# 接入前准备工作
TE (ThinkingEngine) 系统提供了全端数据接入方案。
通常情况下,接入 TE 需要三个步骤:首先根据业务需求的整理,梳理出数据采集方案,数数科技的分析师会协助您完成这一部分工作;然后,由研发人员根据数据采集方案完成数据接入工作;最后是验证数据接入正确性。该接入流程如下图所示:

在数据接入之前,了解 TE 系统的基础知识是非常重要的。本篇文档将会对必要的接入相关知识做一个整体的介绍,同时也会列出当您希望进一步了解相关内容的时候,如何获取帮助。
本文的目标读者是所有与接入相关的同事,包括业务人员、研发人员、测试人员等。
# 一、概述
TE 提供了全端的数据接入方案,主要接入方式包括:
- 客户端 SDK:可以采集到设备信息,以及不与服务器通信的用户行为数据,简单易用
- 服务端 SDK:采集内容更加精准,适合采集核心业务数据
- 数据导入工具:通常用于历史数据导入;服务端 SDK 配合 LogBus 也是比较通用的服务端数据采集方案
针对一般应用和 Web 开发,我们提供了:
- React Native SDK 使用指南
- Flutter SDK 使用指南
- 原生 SDK: Android SDK, iOS SDK
- 第三方框架: Flutter, Reactive Native
- H5 开发:JavaScript SDK, H5 与原生 SDK 打通方案
- 主流小程序、快应用平台:小程序 SDK
针对小游戏开发,我们提供了:
- 主流游戏引擎的支持: LayaBox, Egret 白鹭引擎, Cocos Creator
- 主流小游戏、快游戏平台的支持:小游戏 SDK
针对手游开发,我们提供了:
对于服务端采集方案,我们推荐使用服务端 SDK + Logbus 的方案。该方案在数据导入的稳定性、实时性、和效率方面都有比较好的表现。
如果您有一些异构的历史数据需要导入,或者对于部分数据需要补录到 TE 系统中,可以考虑使用 DataX 导入。与 Logbus 方案不同,DataX 不是常驻服务,无法监控新数据的产生并且及时导入,因此不能保证数据的实时性。 DataX 的优势在于支持多种数据源的异构数据导入,操作简单。
如果您使用了 Filebeat 和 Logstash 收集日志,并且希望将日志数据导入到 TE 系统,可以使用 Filebeat +Logstash 方案。
在设计数据采集方案的时候,可以根据您业务的情况,选择适合您产品技术架构和业务需求的解决方案。如果对采集方案有疑问,可以在支持群里咨询我们的分析师或者技术支持同事。
# 二、基础知识
# 2.1 TE 数据模型
在进行数据接入之前,首先我们需要理解 TE 中的数据是什么。
数据采集方案的设计实际上就是根据业务分析的目标确定采集哪些用户行为事件的过程。例如,如果要分析用户充值情况,要采集的可能是用户支付行为数据。用户行为数据可以分解为:谁 (WHO),什么时候 (WHEN),在哪里 (WHERE),以什么方式 (HOW),进行了充值行为 (WHAT),如下图所示:
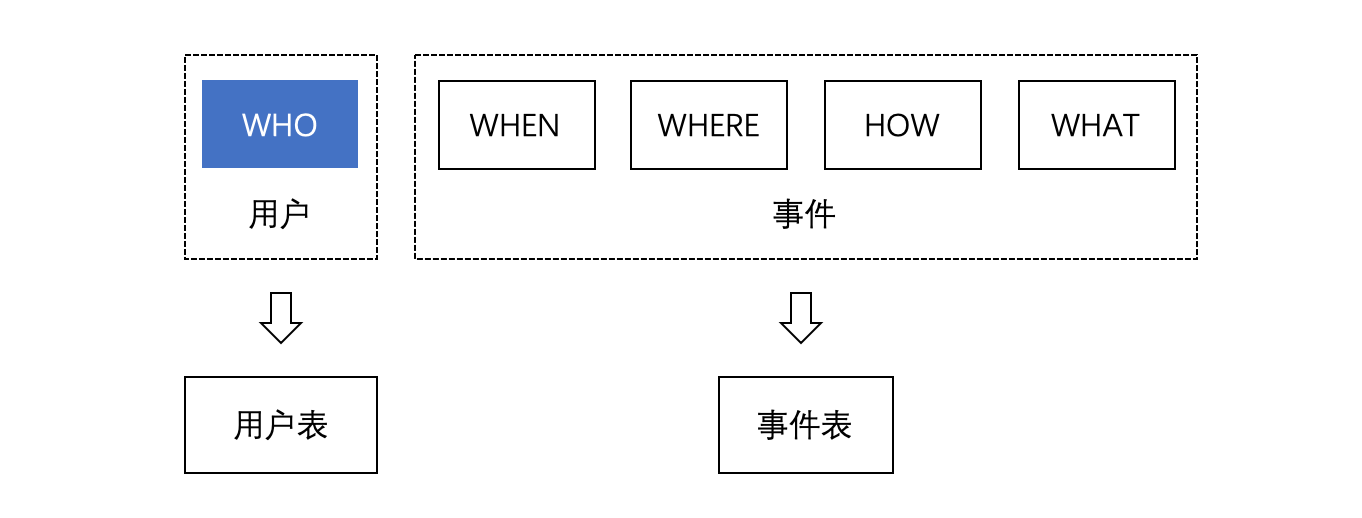
用户行为数据在 TE 中会被组织成用户相关数据和事件相关数据,并分别存入用户表和事件表中。用户数据主要用于描述用户的状态和不会经常发生变化的属性。事件数据用于描述与具体行为事件相关的信息。
在数据采集方案中,您需要确定在什么时机需要触发用户数据的上报,在什么时机需要触发事件的上报。关于用户数据和事件数据的进一步了解,可以参考:设置用户属性与事件属性。
在我们的所有数据接入指南中,都会分别介绍上报事件数据和用户数据的方法。
# 2.2 用户识别规则
对于每一条用户数据或者事件数据,都需要明确该数据是属于哪一个用户。在没有账号体系的场景中,可以使用与设备相关的 ID 来唯一标识用户。但是对于有账号体系中的场景中,一个用户可能在多个设备中产生数据,在分析中有必要将用户在多个端的数据结合起来分析,与设备相关的唯一 ID 就不适用了。
为了处理以上两种场景,在数据接入的过程中,需要结合两个用户 ID 来标识用户:
- 访客 ID (#distinct_id):默认情况下,客户端会生成随机的访客 ID 来标识用户,也提供了读取和修改默认访客 ID 的接口。
- 账号 ID (#account_id):当客户登录的时候,可以设置账号 ID。通过账号 ID 可以将多个设备中的数据关联起来。
每一条数据中,必须包含访客 ID 或者账号 ID。客户端 SDK 默认情况下会随机生成访客 ID,在您调用 login 接口设置账号 ID 之后,所有的数据在上报的时候会同时携带访客 ID 和账号 ID。通过服务端上报的时候,您至少需要传入其中一个 ID。
在 TE 后台,标识一个用户的唯一 ID 为 TE 用户 ID(#user_id 字段)。当接收到数据时,我们会根据指定的用户识别规则,来创建一个新用户,或者将数据绑定到一个已有用户上。
用户识别规则是非常重要的内容,如果没有正确设置用户 ID,可能会造成数据绑定到错误的用户上,影响分析效果。在接入之前请务必仔细了解该规则,并在数据采集方案中明确用户识别方案。
# 2.3 数据格式
无论通过哪一种方式接入数据,在发送到数据接收端的时候都使用统一的数据格式,和相同的数据限制。数据规则一章对数据格式和对应的数据限制做了详细的描述。
如果您通过 SDK 对接数据,只需要调用对应的接口,SDK 会将数据整理成需要的数据格式进行上报;如果您通过数据导入工具或者Restful API接入数据,则需要根据数据规则中的描述整理好数据格式,然后上报。
关于数据格式,需要特别注意命名规则和数据类型:
- 命名规则:事件名和属性名都只能包含字母、数字、和下划线 _,以字母开头,不能超过 50 个字符
注意:属性名对大小写不敏感;事件名对大小写敏感
- 属性值数据类型:
| TE 数据类型 | 取值样例 | 取值说明 | 数据类型 |
|---|---|---|---|
| 数值 | 123,1.23 | 数据范围是-9E15 至 9E15 | Number |
| 文本 | "ABC","上海" | 字符的默认上限是 2KB | String |
| 时间 | "2019-01-01 00:00:00","2019-01-01 00:00:00.000" | "yyyy-MM-dd HH:mm:ss.SSS"或"yyyy-MM-dd HH:mm:ss",如需表示日期,可使用"yyyy-MM-dd 00:00:00" | String |
| 布尔 | true,false | - | Boolean |
| 列表 | ["a","1","true"] | 列表中的元素都会转变为字符串类型,列表内最多 | Array(String) |
| 对象 | {hero_name:"刘备",hero_level:22,hero_equipment: ["雌雄双股剑","的卢"],hero_if_support:False} | 对象内的每个子属性(Key)都有自己的数据类型,取值说明请参考上面对应类型的普通属性· 对象内最多100个子属性 | Object |
| 对象组 | [{hero_name:"刘备",hero_level:22,hero_equipment: ["雌雄双股剑","的卢"],hero_if_support:False}, {hero_name:"刘备",hero_level:22,hero_equipment: ["雌雄双股剑","的卢"],hero_if_support:False}] | 对象组内的每个子属性(Key)都有自己的数据类型,取值说明请参考上面对应类型的普通属性 对象组内最多500个对象 | Array(Object) |
注意:在 TE 后台,属性值的类型会根据第一次收到该属性值的类型确定,后续如果数据中某个属性的值的类型与此前确定的类型不符,该属性将被丢弃。
在 TE 后台,您可能会注意到某些属性名是以 # 开头的,此类属性为预置属性。预置属性不需要特别设置,SDK 会默认采集。具体可以参考:预置属性与系统字段。
您需要特别注意的是,当数据格式或者数据类型没有正确设置的时候,数据无法入库。因此在接入阶段和接入之后,你可能需要通过埋点管理模块来检验或者观察数据上报的正确性,并对出现的问题及时修正。
# 三、接入必备信息
在正式由研发进行数据接入之前,需要确保以下信息已经准备好:
- 项目 APP ID:在 TE 后台创建项目的时候会生成项目的 APP ID,也可以在项目管理页面查看
- 确定数据接收端地址
- 如果使用云服务, 接收端地址为: https://global-receiver-ta.thinkingdata.cn
- 对于私有化部署的情况,需要在私有集群(或者接入点)绑定域名,并配置 SSL 证书
- 验证接收端地址:浏览器访问 https://YOUR_RECEIVER_URL/health-check,页面返回 ok 表示正确
- 数据采集方案,要包括:
- 数据接入的方式:客户端 SDK、服务端 SDK、数据导入工具、或者几种方案结合的方式
- 待接入数据的内容和触发时机
恭喜您完成了接入前准备文档的阅读。接下来,您就可以根据选定的接入方式,参考对应的接入指南文档,开始进行数据接入了。