# DataX Engine
# I. Introduction to DataX
DataX is an open source project released by Alibaba (for details, please visit DataX's Github homepage (opens new window)). It is an efficient offline data synchronization tool, which is often used for data synchronization between heterogeneous data sources.
DataX uses the Framework + plugin architecture. Data source reading and writing correspond to Reader and Writer plug-ins respectively. Each data source will have a corresponding Reader or Writer. DataX provides rich Reader and Writer support by default. It can adapt to a variety of mainstream data sources. Framework is used to connect Reader and Writer, and is responsible for data processing, torsion and other core processes in the synchronization task.
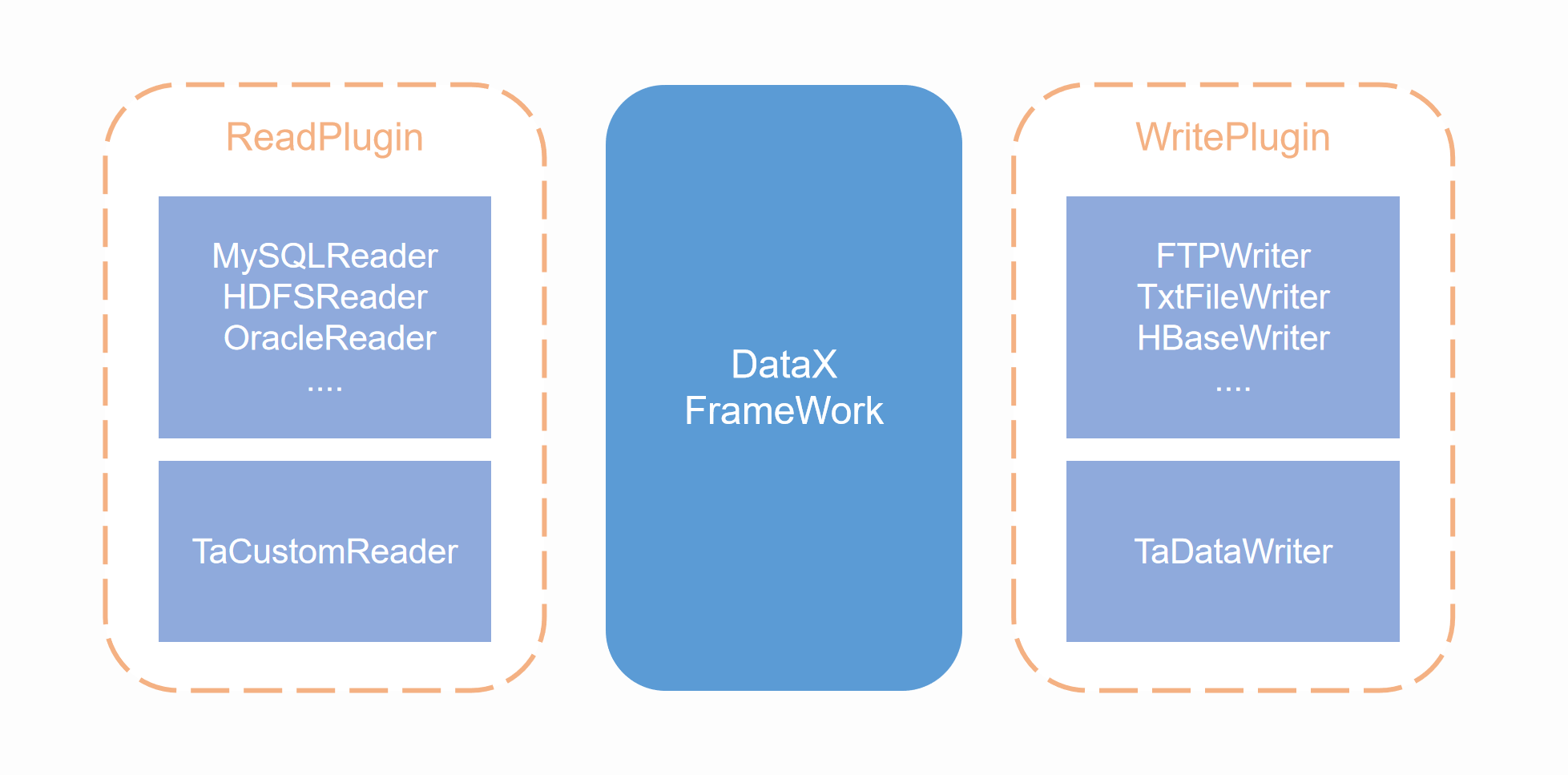
DataX's data synchronization task is mainly controlled through a configuration file. The most important configuration is the configuration of Reader and Writer, which respectively represent how to extract data from the data source and how to write the extracted data to the data source. Synchronization of heterogeneous data sources can be completed by using the Reader and Writer of the corresponding data source in the configuration file.
In ta-tool, we have integrated the DataX engine and written plug-ins for the TA cluster (that is, Reader and Writer for the TA cluster). With the TA cluster plug-in, the TA cluster can be used as the data source for DataX.
Through the DataX engine in ta-tool, you can complete the following data synchronization:
- To import data from other databases into the TA cluster, you need to use DataX's existing Reader plug-in and TA Writer
- To export the data of TA cluster to other databases, you need to use the existing Writer plug-in of DataX and TA Reader
# II. Instructions for DataX Engine Use
If you need to use the DataX engine in ta-tool for multi-data source synchronization job, you first need to write the Config file of the DataX job in the TA cluster, and then execute the DataX command in the developer component, read the Config file to perform the data synchronization job.
# 2.1 Sample configuration file
DataX task Config file needs to be a json file, json configuration template is as follows:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello, world-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
The entire configuration file is a JSON, the outermost 'job' element, which contains two elements, namely 'content' and 'setting'. The elements within 'content' contain reader and writer information. Reader and Writer for TA clusters can be viewed later in this article. "Channel" in "speed" in "set" is the number of tasks performed simultaneously.
The main part of the configuration file that needs to be configured is the "reader" and "writer" elements in the "content". The Reader plug-in for reading data and the Writer plug-in for writing data are configured respectively. For configuration of the DataX preset Reader and Writer plug-ins, visit DataX's Support Data Channels (opens new window).
# 2.2 Execute DataX command
After you have written the configuration file, you can execute the following command to read the configuration file and start the data synchronization task.
ta-tool datax_engine -conf <configPath> [--date <date>]
The parameter passed in is the path where the configuration file is located.
# III. Description of DataX Plug-in for TA Cluster
# 3.1 Plug-ins used within the cluster
| Type | Data source | Reader (read) | Writer (write) | Doc |
|---|---|---|---|---|
| TA system | TA | √ | √ | read , write |
| Custom table | TA | √ | write | |
| json text | TA | √ | write |
# 3.2 Plug-ins used outside the cluster
| Type | Data source | Reader (read) | Writer (write) | Doc | ||||
|---|---|---|---|---|---|---|---|---|
| TA system | TA | √ | write | Data source | Reader (read) | Writer (write) | Doc |
# 3.3 DataX native plug-ins
| Type | Data source | Reader (read) | Writer (write) | Doc |
|---|---|---|---|---|
| RDBMS relational database | MySQL | √ | √ | read , write |
| Oracle | √ | √ | read , write | |
| SQLServer | √ | √ | read , write | |
| PostgreSQL | √ | √ | read , write | |
| DRDS | √ | √ | read , write | |
| General-purpose RDBMS (supports all relational databases) | √ | √ | read , write | |
| Alibaba Cloud Data Storage | ODPS | √ | √ | read , write |
| ADS | √ | write | ||
| OSS | √ | √ | read , write | |
| OCS | √ | √ | read , write | |
| NoSQL data storage | OTS | √ | √ | read , write |
| Hbase0.94 | √ | √ | read , write | |
| Hbase1.1 | √ | √ | read , write | |
| Phoenix4.x | √ | √ | read , write | |
| Phoenix5.x | √ | √ | read , write | |
| MongoDB | √ | √ | read , write | |
| Hive | √ | √ | read , write | |
| Cassandra | √ | √ | read , write | |
| Unstructured data storage | TxtFile | √ | √ | read , write |
| FTP | √ | √ | read , write | |
| HDFS | √ | √ | read , write | |
| Elasticsearch | √ | √ | read , write | |
| Time series database | OpenTSDB | √ | rea d | |
| TSDB | √ | √ | read , write |