# LogBus 使用指南
本节主要介绍数据传输工具 LogBus 的使用方法:
LogBus Windows 版本请阅读LogBus Windows 版本使用指南
在开始对接前,您需要先阅读数据规则,在熟悉 TA 的数据格式与数据规则后,再阅读本指南进行对接。
LogBus 上传的数据必须遵循 TA 的数据格式
# 下载 LogBus
最新版本为: 1.5.17
更新时间为: 2022-11-08
Linux arm版本下载地址 (opens new window)
版本升级说明:
- 1.5.0 以上版本:
先执行./logbus stop命令停止 LogBus,等停止完毕后再执行./logbus update命令升级至最新版本
- 如果您使用的是 1.5.0 之前版本,需要升级至新版本,请联系 TA 工作人员
# 一、LogBus 简介
LogBus 工具主要用于将后端的日志数据实时地导入到 TA 后台,其核心工作原理类似于 Flume,会监控服务器日志目录下的文件流,当目录下任意日志文件有新数据产生时,会对新数据进行校验,并实时发送至 TA 后台。
以下几类用户建议使用 LogBus 接入数据:
- 使用服务端 SDK 的用户,通过 LogBus 上传数据
- 对数据的准确性及维度要求较高,仅通过客户端 SDK 无法满足数据需求,或不方便接入客户端 SDK
- 不想自己开发后端数据推送流程
- 需要传输大批量历史数据
# 二、使用前数据准备
1.首先将需要传输的数据进行 ETL 转换成 TA 的数据格式,并写到本地或传输至 Kafka 集群,如果使用的是服务端 SDK 的写入本地文件或 Kafka 的 consumer,则数据已经是正确的格式,无需再进行转换。
2.确定上传数据的文件存放的目录,或者 Kafka 的地址与 topic,并配置 LogBus 的相关配置,LogBus 会监控文件目录下的文件变更(监控文件新建或 tail 已有文件),或者订阅 Kafka 中的数据。
3.请勿对存放于监控目录下且已经上传的数据日志直接进行重命名,重命名日志相当于新建文件,LogBus 将可能会重新上传这些文件,造成数据重复。
4.由于 LogBus 数据传输组件中包含数据缓冲区,LogBus 目录占磁盘可能会稍大,因此请确保 LogBus 安装节点的磁盘空间充足,每向一个项目(即增加一个 APP_ID)传输数据需预留至少 10G 的存储空间。
# 三、LogBus 的安装与升级
# 3.1 安装 LogBus
1.下载LogBus 压缩包 (opens new window),并解压。
2.解压后的目录结构:
- bin:启动程序文件夹
- conf:配置文件文件夹
- lib:功能文件夹
# 3.2 升级 LogBus
如果您使用的是 1.5.0 及之后的版本,可以先使用./logbus stop命令停止 LogBus,再执行./logbus update命令升级 LogBus 至最新版本,再重启 LogBus
# 3.3 docker 版本
如果您需要在docker容器中使用logbus,请参考LogBus docker使用指南 (opens new window)
# 四、LogBus 的参数配置
1.进入解压后的conf目录,里面有一个配置文件logBus.conf.Template,该文件包含 LogBus 所有的配置参数,首次使用时可将其重命名为logBus.conf。
2.打开logBus.conf文件进行相关参数配置
# 4.1 项目与数据源配置(必须配置)
- 项目 APP_ID
##APPID来自tga官网的token,请在TA后台的项目配置页面获取接入项目的APPID并填入此处,多个APPID通过","分割
APPID=APPID_1,APPID_2
- 监控文件配置(请选择其中一种,必须配置)
# 4.1.1.数据来源是本地文件时
##LogBus读取的数据文件所在的路径及文件名(文件名支持模糊匹配), 需要有读权限
##不同APPID用逗号隔开,相同APPID不同目录用空格隔开
##TAIL_FILE的文件名支持java标准的正则表达式和通配符两种模式
TAIL_FILE=/path1/dir*/log.* /path2/DATE{YYYYMMDD}/txt.*,/path3/txt.*
##TAIL_MATCHER指定TAIL_FILE的路径的模糊匹配模式 regex-正则 glob-通配符。
##regex为正则模式,支持使用java标准的正则表达式,但仅支持一层目录和文件名的模糊匹配
##glob为通配符模式,支持多层目录模糊匹配,不支持DATE{}格式的匹配
##默认使用regex正则表达式匹配
#TAIL_MATCHER=regex
TAIL_FILE 支持对多路径下的多分目录中的多个文件进行监控,下图是
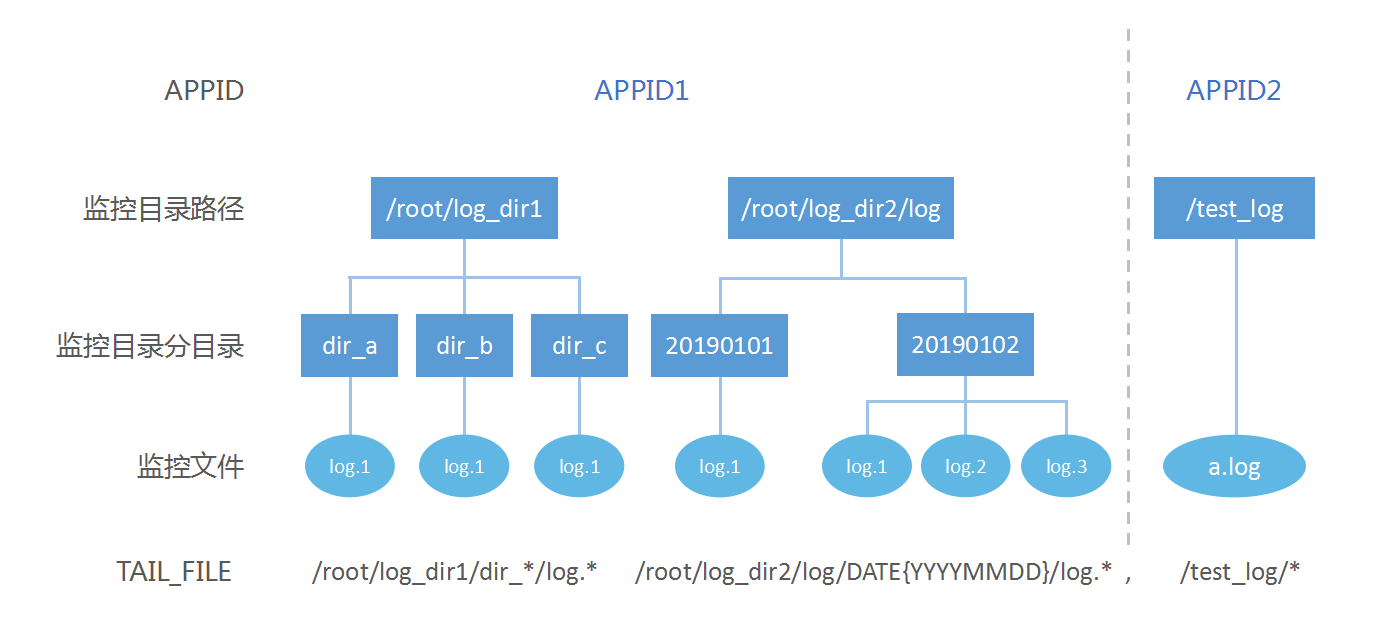
对应参数配置为:
APPID=APPID1,APPID2
TAIL_FILE=/root/log_dir1/dir_*/log.* /root/log_dir2/log/DATE{YYYYMMDD}/log.*,/test_log/*
具体规则如下:
- 同一 APP_ID 的多个监控路径通过空格分割
- 不同 APP_ID 的监控路径通过半角逗号分割,且按逗号分割后监控路径对应 APP_ID
- 监控路径中的分目录(即文件所在的目录)支持通过日期格式、正则表达式监控或通配符匹配
- 文件名支持使用正则表达式监控或通配符
请勿将需要监控的日志文件存放于服务器根目录。
日期格式分目录的规则(仅 regex 模式支持):
日期格式分目录需以DATE{}括起来日期模板,DATE 必须大写,以下举例几种可识别的日期模板以及对应监控的文件样例,但不限于此,日期模板只需是标准日期格式即可。
/root/logbus_data/DATE{YYYY-MM-DD}/log.*---> /root/logbus_data/2019-01-01/log.1/root/logbus_data/DATE{YYMMDD}/log.*---> /root/logbus_data/190101/log.1/root/logbus_data/DATE{MM_DD_YYYY}/log.*---> /root/logbus_data/01_01_2019/log.1/root/logbus_data/DATE{MMDD}/log.---> /root/logbus_data/01*01/log.1
# 4.1.2.数据来源为 kafka 时
从 1.5.2 版本后,参数KAFKA_TOPICS不再支持正则表达式,需监控多个 topic 时,可使用空格分隔各 topic;如存在多 APP_ID,则使用半角逗号分割各 APP_ID 监控的 topic。参数KAFKA_GROUPID必须唯一。1.5.3 版本新增参数KAFKA_OFFSET_RESET,可设置 Kafka 的kafka.consumer.auto.offset.reset参数,可取值为earliest与latest,默认设置为earliest。
注意:数据源的 Kafka 版本必须在 0.10.1.0 或更高
单 APP_ID 样例:
APPID=appid1
######kafka 配置
#KAFKA_GROUPID=tga.group
#KAFKA_SERVERS=localhost:9092
#KAFKA_TOPICS=topic1 topic2
#KAFKA_OFFSET_RESET=earliest
#可选云服务商:tencent/ali/huawei
#KAFKA_CLOUD_PROVIDER=
#KAFKA_INSTANCE=
#KAFKA_USERNAME=
#KAFKA_PASSWORD=
#SASL认证
#KAFKA_JAAS_PATH=
#KAFKA_SECURITY_PROTOCOL=
#KAFKA_SASL_MECHANISM=
多 APP_ID 样例:
APPID=appid1,appid2
######kafka 配置
#KAFKA_GROUPID=tga.group
#KAFKA_SERVERS=localhost:9092
#KAFKA_TOPICS=topic1 topic2,topic3 topic4
#KAFKA_OFFSET_RESET=earliest
#可选云服务商:tencent/ali/huawei
#KAFKA_CLOUD_PROVIDER=
#KAFKA_INSTANCE=
#KAFKA_USERNAME=
#KAFKA_PASSWORD=
#SASL认证
#KAFKA_JAAS_PATH=
#KAFKA_SECURITY_PROTOCOL=
#KAFKA_SASL_MECHANISM=
# 4.2 传输参数配置(必须配置)
##传输设置
##传送的url
##http传输请使用
PUSH_URL=https://global-receiver-ta.thinkingdata.cn/logbus
##如果您使用的是私有化部署服务,请修改传输URL为:http://数据采集地址/logbus
##是否开启检查appid,默认关闭
#IS_CHECK_APPID=false
##每次传输的最大数量
#BATCH=10000
##最少多久传一次(单位:秒)
#INTERVAL_SECONDS=60
##传输线程数,实际线程数为配置的线程数+1,默认两个线程
#NUMTHREAD=1
##是否在每条数据中增加uuid属性(开启会降低传输效率)
#IS_ADD_UUID=true
##文件传输的压缩格式:gzip,lzo,lz4,snappy,none
#COMPRESS_FORMAT=none
# 4.3 Flume 内存参数配置(可选配置)
# flume管道容量设置
# 管道容量,这里需要根据部署电脑的配置视情况而定。
CAPACITY=1000000
# 管道到sink的传输量,需大于BATCH参数
TRANSACTION_CAPACITY=10000
##指定flume启动的最大内存,单位为M。
#MAX_MEMORY=2048
# flume的channel设置,有file和memory两种(可选,默认使用file)
# CHANNEL_TYPE=file
# 4.4 监控文件删除配置(可选配置)
# 监控目录文件删除,去除注释即为启动删除文件功能
# 只能以按天(day)或按小时(hour)删除
# UNIT_REMOVE=hour
# 删除多久之前的文件
# OFFSET_REMOVE=20
# 删除已经上传的监控文件,每隔多少分钟删除
# FREQUENCY_REMOVE=60
# 4.5 自定义解析器(可选配置)
1.5.9 版本开始支持客户自定义数据解析器,用于原数据格式与 TA 数据格式不一致时自定义转换格式。
详情如下:
- 添加如下依赖
Maven:
<dependency>
<groupId>cn.thinkingdata.ta</groupId>
<artifactId>integration-common-api</artifactId>
<version>1.0.9</version>
</dependency>
Gradle:
// https://mvnrepository.com/artifact/cn.thinkingdata.ta/logbus-custom-interceptor
compile group: 'cn.thinkingdata.ta', name: 'integration-common-api', version: '1.0.9'
- 实现 CustomInterceptor 接口中的 transFrom 方法。方法中的第一个参数为原数据内容,第二个参数为 sourceName(用于需要区分 APP_ID 时使用。根据 APP_ID 区分,比如只配置一个 APP_ID,sourceName 为 r1,如果配置多个 APP_ID,sourceName 按顺序依次为 r1,r2 等)。transferToList方法可以将一条数据转为多条,使用需要在配置中增加INTERCEPTOR_ONE_TO_MORE=true,两个方法只能使用一个。
public interface CustomInterceptor {
TaDataDo transFrom(String var1, String var2) throws Exception;
List<TaDataDo> transferToList(String var1, String var2) throws Exception;
}
实现的接口方法例如:
public TaDataDo transFrom(String s, String s1) {
return JSONObject.parseObject(s, TaDataDo.class);
}
- 配置下面两个字段即可
##下面两个字段为使用自定义解析器(必须将两个字段都设置才可使用)
##自定义解析器全限定名(包名+类名),不设置则使用默认解析器
#CUSTOM_INTERCEPTOR=cn.thinkingdata.demo.DemoCustomInterceptor
##自定义解析器jar的绝对路径(包括jar包文件名)
#INTERCEPTOR_PATH=/var/interceptor/custom-interceptor-1.0-SNAPSHOT.jar
##如果需要将一条数据转为多条数据,需要开启下面字段配置
#INTERCEPTOR_ONE_TO_MORE=true
# 4.6 根据数据中的#app_id进行项目划分(可选配置)
注意:此功能需要TA版本3.1及以上
##1.5.14版本增加APPID_IN_DATA配置。在使用数据中的#app_id进行项目分发时,可配置APPID_IN_DATA=true。
##此时不需要配置APPID,TAIL_FILE也仅能配置一层。
##注意:TA版本至少需要3.1
#APPID_IN_DATA=false
# 4.7 根据配置自动分发到对应的项目(可选配置)
##1.5.14版本对之前的功能有所改动,需配合TA3.1及以上版本使用。
##指定需要映射的属性名称,例如name,需结合APPID_MAP字段使用
##APPID_MAP_ATTRIBUTE_NAME=name
##提供APPID和属性值的映射关系,例如如下配置表示数据的properties字段中的name字段值为a或b时,数据会把分发到appid_1中,为c和d时,会分发到appid_2中
##APPID_MAP={"appid_1":["a","b"],"appid_2":["c","d"]}
##DEFAULT_APPID表示数据中不存在name字段或者name字段的值不在上面配置中时分发的项目
##DEFAULT_APPID=appid_3
# 4.8 配置文件示例
##################################################################################
## thinkingdata数据分析平台传输工具logBus配置文件
##非注释的为必填参数,注释的为选填参数,可以根据你自身的情况进行
##合适的配置
##环境要求:java8+,更详细的要求请详见tga官网
##http://doc.thinkinggame.cn/tgamanual/installation/logbus_installation.html
##################################################################################
##APPID来自tga官网的token
##不同APPID用逗号隔开
APPID=from_tga1,from_tga2
#-----------------------------------source----------------------------------------
######file-source
##LogBus读取的数据文件所在的路径及文件名(文件名支持模糊匹配), 需要有读权限
##不同APPID用逗号隔开,相同APPID不同目录用空格隔开
##TAIL_FILE的文件名支持java标准的正则表达式和通配符两种模式
#TAIL_FILE=/path1/log.* /path2/txt.*,/path3/log.* /path4/log.* /path5/txt.*
##TAIL_MATCHER指定TAIL_FILE的路径的模糊匹配模式 regex-正则 glob-通配符。
##regex为正则模式,支持使用java标准的正则表达式,但仅支持一层目录和文件名的模糊匹配
##glob为通配符模式,支持多层目录模糊匹配,不支持DATE{}格式的匹配
##默认使用regex正则表达式匹配
#TAIL_MATCHER=regex
######kafka-source
##kafka,topics使用正则
#KAFKA_GROUPID=tga.flume
#KAFKA_SERVERS=ip:port
#KAFKA_TOPICS=topicName
#KAFKA_OFFSET_RESET=earliest/latest
#------------------------------------sink-----------------------------------------
##传输设置
##传送的url
##PUSH_URL=http://${数据采集地址}/logbus
##每次传输的最大数量(到达指定条数发送数据传输请求)
#BATCH=1000
##最少多久传一次(单位:秒)(时长到达,未满足batch数,把目前条数发送)
#INTERVAL_SECONDS=60
##### http传输
##文件传输的压缩格式:gzip,lzo,lz4,snappy,none
#COMPRESS_FORMAT=none
#------------------------------------other-----------------------------------------
##监控目录下文件删除,打开注释(必须将下面两个字段都打开)即为启动删除文件功能,每一个小时启动一次文件删除程序
##按unit删除offet之前的文件
##删除多久之前的文件
#OFFSET_REMOVE=
##只接收按天(day)或小时(hour)删除
#UNIT_REMOVE=
#------------------------------------interceptor-----------------------------------
##下面两个字段为使用自定义解析器(必须将两个字段都设置才可使用)
##自定义解析器全限定名,不设置则使用默认解析器
#CUSTOM_INTERCEPTOR=
##自定义解析器jar位置
#INTERCEPTOR_PATH=
# 五、启动 LogBus
在首次启动前请进行以下检查:
1.检查 java 版本
进入bin目录,里面会有两个脚本,check_java与logbus
其中check_java用于检测 java 版本是否满足要求,执行脚本,若 java 版本不满足会出现Java version is less than 1.8或Can't find java, please install jre first.等提示
您可以更新 JDK 版本或查看下一节中的内容为 LogBus 单独安装 JDK
2.安装 LogBus 的独立 JDK
如果 LogBus 部署节点,由于环境关系,JDK 版本不满足 LogBus 需求,又无法替换成满足 LogBus 的 JDK 版本。可以使用此功能。
进入bin目录,里面会有install_logbus_jdk.sh。
运行此脚本会在 LogBus 工作目录新增出 java 目录。LogBus 会默认使用这个目录下的 JDK 环境。
3.完成 logBus.conf 的配置,并运行参数环境检查命令
logBus.conf 的配置请参考配置 LogBus一节
配置完成后运行 env 命令,检查配置参数是否正确
./logbus env
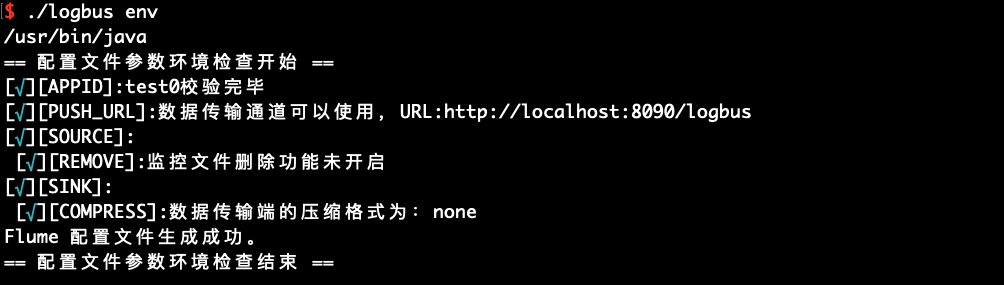
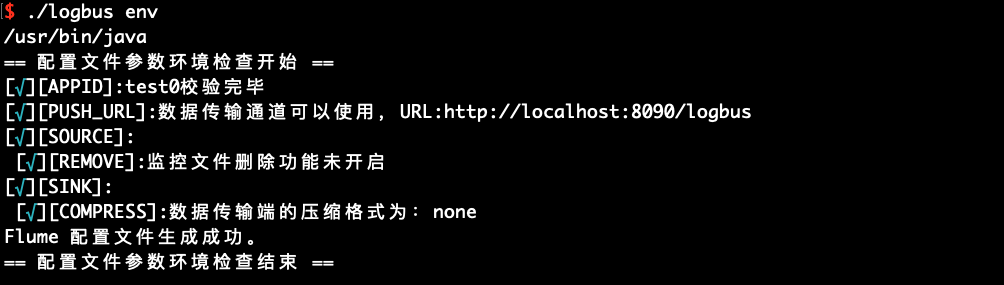
如果输出红色异常信息,说明配置有问题,需要重新修改,直到配置文件没有异常的提示,如上图所示。
当您修改了 logBus.conf 的配置后,需要重启 LogBus 以使新配置生效
4.启动 LogBus
./logbus start
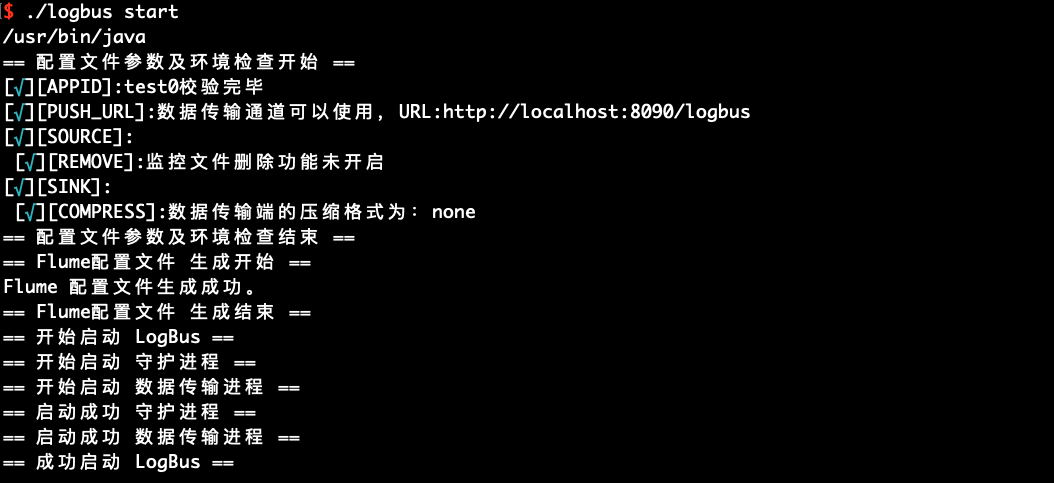
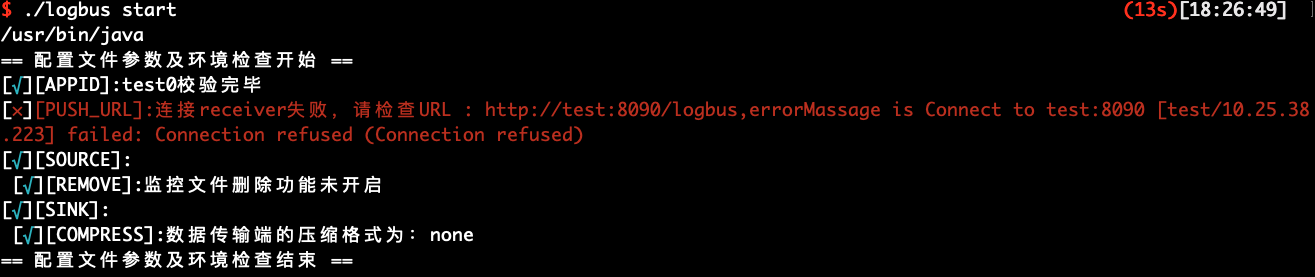
启动成功会有上图中的提示,失败则会提示异常信息,如下图
# 六、LogBus 命令详解
# 6.1 帮助信息
不带参数或--help 或-h,将会显示如下的帮助信息
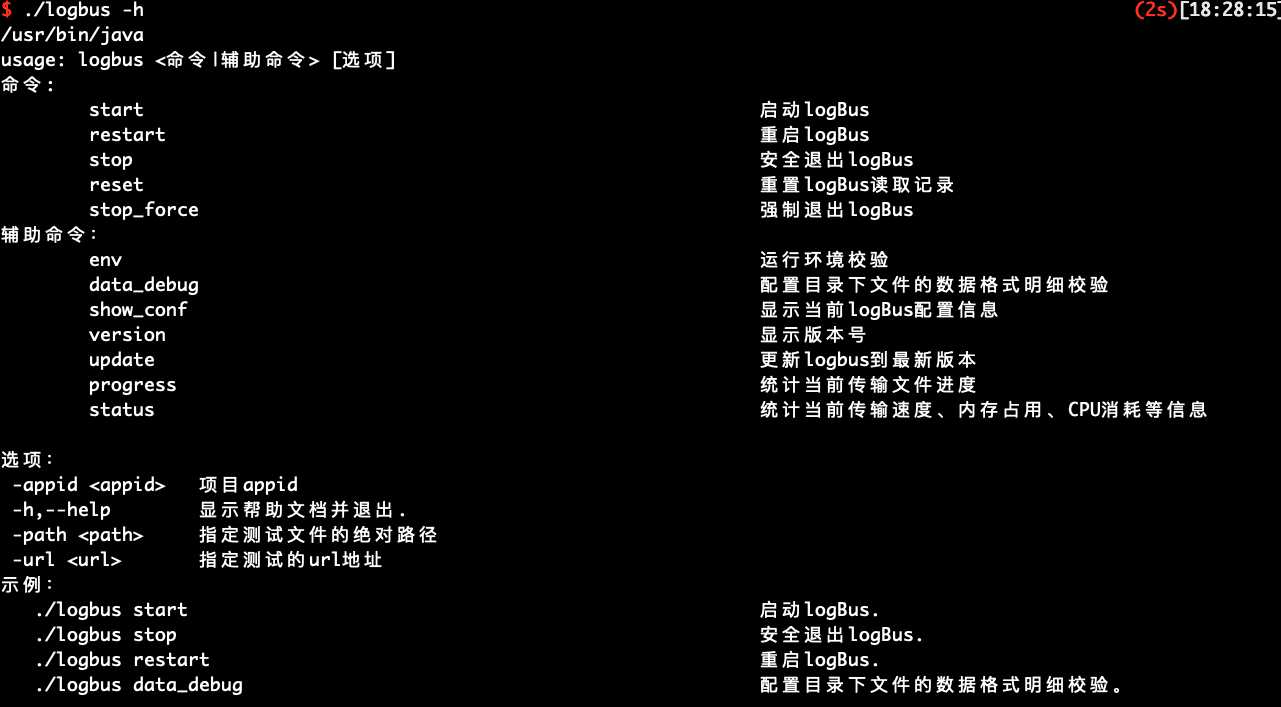
主要介绍 LogBus 的命令:
usage: logbus <命令|辅助命令> [选项]
命令:
start 启动logBus.
restart 重启logBus.
stop 安全退出logBus.
reset 重置logBus读取记录.
stop_force 强制退出logBus.
辅助命令:
env 运行环境校验.
data_debug 配置目录下文件的数据格式明细校验.
show_conf 显示当前logBus配置信息.
version 显示版本号.
update 更新logbus到最新版本.
progress 统计当前传输文件进度
status 统计当前传输速度、内存占用、CPU消耗等信息
选项:
-appid <appid> 项目appid
-h,--help 显示帮助文档并退出.
-path <path> 指定测试文件的绝对路径
-url <url> 指定测试的url地址
示例:
./logbus start 启动logBus.
./logbus stop 安全退出logBus.
./logbus restart 重启logBus.
./logbus data_debug 配置目录下文件的数据格式明细校验.
# 6.2 文件数据格式检查data_debug
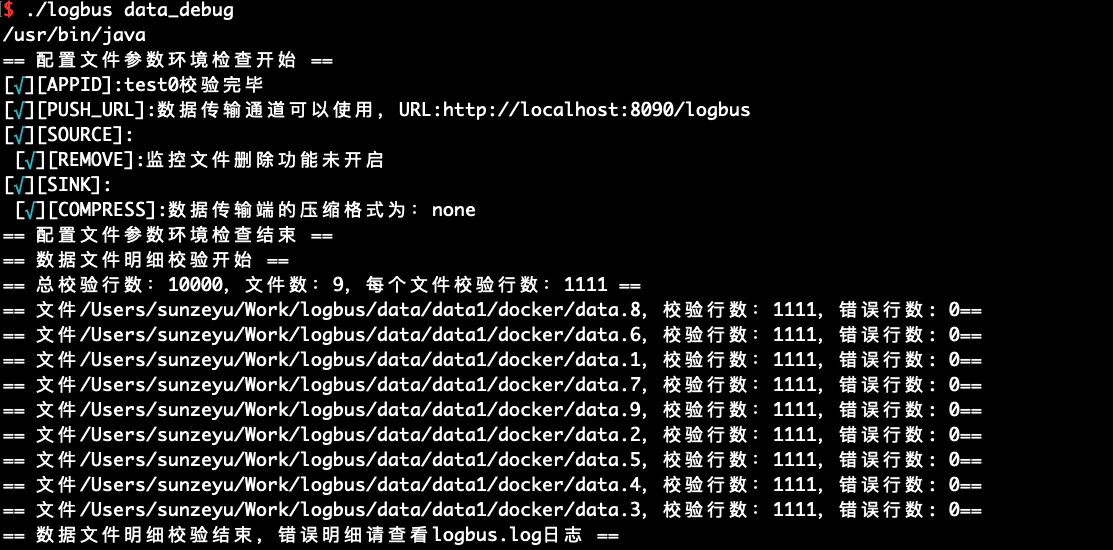
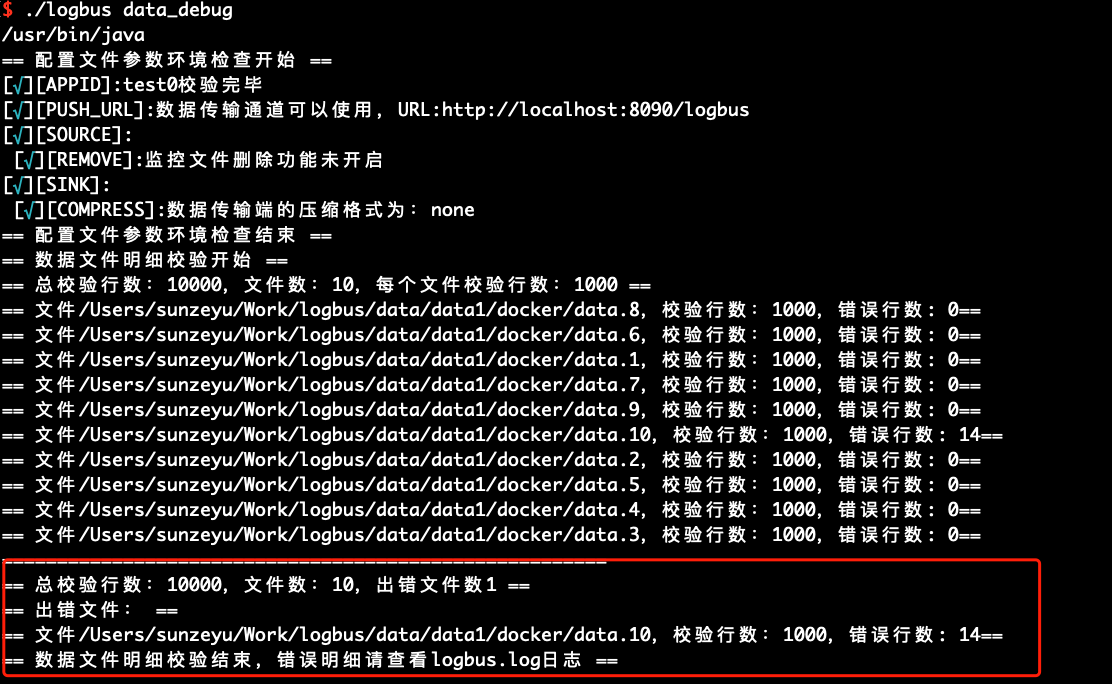
当您首次使用 LogBus 时,我们建议您在正式上传数据前,先对您的数据进行格式校验,数据必须符合数据格式规范,您可以使用data_debug命令来进行数据格式校验,如下:
此功能会消耗集群资源,每次限定 10000 条,每个文件平分校验量,从文件头优先校验。
./logbus data_debug
当数据格式正确时,将会提示数据正确,如下图:
如果数据格式存在问题,则会警告格式错误,并简述格式的错误点:
# 6.3 展示配置信息show_conf
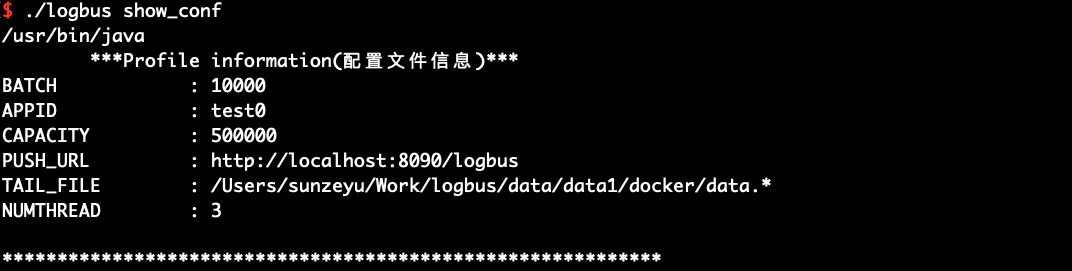
您可以使用show_conf命令来查看 LogBus 的配置信息,展示内容如下图所示:
./logbus show_conf
# 6.4 启动环境检查env
您可以使用env进行启动环境的检查,如果输出的信息后面带有星号,就说明配置有问题,需要重新修改,直至没有星号提示。
./logbus env
# 6.5 启动start
当您完成格式的校验、数据通道的检查以及环境检查后,即可启动 LogBus 进行数据的上传,LogBus 将会自动检测您的文件是否有新数据写入,如果有新数据,则将数据进行上传。
./logbus start
# 6.6 停止stop
如果您想要停止 LogBus。请使用stop命令,该命需要花费一定时间,但不会有数据损失。
./logbus stop

# 6.7 停止stop_force
如果您想要立刻停止 LogBus,请使用stop_force命令,该命令可能导致数据丢失。
./logbus stop_force
# 6.8 重启restart
您可以使用restart命令重启 LogBus,适合在修改配置参数后使新配置生效。
./logbus restart
# 6.9 重置reset
使用reset将会重置 LogBus,请务必谨慎使用该命令,一旦使用将会清空文件传输记录,LogBus 将会重新上传所有数据。如果您在不明确的条件下使用该命令,可能导致您的数据出现重复。建议在与 TA 工作人员沟通后再进行使用。
./logbus reset
使用重置命令后,需要执行start重新开始传输数据
LogBus 1.5.0 版本后,添加如下确认信息,确认后才会开始重置 LogBus

# 6.10 查看版本号version
如果您想要了解您所使用的 LogBus 的版本号,可以使用version命令,如果您的 LogBus 没有该命令,则您所使用的版本属于早期版本
./logbus version
# 6.11 升级 logBus 版本update
LogBus 1.5.0 版本,新增了在线更新版本的功能,执行该命令可升级 LogBus 至最新版本
./logbus update
# 6.12 查看当前上传进度progress
LogBus 1.5.9 版本,新增了查看当前上传进度的功能,执行该命令可以查询当前传输进度,可以使用-appid 指定项目,也可以直接加上文件全路径名指定查询。
./logbus progress /data/logbus-1.log /data/logbus-2.log -appid {APPID}
# 6.13 检查 logBus 常见问题doctor
LogBus 1.5.12 版本,新增了检查 logBus 常见问题的命令,执行该命令可以查看当前 logBus 是否存在问题
./logbus doctor
# 6.14 查看 logBus 当前上传速度及状态status
LogBus 1.5.13 版本,查看 logBus 当前上传速度及状态的命令,执行该命令可以查看当前 logBus 上传速度及状态
./logbus status
# 七、ChangeLog
# 版本 1.5.17 --- 2022/11/08
新增:
- 支持自定义解析器一转多
# 版本 1.5.16.2 --- 2022/07/05
修复:
- 因旧版本fastjson漏洞,升级版本至1.2.83
# 版本 1.5.16.1 --- 2022/05/24
修复:
- 因旧版本fastjson漏洞,升级版本至1.2.80
# 版本 1.5.16 --- 2022/04/01
优化:
- 优化异构数据的功能支持
# 版本 1.5.15.7 --- 2021/12/10
修复:
- 因旧版本log4j漏洞,升级版本至2.15.0
# 版本 1.5.15.6 --- 2021/12/06
新增:
- 实例配置中增加Kafka配置项
# 版本 1.5.15.5 --- 2021/12/02
新增:
- Kafka增加SASL验证
# 版本 1.5.15.4 --- 2021/11/23
修复:
- 修复某些情况下升级异常的错误
# 版本 1.5.15.3 --- 2021/11/19
修复:
- 修复某些情况下未检查appid的错误
# 版本 1.5.15.2 --- 2021/10/15
修复:
- 修复若干问题
优化:
- 优化LogBus关闭流程
# 版本 1.5.15.1 --- 2021/08/17
修复:
- 修复Kafka源读取数据的一些问题
# 版本 1.5.15 --- 2021/06/02
修复:
- 修复读取空行的报错问题
新增:
- Kafka增加支持华为云、阿里云的sasl鉴权验证,修改腾讯云CKafka之前的鉴权方案
# 版本 1.5.14.3 --- 2021/04/29
修复:
- 修复install_logbus_jdk脚本无法下载jre的问题
优化:
- 异常状态时尝试自我修复
# 版本 1.5.14.2 --- 2021/03/16
修复:
- 修复部分旧版本升级失败的问题
# 版本 1.5.14.1 --- 2021/03/03
修复:
- 修复部分旧版本升级时修改NUMTHREAD导致不能正常传输的问题
- 修复数据文件被删除后重新生成时,因原句柄未释放导致的文件重复上传的问题
# 版本 1.5.14 --- 2021/02/02
优化:
- 优化 memory 方案,在网络较优的情况下可大幅提高传输速度
新增:
- 增加配置APPID_IN_DATA,用于根据数据中的#app_id字段匹配项目
# 版本 1.5.13.1 --- 2020/12/23
修复:
- 因旧版本 jackson 出现漏洞,更新至 2.11.2 版本
# 版本 1.5.13 --- 2020/11/27
优化:
- 优化 progress 命令,可指定文件查询并优化显示文案
- 优化 docker 容器
- 优化修改并发方式,方便修改并发数
新增:
- 增加 status 命令,查看当前上传速度和状态
- 增加 repair_channel 命令,优化修复 channel 方式
# 版本 1.5.12 --- 2020/08/28
优化:
- 保障数据来源为 Kafka 时使用 MemoryChannel 的数据可靠性
- 解决无法移除 appid 的问题
- 优化 env 命令,全面检查配置属性并优化显示文案
新增:
- 增加按照指定属性顺序发送
- 增加检查 logbus 部分常见问题的命令 doctor
- 增加#event_id 和#first_check_id
# 版本 1.5.11 --- 2020/06/01
优化:
- 保障数据来源为本地文件时使用 MemoryChannel 的数据可靠性
新增:
- 新增可根据数据中的指定属性映射 APP_ID。
- 增加 LogBus 守护进程健康检查。
- 增加 flume 进程状态监控。
- 数据中可添加 uuid 属性。
- LogBus 增加删除 30 天之外的日志。
- 增加检查 APP_ID。
废弃:
- 废弃旧版本的 ftp 传输方式。
# 版本 1.5.10 --- 2020/03/31
修复:
- 修复准确路径匹配失败的 Bug。
优化:
- 升级 fastjson 版本至 1.2.67,修复反序列化和 SSRF 漏洞。
# 版本 1.5.9 --- 2020/03/25
新增:
- 增加自定义解析器。
- 增加查看当前传输进度命令 progress。
优化:
- taildir 模式下支持匹配任意一层模糊路径。
- 优化对 mac 系统的支持。
# 版本 1.5.8 --- 2020/02/20
新增:
- 针对因网络震荡引起的丢包问题,新增重试策略。
# 版本 1.5.7 --- 2020/02/13
优化:
- 优化 USER 数据通道的分发策略。
# 版本 1.5.6 --- 2020/01/03
优化:
- 优化 pid 文件,状态锁文件存放位置。
- 优化并发数在多项目配置时,也允许调大。
- 优化 JVM 参数。
- 优化读取本地文件时,跳过隐藏文件。
新增:
- 支持独立 JDK 方式。
- 守护进程添加磁盘使用量扫描功能,磁盘不足主动停止 LogBus。
- 新增 data_debug 功能,校验配置目录下文件的内容的详细错误。
- 新增 kafka 数据源的 offset 位置记录。
废弃:
- 废弃旧版本 format_check 功能。
# 版本 1.5.5 --- 2019/09/23
优化:
- 优化 JDK 检查脚本,支持 JDK 10 以上版本校验。
- 优化内部启动顺序。
- 优化 flume 运行环境,避免环境冲突。
- 添加下载进度条显示功能。
- 优化服务端 ip 白名单提示。
# 版本 1.5.4 --- 2019/06/25
优化:
- 优化配置文件参数校验逻辑和操作说明文案。
- 读取文件数超过限制最大数时,新增自动停止 LogBus 的逻辑。
# 版本 1.5.3.1 --- 2019/05/22
修复:
- 修复网络异常情况下数据传输策略问题,由 LogBus 中断传输改为一直重试。
# 版本 1.5.3 --- 2019/04/25
优化:
- 优化大量文件同时传输时的数据传输逻辑
- 优化 LogBus 数据传输日志,分为 info 和 error 两个日志,方便监控 LogBus 运行状态
- 升级基础组件 flume 到最新版本 1.9.0
改动:
- 新增 kafka 对接端 offset 配置:设置 Kafka 的
kafka.consumer.auto.offset.reset参数,可取值为earliest与latest,默认设置为earliest
# 版本 1.5.2.2 --- 2019/04/10
修复:
- 修复部分系统兼容性问题
- 修复打开文件最大数问题
- 修复了在某些极端情况下,position 文件异常问题
# 版本 1.5.2.1 --- 2019/03/29
修复:
- 修复了在某些极端情况下,LogBus 运行异常的问题
# 版本 1.5.2 --- 2019/03/14
新特性:
- Kafka topic 支持多 APP_ID:使用多 APP_ID 可对多个 Kafka topic 进行监控(详情见Kafka 相关参数的配置)
# 版本 1.5.1 --- 2019/03/02
新特性:
- 支持 https 协议:传输地址 PUSH_URL 参数支持 https 协议
- 支持分目录监控:对(多)目录下多个分目录中的文件进行监控(详情见TAIL_FILE 参数的配置),支持通过日期模板以及正则表达式的方式进行配置
# 版本 1.5.0 --- 2018/12/26
新特性:
- 支持多 APP_ID:支持在同一 LogBus 中向多个项目(多 APP_ID)传输数据,使用多 APP_ID 的同时可对多个日志文件目录进行监控
- 支持在线更新命令:新增
update命令,执行该命令可升级 LogBus 至最新版本
优化:
- 加入执行
reset命令时的提示
# 版本 1.4.3 --- 2018/11/19
新特性:
- 多文件目录监控:支持对多个日志文件目录进行监控(详情见
TAIL_FILE参数的配置),同时参数FILE_DIR和FILE_PATTERN已弃用,从老版本升级必须对TAIL_FILE进行配置
改动:
- flume 监控改为自定义的 CustomMonitor,因此不需配置 FM_PORT 参数(此参数已弃用)
优化:
- 修复了检测 java 版本 10 以上报错的问题
# 版本 1.4.2 --- 2018/09/03
新特性:
- 新增数据传输方式:新增 ftp 传输方式
# 版本 1.4.0 --- 2018/07/30
新特性:
- 多实例:同一台服务器可以部署多个 LogBus。
只需安装多个 LogBus 工具,放置在不同的目录,并对每个 LogBus 配置各自的配置文件即可使用。
- 多线程传输:实现多线程安全。
通过修改配置文件中的参数NUMTHREAD设置线程个数
- sink 端支持多种压缩格式:gzip、lz4、lzo、snappy、不压缩(none)
压缩方式从左往右,压缩比依次降低,请根据网络环境及服务器性能进行选择。
改动:
- 在首次启动或修改配置文件后,需要调用
env命令使配置文件生效,才能使 LogBus 正常工作。
优化:
- 优化启动前的检查提示文案。
# 版本 1.3.5 --- 2018/07/18
优化:
- 优化文件格式检查命令输出提示。
- 优化文件传输提示输出。
- checkpoint 加入一个备份内容,防止 checkpoint 频繁读写错误。
- 增加 channel 水位控制,使其不会出现 channel full 的警告。
- 增加 sink 端网络 socktimeout,设定为 60s。
- 增加 LogBus 监控,发生 sink 卡死的时候,自动重启。
# 版本 1.3.4 --- 2018/06/08
改动:
- 数据过滤方面:只过滤空行和非 json 数据。
- 文件删除功能由原来的每天定点删除,变为每隔一段时间删除。
配置文件:
- 配置文件格式优化,主要将配置文件归为 source、channel、sink 和 others 四个部分。
- 新增 FREQUENCY_REMOVE 参数,用于每隔一段时间删除已上传的目录文件,单位:分。
- 去除 TIME_REMOVE 参数。
新功能:
- 增加自动化工具(主要是针对 ansible)启动的优化脚本,放在 bin/automation 目录下,主要有启动
start,停止stop,立刻停止stop_atOnce三个命令。
性能优化:
- 优化启动所需的内存,减低内存需求。
# 版本 1.3 --- 2018/04/21
- 增加 Kafka 数据源的支持
- 修复了已知的 Bug
# 版本 1.0 --- 2018/03/29
- LogBus 发布