheme should include:
- Data ingestion method: client-side SDK. Server SDK, data import tool, or methods combining several schemes
- Content and trigger time of data to be ingested
You have finished reading the document of preparation before data ingestion. Congratulations. Now, you can perform data ingestion according to the method selected by referring to the corresponding data ingestion guidance.