# LogBus 利用ガイド
このドキュメントではデータインポートツールLogBusの使用方法を説明します。
LogBus** Windows版は**LogBus Windows版利用ガイドをご参照ください。
データアクセスを開始する前にデータルールをご参照ください。ThinkingEngine(以下TE)のデータフォーマットとデータルールを理解したうえ、このガイドに従ってデータアクセスを実行していください。
LogBusでアップロードするデータはTE****のデータルールに準拠する必要があります。
# LogBus ダウンロード
**最新バージョン:**1.5.15.7
**更新時間:**2021-12-10
Linux armバージョン ダウンロード (opens new window)
バージョンアップの方法
- Ver 1.5.0以上
./logbus stopを実行してLogBusを停止し、./logbus updateを実行し、最新バージョンにバージョンアップしてください
- Ver 1.5.0より前
- 当社にお問合せください
# 概要
LogBusは、主にバックエンドのログデータをTEささにリアルタイムでインポートするために使用されます。これはFlumeと類似します。また、サーバーログのディレクトリのファイルフローを監視します。ディレクトリ内の任意のログファイルに新しいデータが生成されると、そのデータを検証し、リアルタイムでTEに転送します。
次のようなユーザーは、LogBusを使用してデータをインポートすることをお勧めします。
- サーバーSDKを使用する場合
- データの正確性とディメンションに厳しく、クライアントSDKだけではデータの要件が満たせない、あるいはクライアントSDKにインポートできない場合
- バックエンドのデータのプッシュプロセスを開発しない場合
- 大量の履歴データを送信する必要がある場合
# 2、使用前のデータ準備
- まずインポートするデータをETLからTEのデータ形式に変換し、ローカルに書き込むかKafkaクラスターに送信します。サーバー側SDKのローカルテキストやKafkaのconsumerを使用する場合、データは既に正しい形式のため、変換する必要はありません。
2.アップロードされたデータのファイルの格納ディレクトリ、またはKafkaのアドレスとtopicを特定し、LogBusを設定します。LogBusはファイルのディレクトリのファイルの変更を監視します。(新しいファイルまたはtailファイルを監視)またはKafkaのデータを購読します。
3.監視ディレクトリに格納されたアップロード済のデータログの名前を変更しないでください。名前変更は新規ファイル作成に相当し、LogBusはこれらのファイルを再アップロードしてしまう可能性があるため、データの重複が発生します。
4.LogBusデータインポートコンポーネントにデータバッファが含まれているため、LogBusディレクトリがディスクに占める容量が大きくなる可能性があるため、LogBusインストールのディスク容量が十分であることを確認してください。一つのプロジェクトにデータをインポート(APP_IDを追加)する場合、少なくとも10Gのストレージを確保する必要があります。
# 3、LogBusのインストールとアップグレード
# 3.1 LogBusのインストール
LogBusツール (opens new window)をダウンロードし解凍します。
解凍後のディレクトリ構造:
bin:起動プログラムのフォルダ
conf:設定ファイルのフォルダ
lib:機能フォルダ
# 3.2 LogBusのアップグレード
v1.5.0以降を使用している場合は、./logbus stopでLogBusを実行し、./logbus updateでLogBusを最新バージョンにアップグレードします。その後、LogBusを再起動します。
# 3.3 dockerバージョン
dockerコンテナでlogbusを使用する場合、LogBus docker利用ガイド (opens new window)をご参照ください。
# 4、LogBusのパラメーター設定
1.解凍後のconfディレクトリには、設定ファイルlogBus.conf.Templateがあります。このファイルにはLogBusのすべての構成パラメーターを含み、初めて使用するときに名前をlogBus.confに変更します。
2.ファイルlogBus.confを開き、パラメーターを設定します。
# 4.1 プロジェクトとデータソースの設定(設定必須)
- プロジェクトAPP_ID
##APPIDは公式サイトtgaのtokenから取得し,TEプラットフォームのプロジェクト設定画面でプロジェクトのAPPIDを取得して入力する.複数のAPPIDは","で分割する.
APPID=APPID_1,APPID_2
- 監視ファイルの設定(いずれかを選択してください。設定必須)
# 4.1.1.データソースがローカルファイルの場合
##LogBusがデータファイルのパスおよびファイル名(ファイル名はあいまいマッチングをサポート)を読み込む. 読み取り権限が必須.
##異なるAPPIDはカンマで分割し,同じAPPIDの異なるディレクトリはスペースで分割する.
##TAIL_FILEのファイル名はjavaの標準的な正規表現とワイルドカード両方をサポート.
TAIL_FILE=/path1/dir*/log.* /path2/DATE{YYYYMMDD}/txt.*,/path3/txt.*
##TAIL_MATCHERはTAIL_FILEのパスのあいまいマッチングモードを指定する.regexは正規表現 globはワイルドカード.
##regexは正規モードで,javaの標準的な正規表現をサポートする.しかし,一階層のディレクトリとファイル名のあいまいマッチングのみサポート.
##globはワイルドカードモードで,多階層のディレクトリのあいまいマッチングをサポートし,DATE{}形式のマッチングをサポートしない.
##デフォルトでregex正規表現式でマッチング
#TAIL_MATCHER=regex
TAIL_FILEは複数パスの複数ディレクトリ内の複数ファイルへの監視をサポートします。
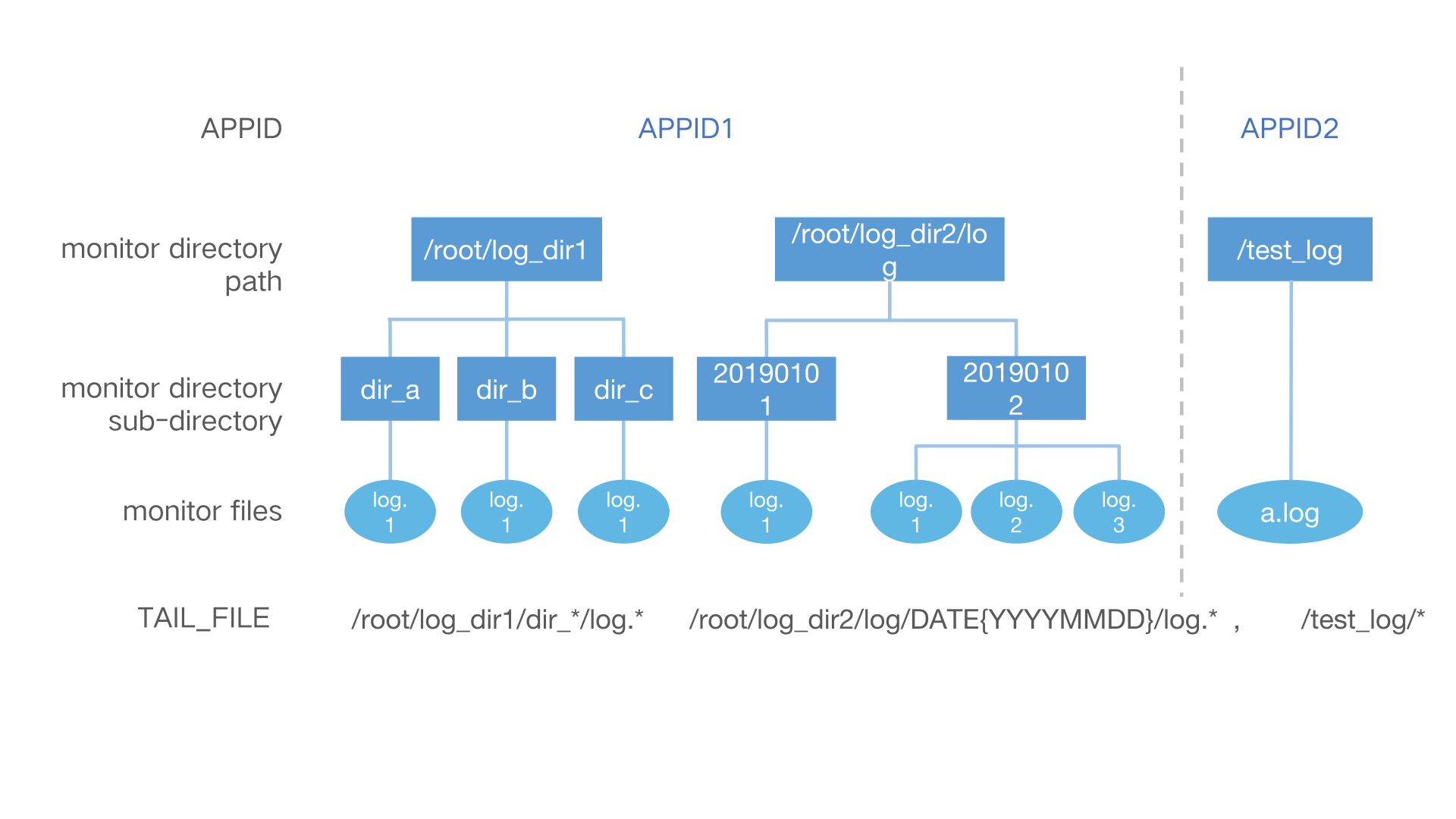
対応するパラメーターの設定:
APPID=APPID1,APPID2
TAIL_FILE=/root/log_dir1/dir_*/log.* /root/log_dir2/log/DATE{YYYYMMDD}/log.*,/test_log/*
具体的なルールは次のとおりです。
- 同じAPP_IDの複数の監視パスをスペースで分割する。
- 異なるAPP_IDの監視パスは半角カンマで分割し、カンマで分割された監視パスはAPP_IDに対応する。
- 監視パスのサブディレクトリ(ファイルがあるディレクトリ)は、日付形式、正規表現監視、ワイルドカードをマッチングする。
- ファイル名は正規表現での監視やワイルドカードをサポートします。
監視が必要なログファイルをサーバーのルートディレクトリに保存しないでください。
日付形式のサブディレクトリのルール(regexモードのみサポート):
日付形式のディレクトリはDATE{}で日付テンプレートを囲む必要があり、**DATEは大文字でなければなりません。**以下に、いくつかの識別可能な日付テンプレートおよび監視に対応するファイルサンプルの例を示します。これに限らず、日付テンプレートは標準の日付形式であればよいです。
/root/logbus_data/DATE{YYYY-MM-DD}/log.*---> /root/logbus_data/2019-01-01/log.1/root/logbus_data/DATE{YYMMDD}/log.*--->/ルート/logbus_data/190101/log.1/root/logbus_data/DATE{MM_DD_YYYY}/log.*--->/ルート/logbus_data/01_01_2019/log.1/root/logbus_data/DATE{MM*DD}/log.*--->/root/logbus_data/01*01/log.1
# 4.1.2. データソースがkafkaの場合
バージョン1.5.2以降、パラメーターKAFKA_TOPICSは正規表現をサポートしなくなります。複数のトピックを監視する時に、スペースでトピックを区切ることができます。複数のAPP_IDがある場合は、半角コンマで各APP_IDの監視topicを分割します。パラメーターKAFKA_GROUPIDは一意でなければなりません。バージョン1.5.3からパラメーターKAFKA_OFFSET_RESETが追加され、Kafkaのパラメーターkafka.consumer.auto.offset.resetを設定することができ、値はearliestとlatestを取ることが可能で、デフォルトでearliestに設定します。
注意:データソースのKafkaバージョンは0.10.1.0以上でなければなりません。
単一APP_IDサンプル:
APPID=appid1
######kafka 設定
#KAFKA_GROUPID=tga.group
#KAFKA_SERVERS=localhost:9092
#KAFKA_TOPICS=topic1 topic2
#KAFKA_OFFSET_RESET=earliest
#クラウドサービスを選択:tencent/ali/huawei
#KAFKA_CLOUD_PROVIDER=
#KAFKA_INSTANCE=
#KAFKA_USERNAME=
#KAFKA_PASSWORD=
#SASL承認
#KAFKA_JAAS_PATH=
#KAFKA_SECURITY_PROTOCOL=
#KAFKA_SASL_MECHANISM=
マルチAPP_IDサンプル:
APPID=appid1,appid2
######kafka 設定
#KAFKA_GROUPID=tga.group
#KAFKA_SERVERS=localhost:9092
#KAFKA_TOPICS=topic1 topic2,topic3 topic4
#KAFKA_OFFSET_RESET=earliest
#クラウドサービスを選択:tencent/ali/huawei
#KAFKA_CLOUD_PROVIDER=
#KAFKA_INSTANCE=
#KAFKA_USERNAME=
#KAFKA_PASSWORD=
#SASL承認
#KAFKA_JAAS_PATH=
#KAFKA_SECURITY_PROTOCOL=
#KAFKA_SASL_MECHANISM=
# 4.2 転送パラメーターの設定(設定必須)
##転送設定
##転送url
##http転送は
PUSH_URL=http://ta-receiver.thinkingdata.io/logbus
##オンプレミスサービスを使用する場合,転送URLを:http://数据采集地址/logbusに変更
##appidチェックをオンにするか,デフォルトはオフ
#IS_CHECK_APPID=false
##1回あたりの最大転送量
#BATCH=10000
##最低転送頻度(单位:秒)
#INTERVAL_SECONDS=600
##転送スレッド数,实际スレッド数は設定のスレッド数+1,デフォルトは2つのスレッド
#NUMTHREAD=1
##各データにプロパティuuidを追加(オンにすると転送効率を低下)
#IS_ADD_UUID=true
##ファイル転送の圧縮形式:gzip,lzo,lz4,snappy,none
#COMPRESS_FORMAT=none
# 4.3 Flumeのメモリパラメーターの設定(設定任意)
# flumeパイプライン容量设置
# パイプライン容量,ここはPCの設定によって決める。
CAPACITY=1000000
# パイプラインからsinkの転送量,BATCHパラメーターより大きい。
TRANSACTION_CAPACITY=10000
##flume起動の最大メモリを指定し,单位はM。
#MAX_MEMORY=2048
# flumeのchannel設定,fileとmemoryがある(選択可,デフォルトはfile)
# CHANNEL_TYPE=file
# 4.4 監視文書の削除設定(設定任意)
# 监控ディレクトリのファイルを削除.注釈の消去はファイル削除機能をオンにすることに相当
# 日単位(day)か時間単位(hour)で删除
# UNIT_REMOVE=hour
# どれくらい前のファイルを削除
# OFFSET_REMOVE=20
# アップロード済の監視ファイルを削除.何分ごとに削除.
# FREQUENCY_REMOVE=60
# 4.5 カスタム解析器(設定任意)
バージョン1.5.9から、カスタムデータ解析をサポートします。元のデータ形式とTEデータ形式が一致しない場合に変換形式をカスタマイズすることができます。
詳細は次のとおりです:
- 次のコードを追加します:
Maven:
<dependency>
<groupId>cn.thinkingdata.ta</groupId>
<artifactId>logbus-custom-interceptor</artifactId>
<version>1.0.3</version>
</dependency>
Gradle:
// https://mvnrepository.com/artifact/cn.thinkingdata.ta/logbus-custom-interceptor
compile group: 'cn.thinkingdata.ta', name: 'logbus-custom-interceptor', version: '1.0.3'
- CustomInterceptorインターフェイスのtransFromメソッドを実装します。メソッドの最初のパラメーターは元のデータ内容で、2番目のパラメーターはsourceNameです。(APP_IDを区別したい場合に使用。APP_IDで区別する。例えば、1つのAPP_IDのみを設定すると、sourceNameはr1であり、複数のAPP_IDを設定すると、sourceNameはr1、r2の順になる。)
public interface CustomInterceptor {
TaDataDo transFrom(String var1, String var2);
}
実装されたインターフェイスメソッドは次のとおりです:
public TaDataDo transFrom(String s, String s1) {
return JSONObject.parseObject(s, TaDataDo.class);
}
- 次の2つのフィールドを設定します:
##次の2つのフィールドはカスタム解析器を使用(2つのフィールドとも設定する必要がある)
##解析器の完全限定名をカスタマイズし(パッケージ名+クラス名),設定しない場合はデフォルトの解析器を使用
#CUSTOM_INTERCEPTOR=cn.thinkingdata.demo.DemoCustomInterceptor
##カスタム解析器jarの絶対パス(jarのファイル名を含む)
#INTERCEPTOR_PATH=/var/interceptor/custom-interceptor-1.0-SNAPSHOT.jar
# 4.6 データ内の#app_idによるプロジェクト分割(設定任意)
注意:この機能にはTEバージョン3.1以上が必要
##1.5.14からAPPID_IN_DATA設定を追加.使用中データの#app_idでプロジェクトを配分する際,APPID_IN_DATA=trueは設定可能。
##APPID設定は不要で,TAIL_FILEも一層のみ設定可能
##注意:TEの最低バージョンは3.1
#APPID_IN_DATA=false
# 4.7 設定に応じて対応するプロジェクトに自動配布(設定任意)
##1.5.14は以前の機能を変更し,TE3.1以上のバージョンと併用する必要がある。
##指定需要映射的プロパティ名を指定し,例如name,需结合APPID_MAP字段使用
##APPID_MAP_ATTRIBUTE_NAME=name
##APPIDと属性值の対応関係を提供し,例えば以下の設定はデータのpropertiesフィールドのnameのフィールド值がaかbの時にデータはappid_1に配布し,cとdの時,appid_2に配布
##APPID_MAP={"appid_1":["a","b"],"appid_2":["c","d"]}
##DEFAULT_APPIDはデータにnameフィールドまたはnameフィールドの值は上記の設定にない場合に配布するプロジェクトを表す
##DEFAULT_APPID=appid_3
# 4.8 設定ファイルの例
##################################################################################
## thinkingdataデータ分析プラットフォームのデータインポートツールlogBusの設定ファイル
##注釈なしは必須パラメーターで注釈ありは任意パラメーターはご自身の状況に応じて適切な設定を行う
##環境条件:java8+,詳細はtga公式サイトをご参照ください
##http://doc.thinkinggame.cn/tgamanual/installation/logbus_installation.html
##################################################################################
##APPIDはtga公式サイトのtokenにある
##異なるAPPIDはカンマで区切る
APPID=from_tga1,from_tga2
#-----------------------------------source----------------------------------------
######file-source
##LogBusはデータファイル所在のパスとファイル名を取得(ファイル名はあいまいマッチングをサポート). 読み取り権限が必要.
##異なるAPPIDはカンマで分割し,同じAPPIDの異なるディレクトリはスペースで分割する
##TAIL_FILEのファイル名はjavaの標準的な正規表現とワイルドカード両方をサポート
#TAIL_FILE=/path1/log.* /path2/txt.*,/path3/log.* /path4/log.* /path5/txt.*
##TAIL_MATCHERはTAIL_FILEのパスのあいまいマッチングモードを指定する.regexは正規表現 globはワイルドカード.
##regexは正規モードで,javaの標準的な正規表現をサポートする.しかし,一階層のディレクトリとファイル名のあいまいマッチングのみサポート.
##globはワイルドカードモードで,多階層のディレクトリのあいまいマッチングをサポートし,DATE{}形式のマッチングをサポートしない.
##デフォルトでregex正規表現式でマッチング
#TAIL_MATCHER=regex
######kafka-source
##kafka,topics正規表現を使用
#KAFKA_GROUPID=tga.flume
#KAFKA_SERVERS=ip:port
#KAFKA_TOPICS=topicName
#KAFKA_OFFSET_RESET=earliest/latest
#------------------------------------sink-----------------------------------------
##転送設定
##転送url
##PUSH_URL=http://${数据采集地址}/logbus
##1回あたりの最大転送量(指定された数量に達するとデータ転送指示を出す)
#BATCH=1000
##最低転送頻度(单位:秒)(時間が過ぎたが,batch数を満たしていない.現在のデータ数を送信)
#INTERVAL_SECONDS=60
##### http転送
##ファイル転送の压缩形式:gzip,lzo,lz4,snappy,none
#COMPRESS_FORMAT=none
#------------------------------------other-----------------------------------------
##监控ディレクトリのファイルを削除.注釈を(必ず以下の2つのフィールドともオンにする)オンにする.ファイル削除機能をオンにすることに相当.1時間あきにファイル削除アプリを起動
##unitによってoffet以前のファイルを削除
##どれくらい以前のファイルを削除
#OFFSET_REMOVE=
##日単位(day)または時間単位(hour)で删除
#UNIT_REMOVE=
#------------------------------------interceptor-----------------------------------
##次の2つのフィールドはカスタム解析器を使用(2つのフィールドとも設定する必要がある)
##解析器の完全限定名をカスタマイズし(パッケージ名+クラス名),設定しない場合はデフォルトの解析器を使用
#CUSTOM_INTERCEPTOR=
##カスタム解析器のjarの位置
#INTERCEPTOR_PATH=
# 5、 LogBusの起動
はじめて起動する前に、次のチェックを行ってください。
1.Javaのバージョンを確認
binディレクトリには、check_javaとlogbusとの2つのスクリプトがあります。
check_javaはjavaバージョンが要求を満たしているかどうかを検出し、スクリプトを実行します。javaバージョンが満たされていない場合はJava version is less than 1.8かCan't find java, please install jre first.などのヒントが表示されます。
JDKバージョンを更新するか、もしくは次の節を参照してLogBus単独でJDKをインストールします。
2.LogBusの独立JDKのインストール
LogBusはノードを配置する場合、環境上の理由でJDKバージョンはLogBusの要件を満せず、LogBusのJDKバージョンに置き換えることはできません。この場合は本機能を使用することができます。
binディレクトリにinstall_logbus_jdk.shがあります。
このスクリプトを実行すると、LogBus作業ディレクトリにJavaディレクトリが追加されます。LogBusはデフォルトでこのディレクトリのJDK環境を使用します。
3.logBus.confの設定を完了し、パラメーター環境を実行してコマンドをチェックします。
logBus.confの設定は、LogBus設定をご参照ください。
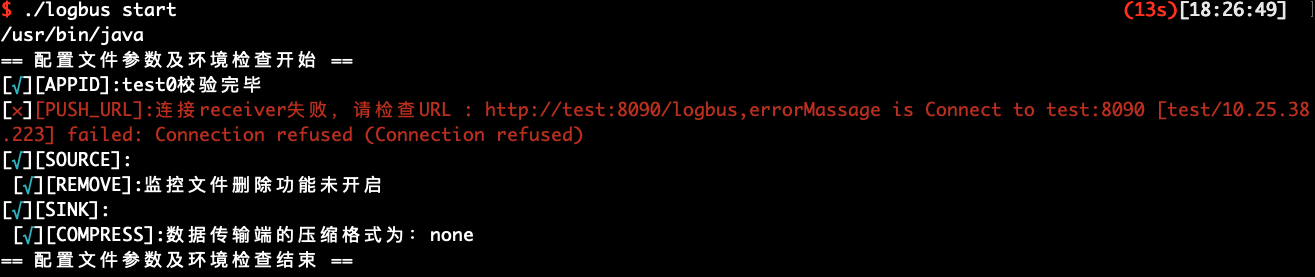
設定が完了したらenvコマンドを実行し、設定パラメーターが正しいかどうかをチェックします。
./logbus env
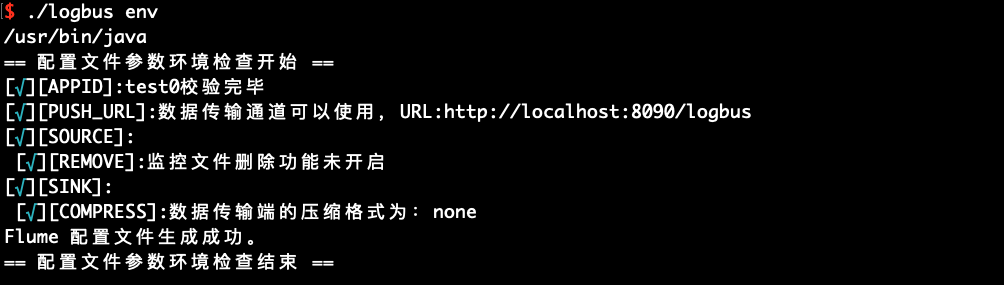
赤色の異常情報を出力すると、設定に問題があることを示し、上図のように設定ファイルに例外がないまで再修正する必要があります。
** LogBus.confの設定を変更した後、LogBusを再起動し、新しい設定を有効にする必要があります。**
4.LogBusを起動
./logbus start
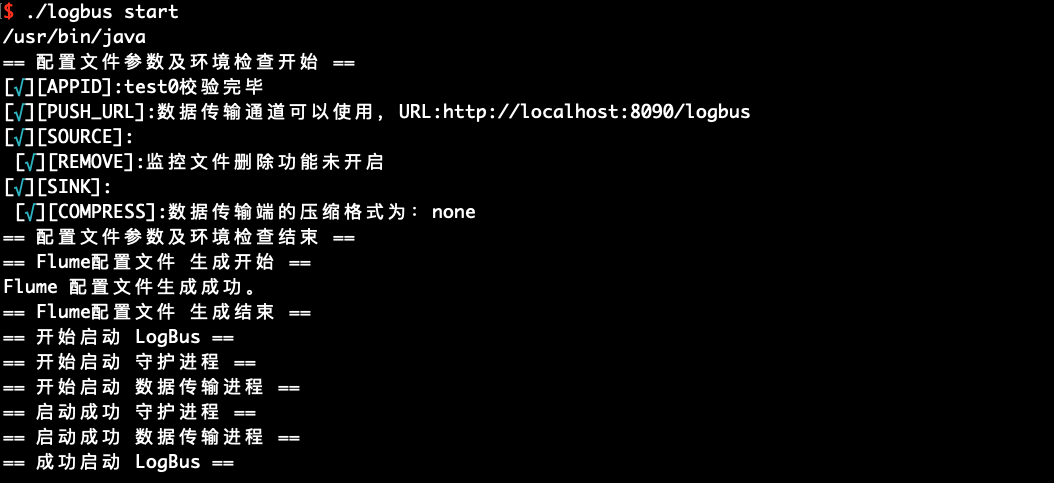
起動に成功すると、上図のようなお知らせが表示され、失敗すると異常情報が表示されます。
# 6、LogBusコマンドの詳細説明
# 6.1 ヘルプ情報
パラメーター、--help、-hがなければ、次のようなヘルプ情報が表示されます。
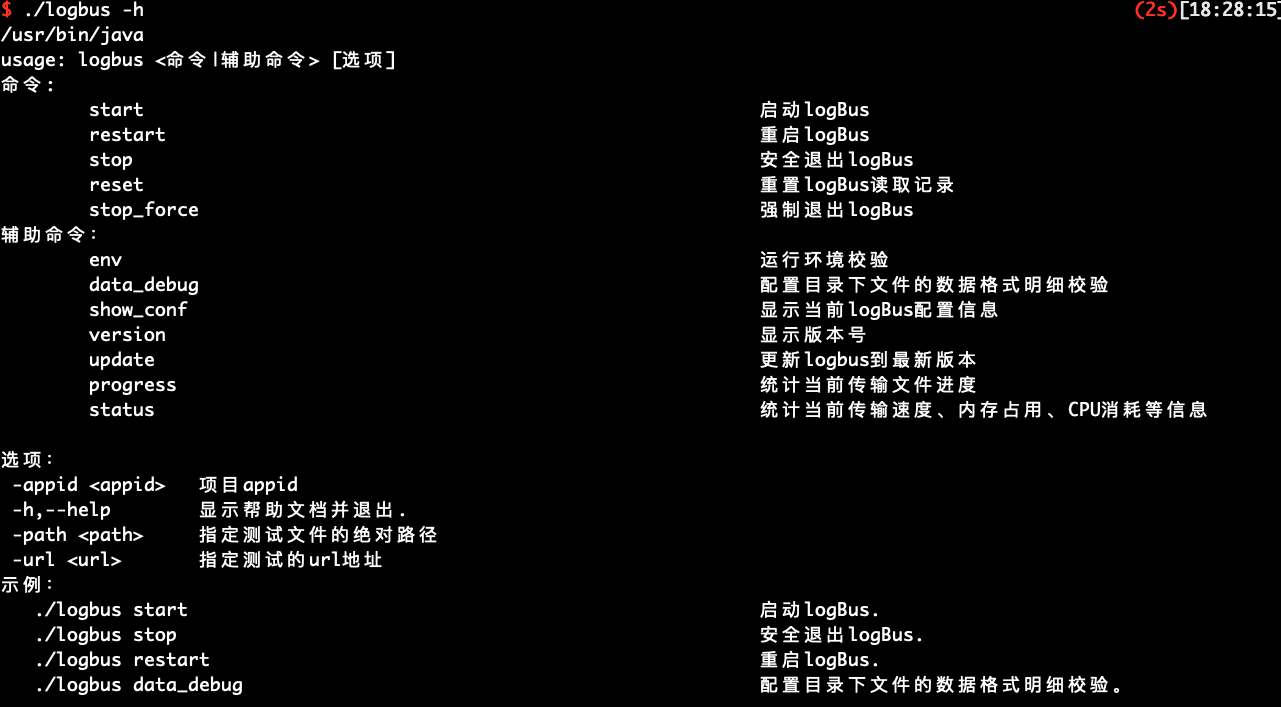
LogBusのコマンドを紹介します:
usage: logbus <コマンド|補助コマンド> [選択肢]
コマンド:
start logBus起動.
restart logBus再起動.
stop logBusエンド.
reset logBusの読取記録をリセット.
stop_force logBus强制退出.
補助コマンド:
env 運用環境検証.
data_debug ディレクトリにあるファイルのデータ形式の詳細検証を設定.
show_conf 現在logBusの設定情報を表示.
version バージョンを表示.
update logbusを最新バージョンに更新.
progress 現在ファイルの転送速度を集計
status 現在の転送速度を集計.メモリ占有率、CPU消耗などの情報
選択肢:
-appid <appid> プロジェクトappid
-h,--help ヘルプファイルを表示し、退出.
-path <path> テストファイルの絶対パスを指定
-url <url> テストアドレスを指定
示例:
./logbus start logBus起動.
./logbus stop logBus安全退出.
./logbus restart logBus再起動.
./logbus data_debug ディレクトリにあるファイルのデータ形式の詳細検証を設定.
# 6.2 ファイルデータ形式のチェックdata_debug
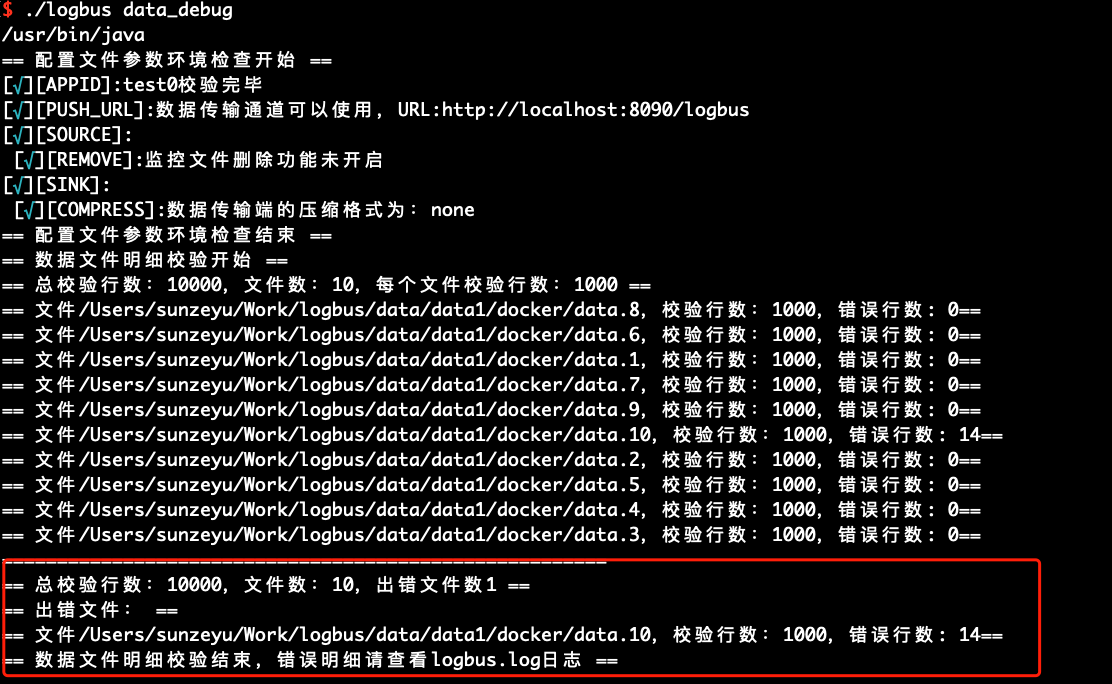
初めてLogBusを使用する場合、データを正式にアップロードする前に、データの形式をチェックすることをお勧めします。データはデータルールに準拠する必要があり、data_debugコマンドでデータ形式のチェックを実行します。
この機能はクラスターのリソースを消耗し、毎回10000本を限定します。ファイルごとにチェック量を均等に分け、ファイルの先頭からチェックを進めます。
./logbus data_debug
データ形式が正しい場合は、次の図のようにデータが正確であることを示します。
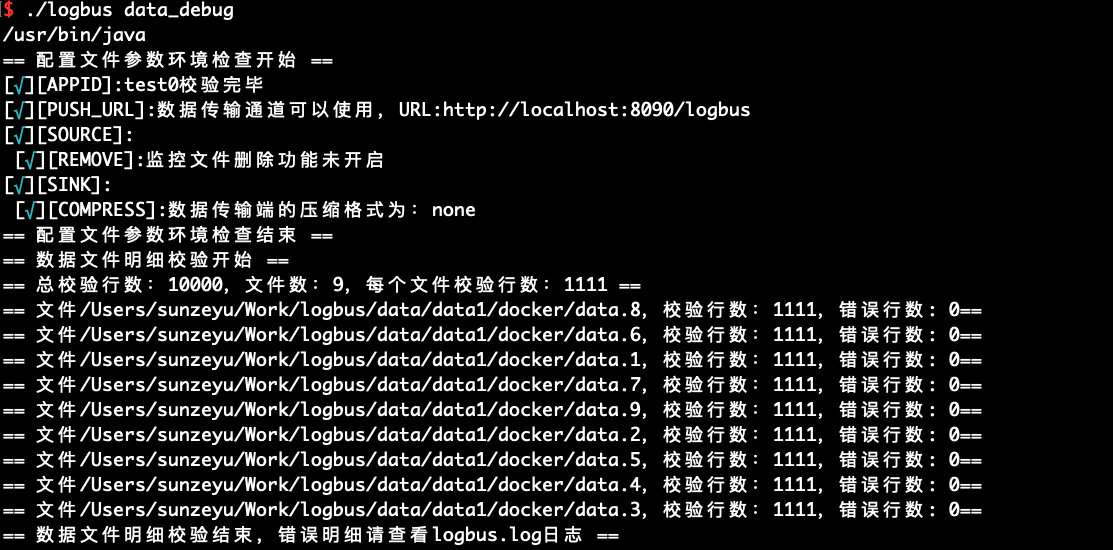
データ形式に問題がある場合、形式エラーを警告し、形式エラーのポイントを簡単に解釈します。
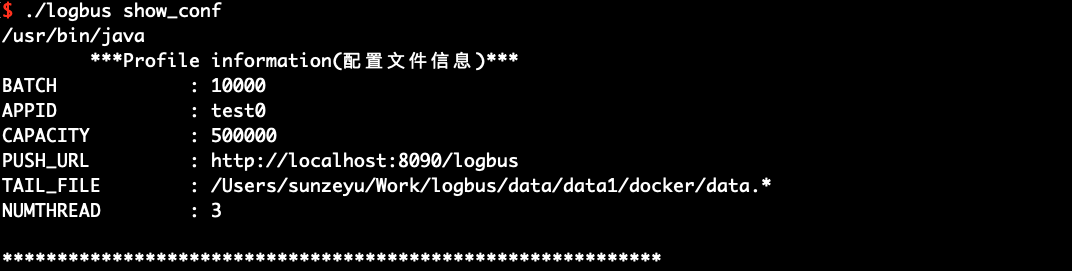
# 6.3 設定情報の展開show_conf
show_confコマンドを使用して、次の図に示すように、LogBusの設定情報を表示します。
./logbus show_conf
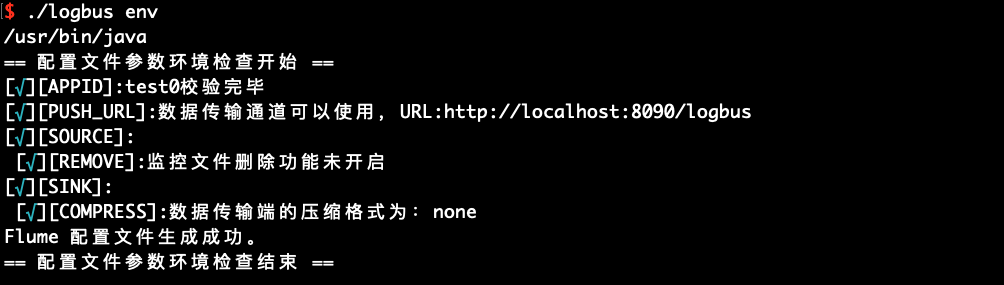
# 6.4 環境チェックの起動env
envを使用して起動環境のチェックを行うことができます。出力された情報の後ろにアスタリスクが付いている場合、設定に問題があることを示し、アスタリスクのヒントがなくなるまで修正する必要があります。
./logbus env
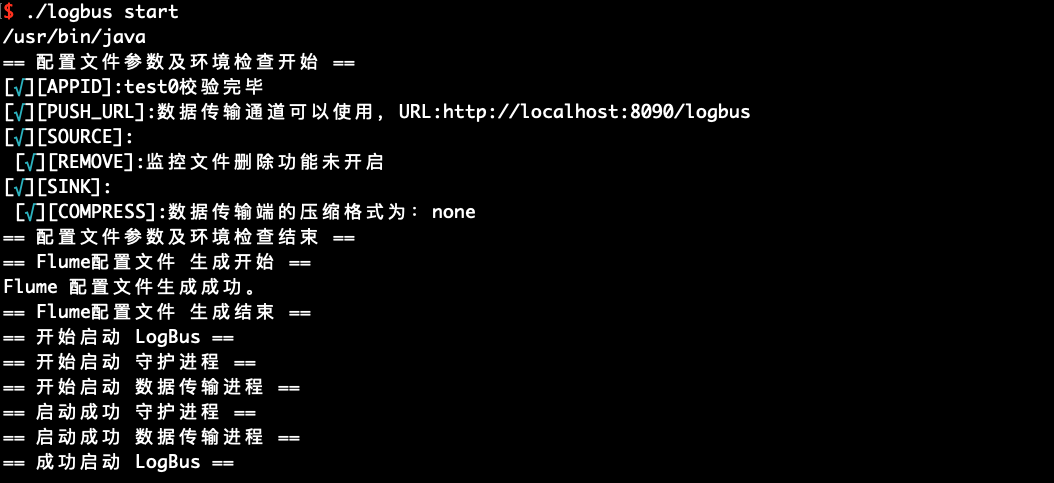
# 6.5 起動start
形式のチェック、データチャネルのチェックおよび環境のチェックが完了すると、LogBusを起動してデータのアップロードを行います。LogBusは自動的にファイルに新しいデータが書き込まれているかどうかを検出し、新しいデータがある場合、データをアップロードします。
./logbus start
# 6.6 停止stop
LogBusを停止したい場合、stopコマンドを使用してください。
./logbus stop

# 6.7 停止stop_force
即時にLogBusを停止したい場合、stop_forceコマンドを使用してください。しかし、このコマンドはデータを失う可能性があります。
./logbus stop_force
# 6.8 再起動restart
restartコマンドを使用してLogBusを再起動することができます。設定パラメーターを修正した後に新しい設定を有効化します。
./logbus restart
# 6.9 リセットreset
resetコマンドを使用してLogBusをリセットすることができるため、慎重に使用してください。このコマンドを実行すると、データの転送記録が削除されるので、LogBusが改めてすべてのデータをアップロードします。不明な条件でこのコマンドを使用すると、データが重複する可能性があります。TAスタッフと連絡を取ってから使用することをお勧めします。
./logbus reset
リセットコマンドを実行した後、startを実行してデータ転送を再開する必要があります。
LogBus 1.5.0バージョン以降、以下の確認情報を追加し、確認後にLogBusのリセットを開始します。

# 6.10 バージョンを表示version
現在使用しているLogBusのバージョン番号を知りたい場合はversionコマンドを使用します。LogBusにこのコマンドがない場合は古いバージョンを使用していることが分かります。
./logbus version
# 6.11 LogBusバージョンの更新update
LogBus1.5.0は、オンラインでバージョンを更新する機能が追加され、このコマンドを実行するとLogBusは最新バージョンに更新されます。
./logbus update
# 6.12 現在のアップロード進捗状況の確認progress
LogBus1.5.9は、現在のアップロードの進捗状況を確認する機能が追加されました。このコマンドを実行すると、現在の転送の進捗状況を確認することができます。-appidを使用してプロジェクトを指定したり、ファイルのフルパス名を直接追加して検索を指定したりすることができます。
./logbus progress /data/logbus-1.log /data/logbus-2.log -appid {APPID}
# 6.13 LogBusのよくある問題の確認doctor
LogBusバージョン1.5.12は、logBusのよくある問題をチェックするコマンドが追加され、このコマンドを実行すると現在のlogBusに問題があるかどうかをチェックします。
./logbus doctor
# 6.14 LogBusの現在のアップロード速度と状態の確認status
LogBus1.5.13は、logBusの現在のアップロード速度と状態を表示するコマンドが追加され、このコマンドを実行すると現在のlogBusのアップロード速度と状態を確認することができます。
./logbus status