# リテンション分析
# 1、リテンション分析の意義
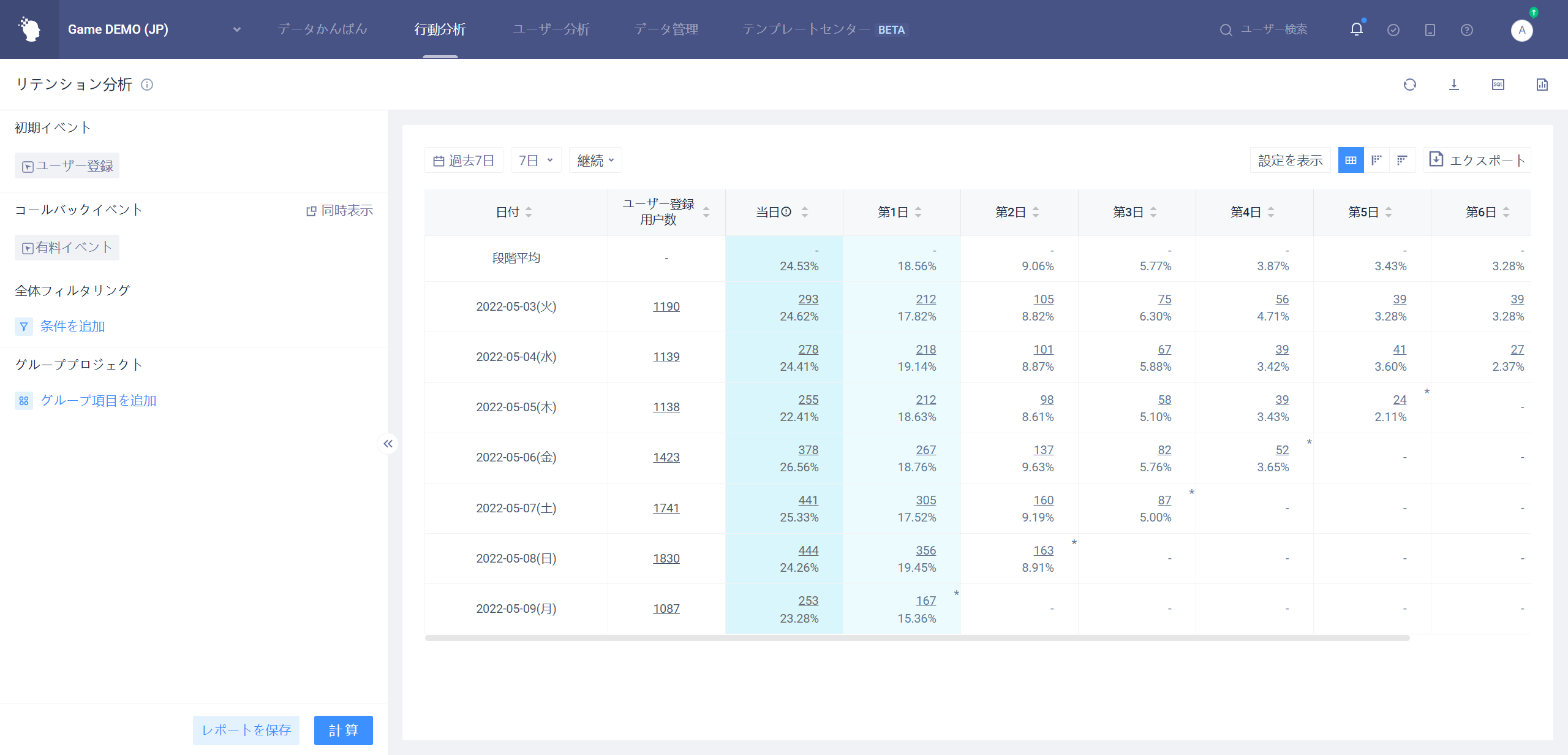
留保分析は主にユーザーの全体的な参加度、活躍度の状況を分析し、ある初期行為を行ったユーザーのうち、訪問行為を行う人数と割合を調べる。
分析モデルを残すことで、ある初期事件のユーザーの訪問状況を分析し、事件の影響をマクロ的にコントロールし、意思決定を最適化することができる。
ユーザーの活躍から消費まで、例えば、次のような問題を解決できる
- ユーザーが製品を使用してから 1 ヶ月以内に消費転換を行った人数と占有状況は?
- ユーザーが製品を使用してから 1 ヶ月以内に消費を完了し、消費金額が 200 元に達した人数と占有状況は?
- 上海ユーザーが製品を使用してから 1 ヶ月以内に消費転換を行った人数と比率は?
- 第一線の都市ユーザーが製品を使用してから 1 ヶ月以内に消費を完了し、消費金額が 200 元に達した人数と占有状況は?
- 全ユーザーの 30 日 LTV 事情はいかに
# 2、リテンション分析の位置と必要な権限
トップナビゲーションバーの「行動分析」で「残留分析」を選択すると、残留分析モデルに
| ルートアカウント | 管理者 | アナリスト | 一般メンバー | |
|---|---|---|---|---|
| 残存分析モデル | ● | ● | ▲ | △ |
権限の説明:
●:必須
▲:デフォルトであり、なくてもよい
△:デフォルトではなく、あります
○:必ずなし
# 三、分析を残すページの概要
リテンション分析は指標設定区、展示設定区、展示グラフ区の三つの部分に分けられる。分析角度を設定することで分析内容を決定できる。表示フィルターオプションを選択して、グラフ領域に必要な分析表やグラフ
# 四、分析の使用シーンを残す
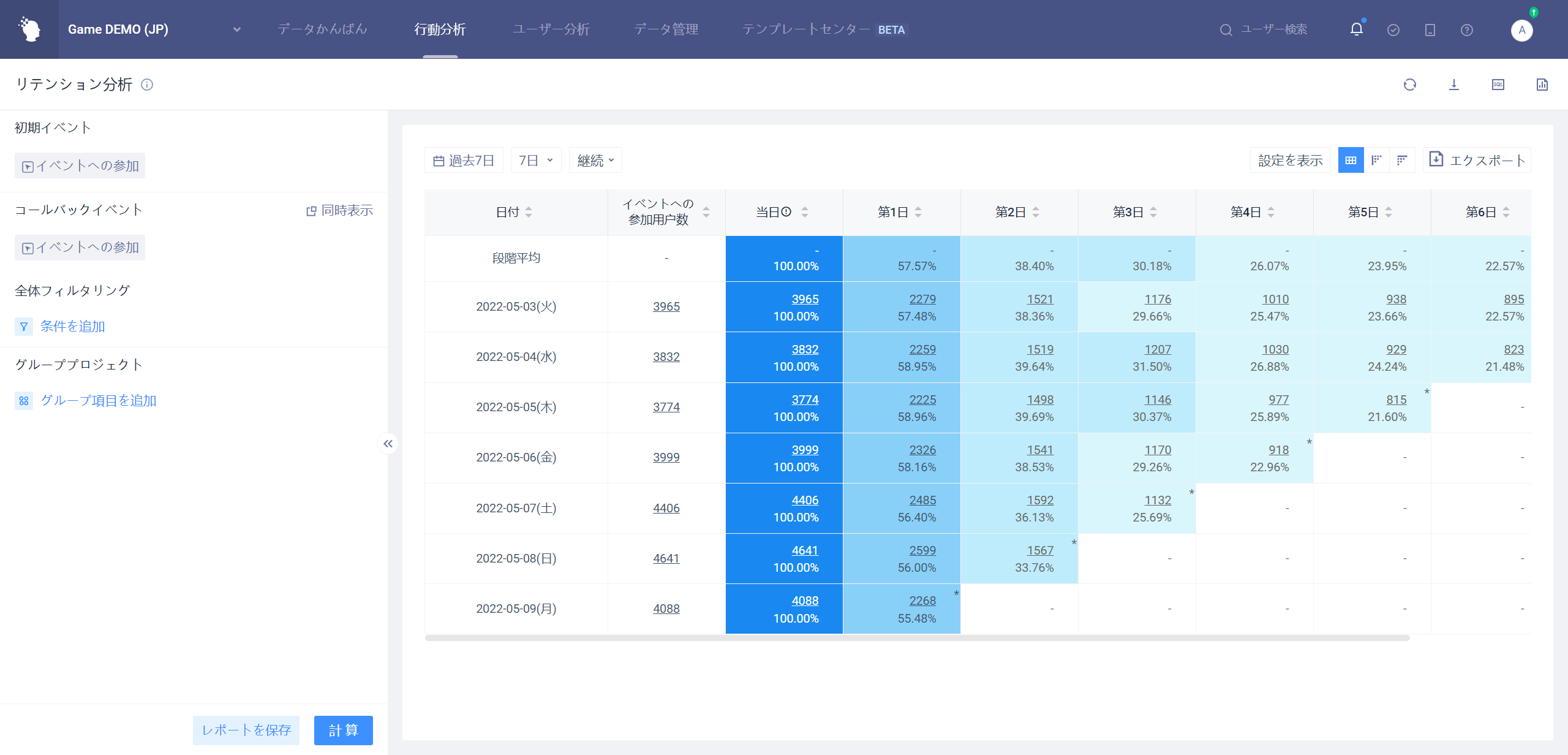
# 4.1よく使われるいくつかの分析シナリオ
# 4.2分析指標の設定
# 4.2.1初期イベントの選択
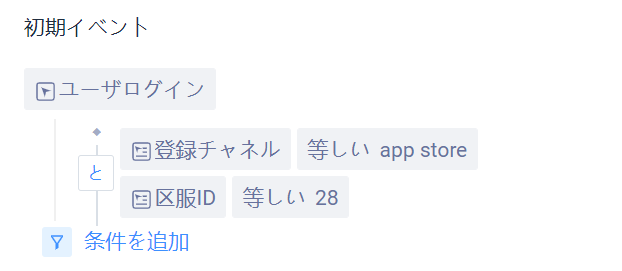
初期イベントの動作があったユーザーは、分析サンプルのデータソースとして機能し、分析全体で機能します。選択ボックスでは、「メタイベント」または「任意イベント」を選択できます。意味は、特定の日にイベントを行ったユーザーです。特定の日に任意のイベントをしたユーザーには「彼らはこの時間に活躍した」と理解できる。
# 4.2.2選別条件の選択
イベントフィルタリング
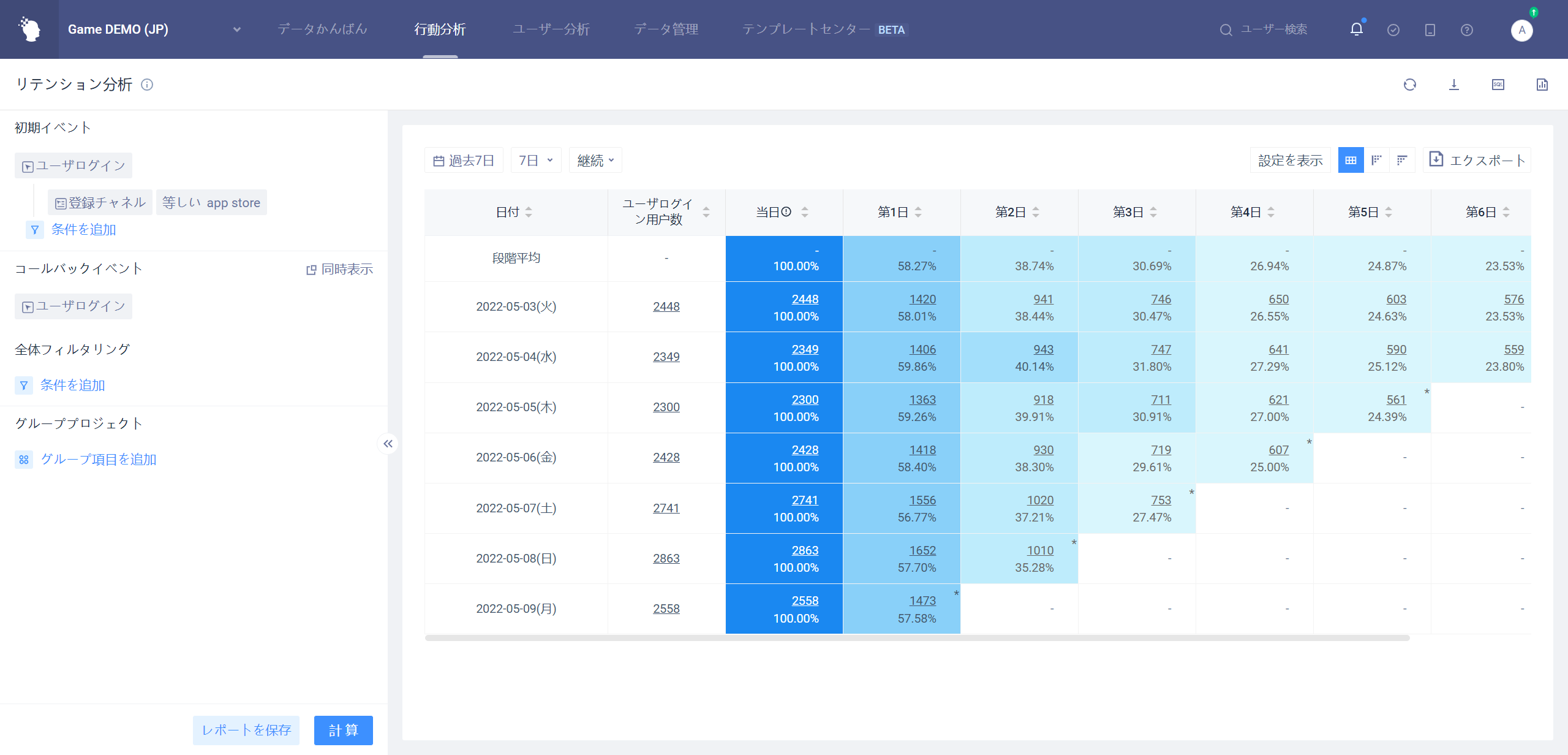
選別条件は主に特定の人たちの使用状況を正確に見るために設計され、例えば上海の男性ユーザーのリテンション状況を分析する。初期イベントと訪問イベントを同時に条件選別することができる。で「選別条件」、ある特徴に合ったイベントやユーザーを選出し、分析する。
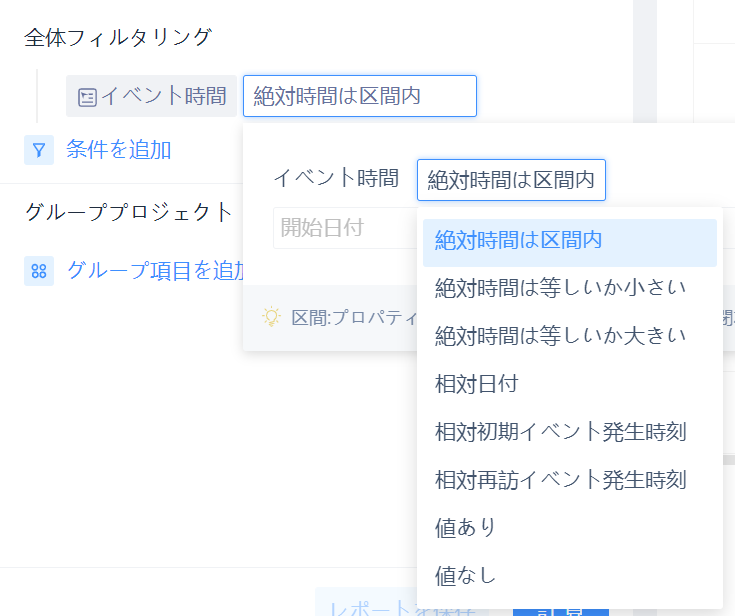
グローバルフィルタリング
「グローバルスクリーニング」のスクリーニング条件が時間タイプの場合、スクリーニング条件には相対的な初期イベント発生時刻または相対的な訪問イベント発生時刻
# 4.2.2.1プロジェクトルール
| 分析オブジェクト | プロジェクトの選別 |
|---|---|
| メタイベント | メタイベントでのイベント属性、任意のユーザー属性、任意のユーザーグループ |
| 任意のイベント | すべてのイベントに共通するイベント属性、任意のユーザー属性、任意のユーザーグループ |
選別項目が「ユーザーグループ」を選択する場合、「グループに属する」か「グループに属さない」かを選択できる。
# 項目と属性論理との関係を選別4.2.2.2する
[プロパティロジック]は[アイテムのフィルタリング]のデータ型に関連付けられます:
| フィルタ項目のデータ型 | 例 | サポート可能なプロパティロジック |
|---|---|---|
| 数値 | 消費金額 | 等しい、等しくない、小さい、小さい、等しい、大きい、大きい、等しい、値がある、値がない、区間 |
| テキスト | 州 | 等しい、等しくない、含む、含まない、値がある、値がない、正則マッチング |
| リスト | IDリスト | 要素が存在する、要素が存在しない、要素の位置、値がある、値がない |
| 時間 | 登録時間、最終アクティブ日(yyyy-MM-dd HH: mm: ss.SSSまたはyyyy-MM-dd HH: mm: ss) | 区間に位置し、等しい未満、等しい以上、相対的な現在時間、相対的な初期イベント発生時刻、相対的な訪問イベント発生時刻、値がある、値がない |
| ブール | Wifiの使用 | 真、偽、価値がある、価値がない |
| オブジェクト | プレイヤーリソースのスナップショット | 値がある、値がない |
| オブジェクトグループ | 出陣陣 | 存在対象充足、無対象充足、全対象充足、有値、無値 |
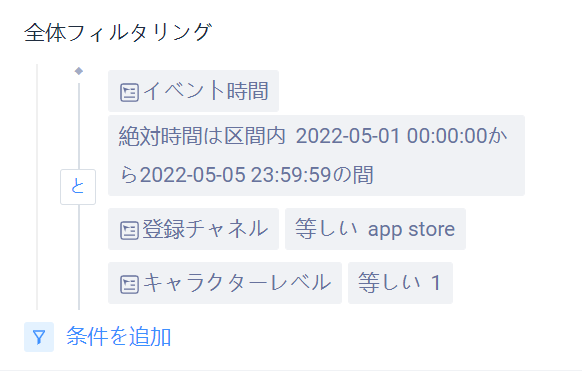
# フィルタ項目、属性論理、有効な関連値間の関係を4.2.2.3する
【関連値】は【属性論理】に対応する関連:
選別項目のデータ型が「時間」、属性論理が「区間」の場合、分析する時間帯を選択できます。
フィルタ項目のデータ型が「数値」で、属性論理が「区間」の場合、関連値は数値区間に埋めることができる。
属性論理が「値あり、値なし、真、偽」の場合、関連値を記入する必要はない。
プロパティロジックが別の場合、関連する値を選択または入力できます。
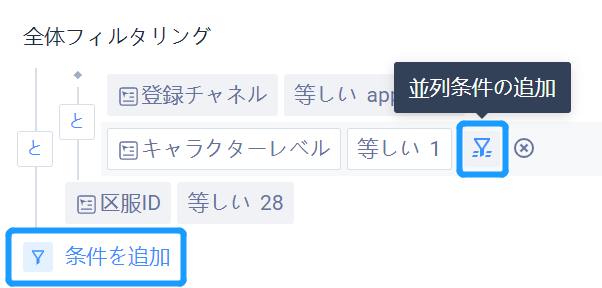
# マルチフィルタ条件4.2.2.4場合、フィルタ条件間論理を設定する
選別条件が2つ以上の場合に現れ、デフォルトは「かつ」で、クリックして「または」に切り替えることで、異なる応用シーンに適応できる。
同時に、2層の論理ネストをサポートして、ある選別条件の後に「並列条件を追加」したり、選別全体に「条件を追加」
# 4.2.3コールバックイベントの選択
訪問ユーザとは、初期イベントを満たすユーザが特定の時間後に訪問イベントを完了するユーザである。選択ボックスでは、「メタイベント」または「任意イベント」を選択できます。つまり、特定の日にこのコールバックイベントを行ったユーザーです。特定の日に任意のイベントをしたユーザーには「彼らはこの時間に活躍した」と理解できる。
# 4.2.4同時展示オプションの選択
# オプションの意味を同時に示す4.2.4.1
リテンションユーザーを分析選別すると同時に、リテンションユーザーをより深く分析する可能性があります。
例えば、ユーザーのアクティブ、有料、LTVなどのデータを独立して分析すると、同時に機能の深さを示すことで特定の指標
# オプションの入り口を同時に見せる4.2.4.2
マウスを「コールバックイベント」に移動すると、対話オプション

「同時展示」をクリックすると、分析する内容が現れ、ドロップダウンボックスで必要なイベントと分析角度
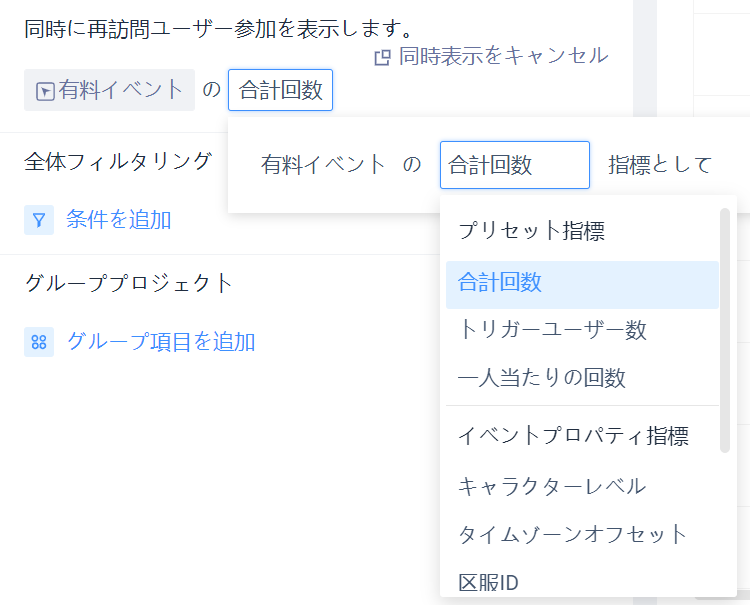
# 4.2.4.3同時に示す分析角度
事件分析の分析指標類似しているが、指標は「事件」+「属性」+「計算方法」または直接「事件」+「計算方法」で
イベント記述、指標記述のデータ型によって、異なる分析可能な角度、数値型とブール型のイベント属性だけをサポートし、他のタイプのイベント属性
| イベントの説明 | 指標の説明/データ型 | 分析の角度 |
|---|---|---|
| 任意のイベント | 総回数、トリガーユーザー数、一人当たり回数 | |
| メタイベント | 総回数、トリガーユーザー数、一人当たり回数 | |
| メタイベント | イベントプロパティ(数値型) | 合計、人平均、段階累積合計、段階累積人平均 |
| メタイベント | イベントプロパティ(ブール型) | は真数、は偽数、は空数、は空数 |
# 同時に示す値と計算論理を4.2.4.4する
1.初期イベント、訪問イベントの選別は同時展示に有効
2.フェーズ累積合計の概念
N日目の段階累計総和は、M名の初期ユーザをサンプルとして残すため、0日目からN日目まで、このN日の全ユーザにおける当該イベント属性値の全数の総和
3.フェーズ累積一人当たりの概念
N日目の段階累積合計は、M名の初期ユーザーをサンプルとして残すために、0日目からN日目まで=(すべてのユーザーがこのN日でこのイベント属性値の全数の合計/M)
4.段階平均時の計算ロジック
| イベントの説明 | 指標の説明/データ型 | 分析角度—算数平均の選択 | 分析角度—加重平均の選択 |
|---|---|---|---|
| 任意のイベント | 合計回数、トリガーユーザー数 | 一人当たりの回数 | |
| メタイベント | 合計回数、トリガーユーザー数 | 一人当たりの回数 | |
| メタイベント | イベントプロパティ(数値型) | 合計、人平均、段階累積合計 | 段階累積人平均 |
| メタイベント | イベントプロパティ(ブール型) | は真数、は偽数、は空数、は空数 |
# 数式として4.2.4.5ながら指標を示す
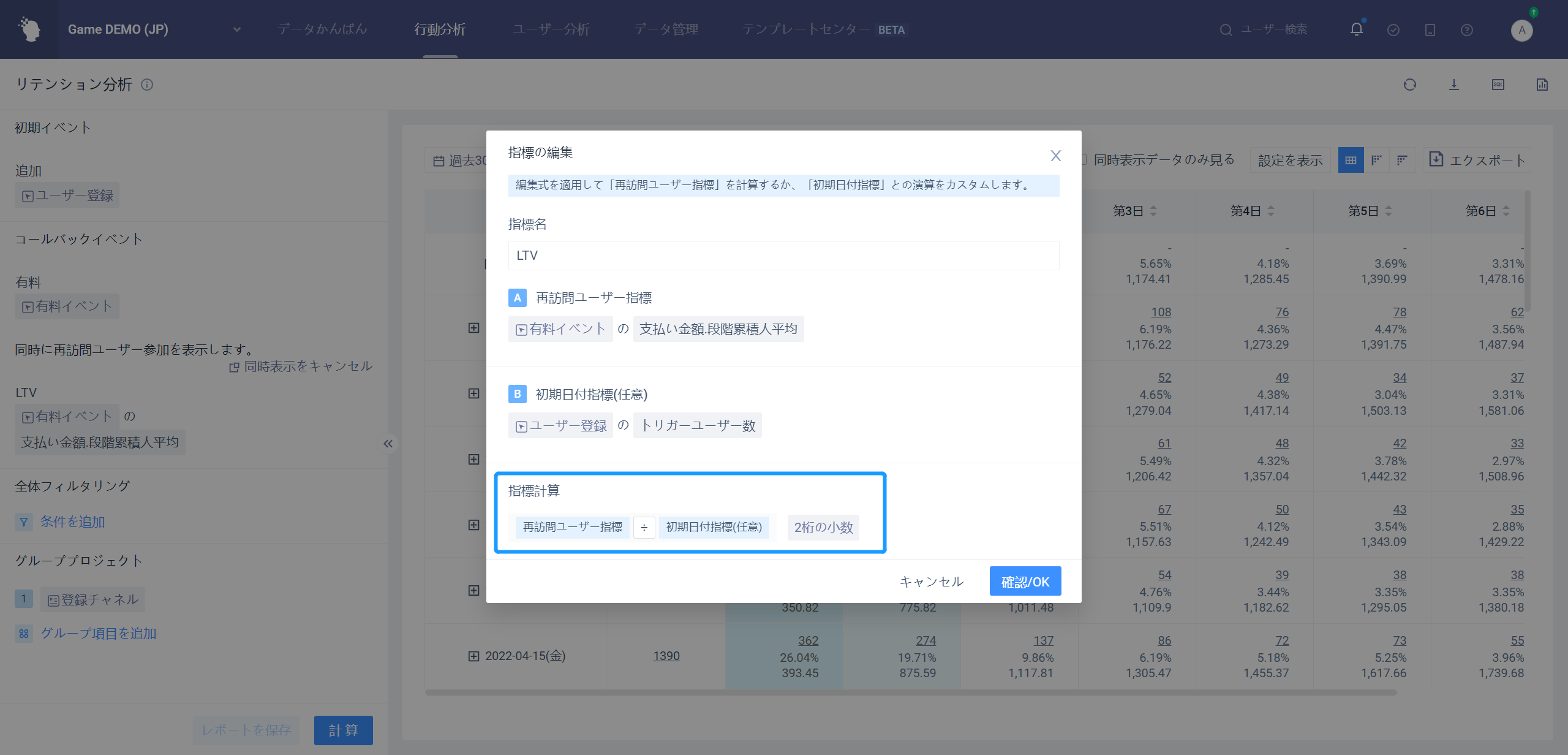
直接「「事件」+「属性」+「計算方法」または直接「事件」+「計算方法」で同時展示指標を構築するだけでなく、事件分析のように式を同時展示指標とし、「指標編集を開く」ボタンをクリックして式編集弾倉
(1)訪問ユーザー指標のみ
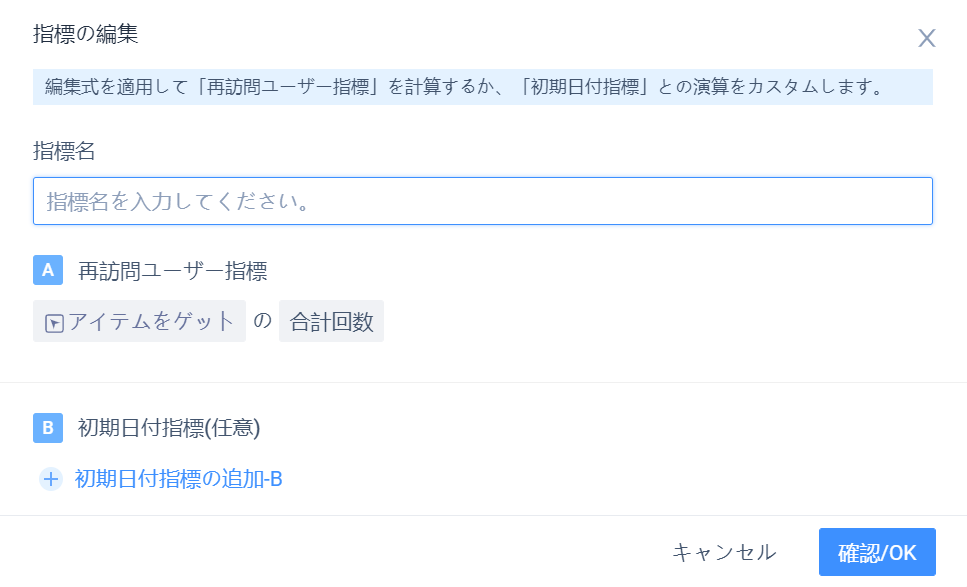
訪問ユーザーの指標の下で、指標式に切り替えることができ、操作と事件分析式の編集が一致し、オプションの「属性」+「計算方法」は4.2.4.3同時に展示する分析角度の節
(2)訪問日指標と初期日指標を組み合わせる
数式編集弾倉では、「初期日付指標」を追加し、「訪問ユーザー指標」との演算
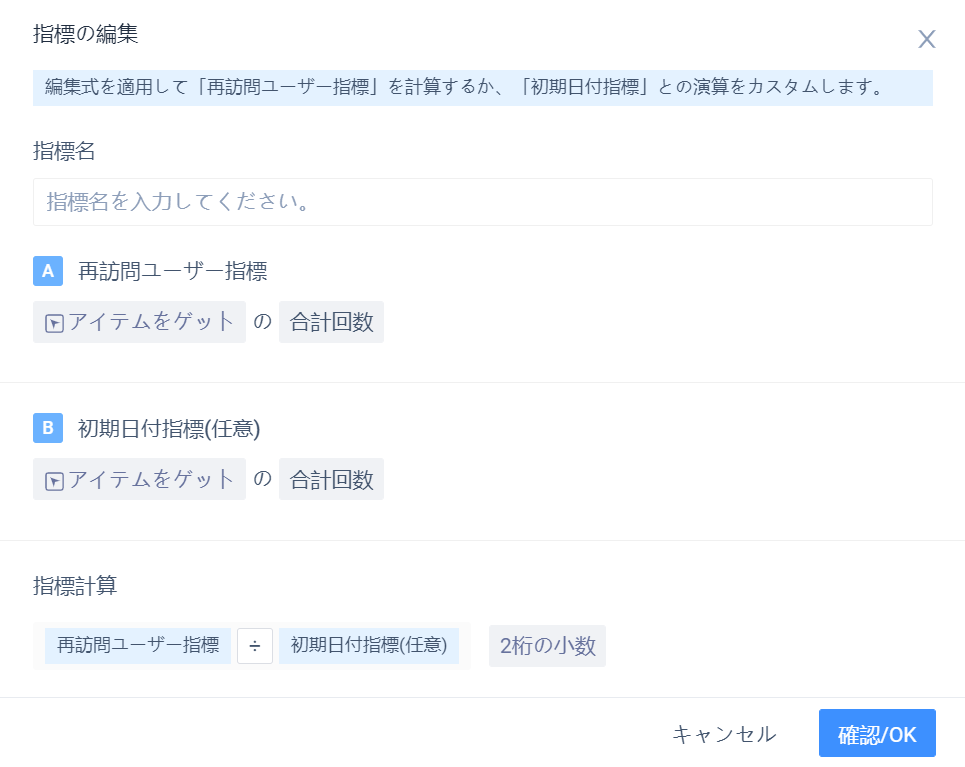
指標を同時に表示すると指標計算の結果で表示されるほか、データシートスタイルの下に「初期日付指標」
# 4.2.5グループアイテム
# 4.2.5.1グループ化項目の設定
選択可能初期イベントイベント属性、ユーザー属性、ユーザーサブグループ、ユーザータググループ項目
# グループ化オプションを削除4.2.5.2ます
追加と削除の対話論理はイベント分析と一致している。
# 数値型、時間型、リスト型パケットデータの集計パケット
数値型データは区間ごとにまとめることができ、デフォルト区間、離散数字、カスタム区間の3つのオプションがある。
時間型データは時間粒度でまとめることができ、日、分、時間、週、月の5種類のオプションがある。
リスト型データは、要素別、リスト全体別、要素集合別の3つのオプションを選択してまとめることができる。
# 4.2.5.4グラフグループ設定

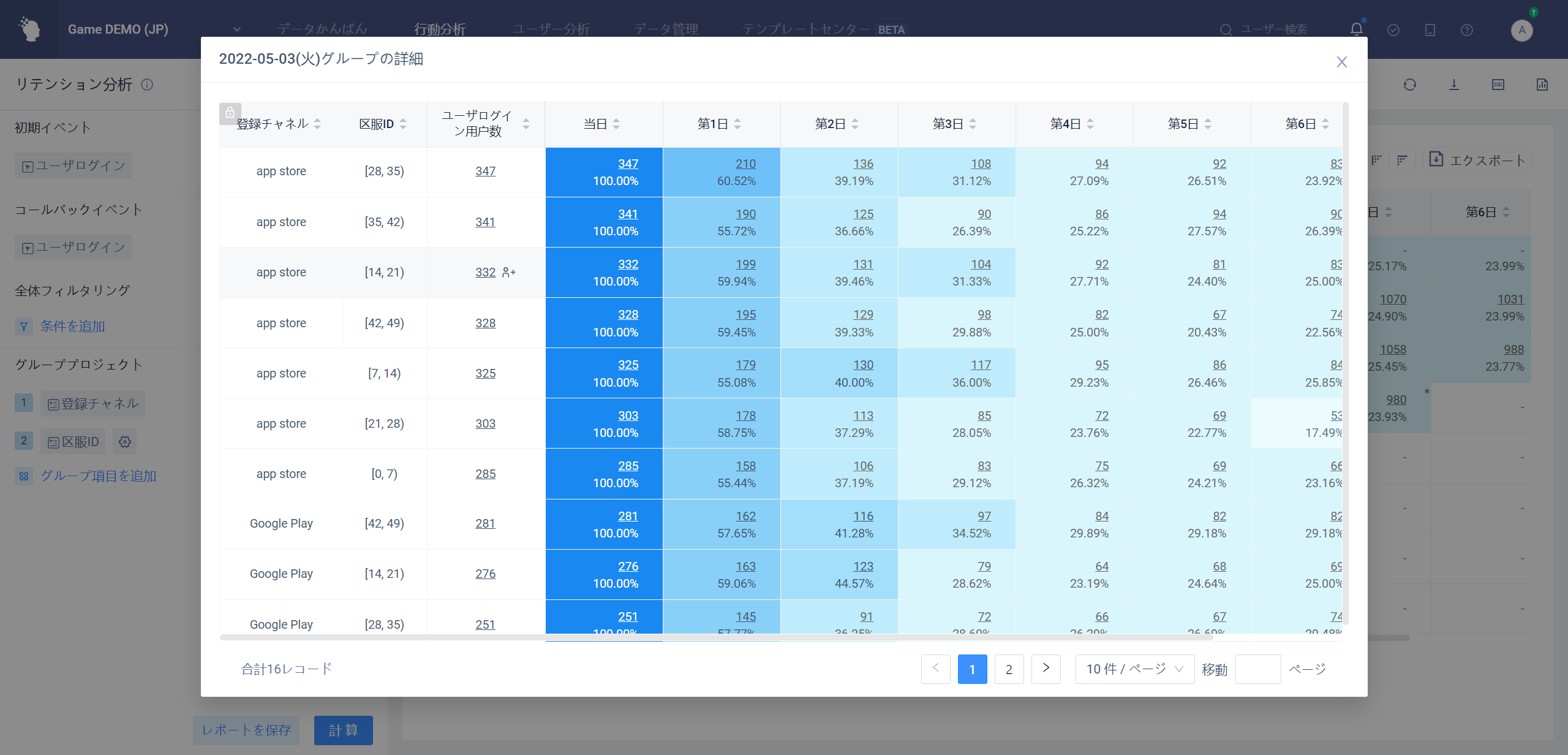
# 4.2.5.5グループ化プレゼンテーション
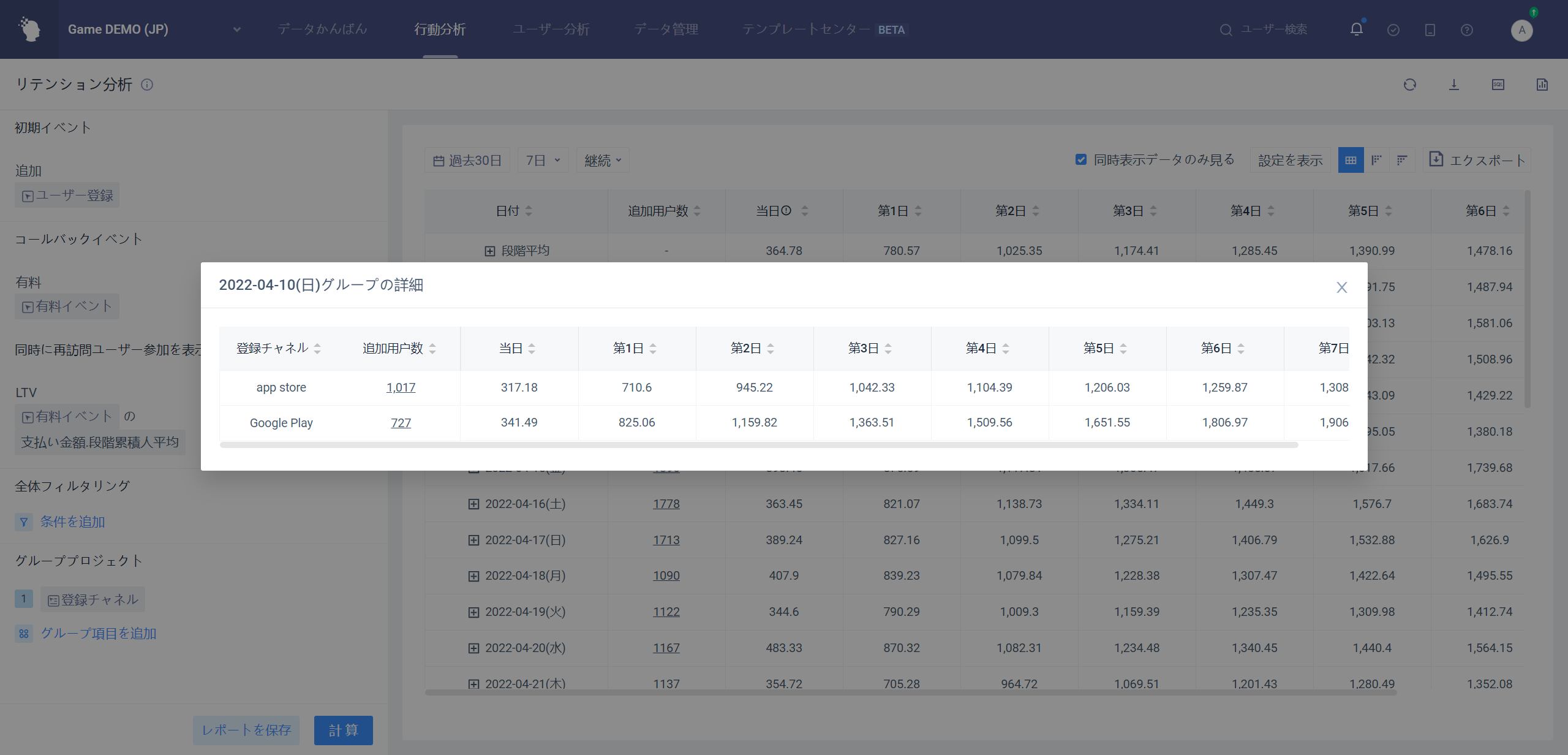
データシートスタイルで、「+」ボタンをクリックしてポップアップウィンドウでグループの詳細
# 4.2.6リテンション・流失・グルーピングの判断ロジック
# 4.2.6.1残る判断ロジック
ある日に「初期イベント」が発生したユーザーは、N日目に「訪問イベント」が発生した。
「予約数」は、N日目のすべての「予約ユーザー」の総数です。
「リテンション割合」は、N日目のすべての「リテンションユーザー」の総数と、ある日に「初期イベント」が発生したユーザーとの比である。
# 4.2.6.2喪失の判断ロジック
ある日に「初期イベント」が発生したユーザーは、その後1日目からN日目まで「訪問イベント」が発生していない、つまりN日目の「流出ユーザー」である。
「流出数」は、N日目のすべての「流出ユーザー」の総数です。
「流出割合」は、N日目のすべての「流出ユーザー」の総数と、ある日に「初期イベント」が発生したユーザーとの比である。
# 4.2.6.3週(月)のリテンション/流失の判断論理
ある分析角度が週(月)のリテンション/流失の場合、分析時間区間は自動的に自然週に切り替わる。
時間選択ボックスは、元の日付に含まれる週/月を完全な自然週/月に自動的に拡張します。
あるユーザーの+N週でのリテンション、つまり第N週の完全な自然週では、訪問イベントが完了すればリテンションとなる。
同様に、あるユーザーの+N週での流失、つまり第1週~第N週の完全な自然週では訪問イベントが完了していない、つまり流失である。
# パケット4.2.6.4時の判定ルール
原則:ユーザー属性は、最初のトリガーに基づいて統合されます。リテンション/流失判断は反復計算である。
例: 1月1日から1月8日まで、あるユーザーは毎日1つのことを行い、そのユーザーの行動系列はA、A、B、A、A、A、B、Bである。分析対象は「1月1日から1月8日までの7日間のリテンション、省別グループ」。
あるユーザーが事件Aを完成した省が異なる場合、そのユーザーは1月1日に事件Aが発生した省にしか分類されない。重い後、毎日の行動がその後に与える影響を検証する。このユーザーはそれぞれ1日目、2日目、3日目、4日目、5日目、6日目、7日目の予約ユーザーです。
# 4.3展示設置区の設置
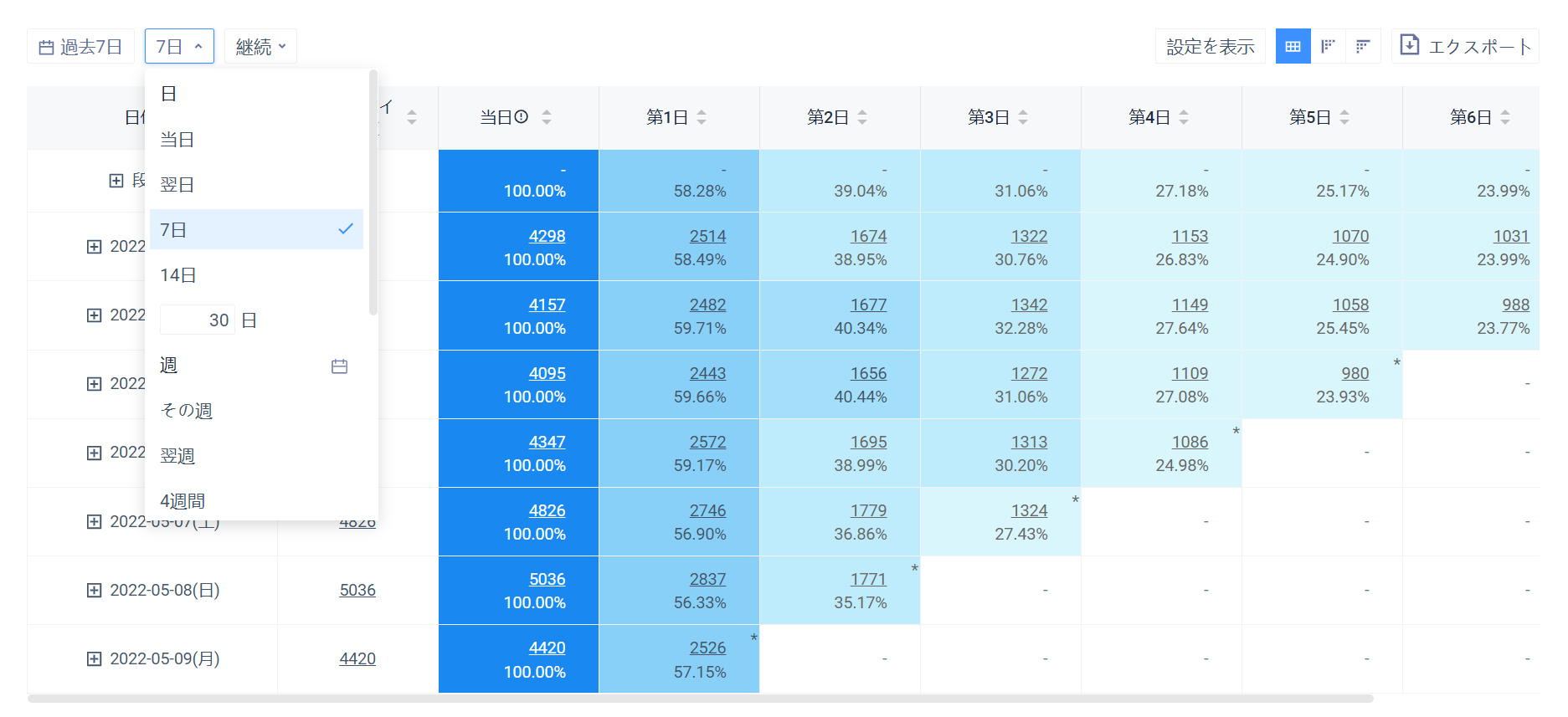
# 4.3.1分析期間、分析期間と指標
- 「分析期間」で分析指定期間のデータ
- 「分析期限」で異なるボリューム(日、週、月)でのリテンション、流失表現
- で「指標」で「リテンション、流失」

# 4.3.2表示設定
(1)展示方式
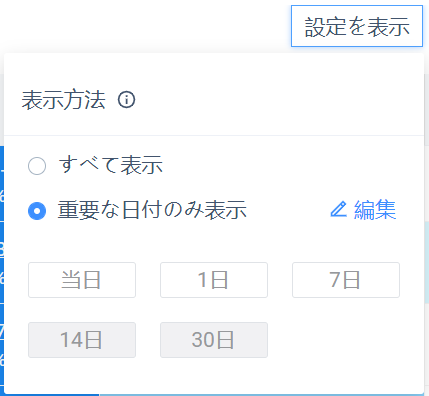
表示方式はデフォルトで「すべて表示」で、重要な日付だけを見たいなら「重要な日付だけを表示」オプションを選択し、編集をクリックするとすぐに調整できます。この場合、グラフ表示時に他の重要でない日付(列)のデータ表示がフィルタリングされます。
(2)ショーケースを保持する
予約モデルは【当日、第1日、第2日(週/月).。。。。。”】定義を変更するには、[当日、翌日、3日(週/月)]を押してください
# 4.4グラフの提示とデータダウンロード
# 4.4.1グラフスタイルがデータテーブルの場合の表示
ここで、分析期間の選別ボックスと表のリテンション期間には次のような対応関係がある
| 分析期間フィルターボックス | 保持期間 |
|---|---|
| 翌日 | 1日後 |
| 3日だ | 1日後、2日後、3日後 |
| 7日は | 1日後、2日後、3日後、4日後、5日後、6日後、7日後 |
| 14日は | 1日後、2日後、3日後、4日後、5日後、6日後、7日後。。13日後、14日後 |
| 30日だ | 1日後、2日後、3日後、4日後、5日後、6日後、7日後。。29日後、30日後 |
| 次の週 | 1週間後 |
| 4週間 | 1週間後、2週間後、3週間後、4週間後 |
| 8週間 | 1週間後、2週間後、3週間後、4週間後、5週間後、6週間後、7週間後、8週間後 |
| 翌月 | 1月以降 |
| 3月の | 1月後、2月後、3月後 |
| 6月の | 1月後、2月後、3月後、4月後、5月後、6月後 |
| 12月の | 1月後、2月後、3月後、4月後、5月後、6月後。。11月後、12月後 |
# 同時に展示する展示内容を増やさない4.4.1.1
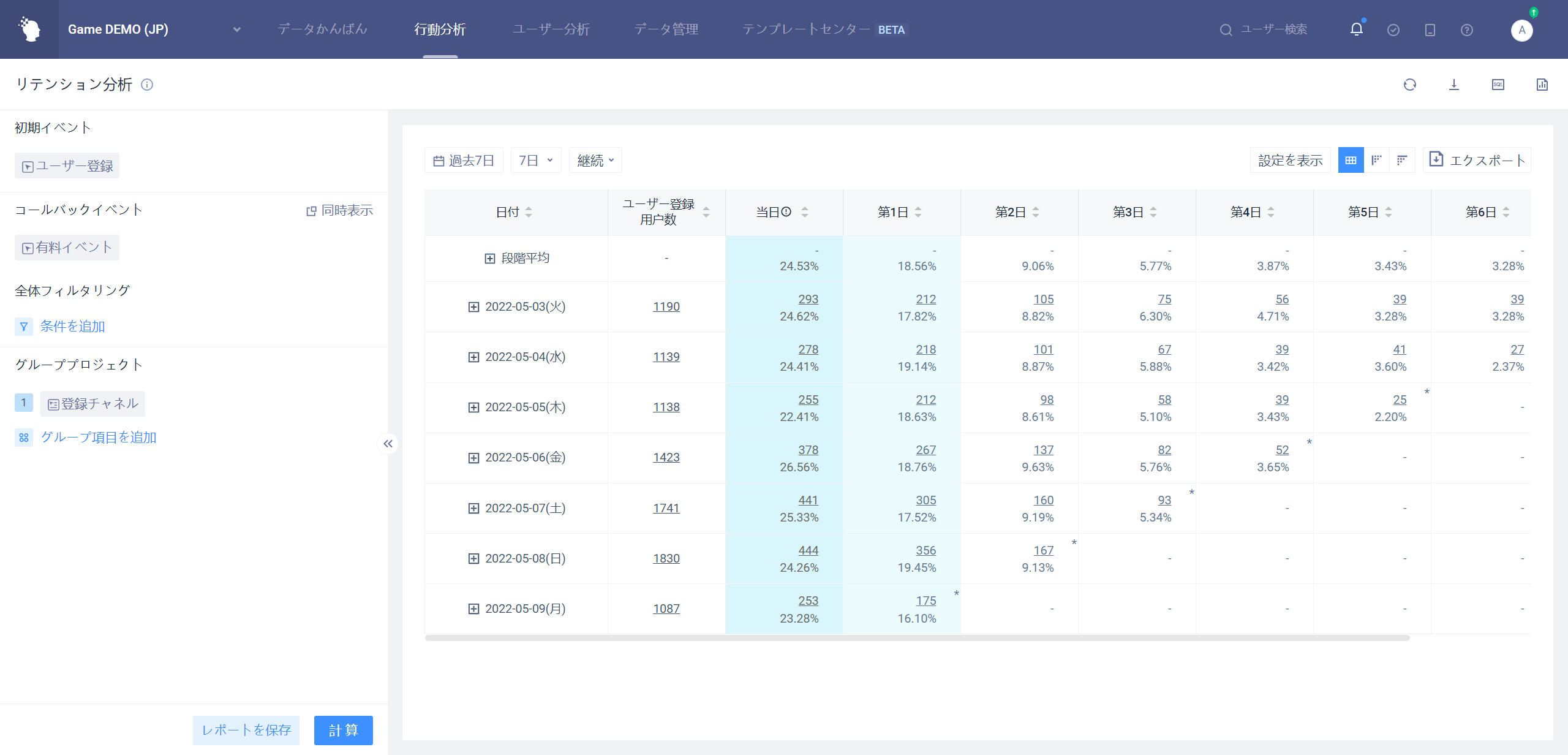
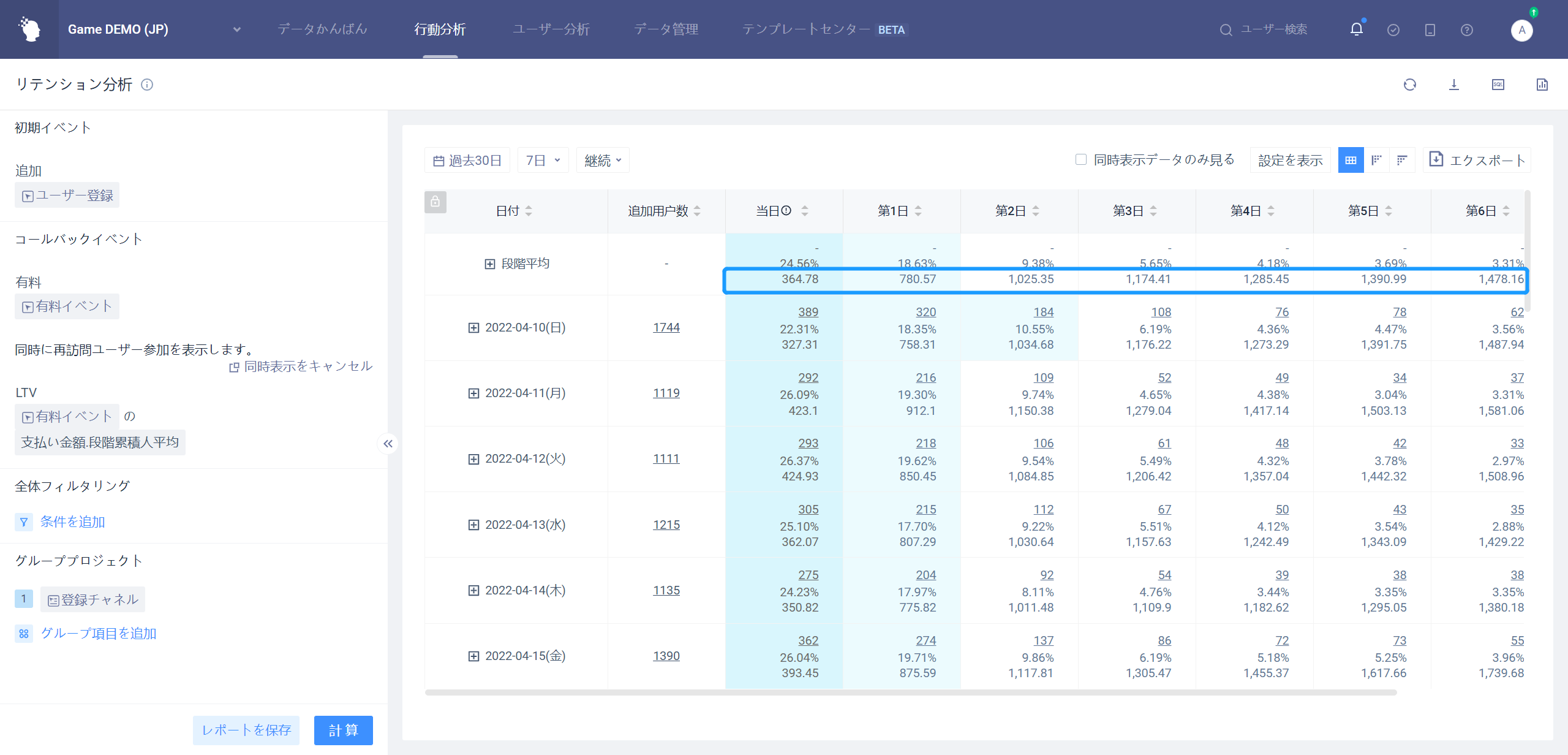
# 同時に展示する展示内容を増やす4.4.1.2
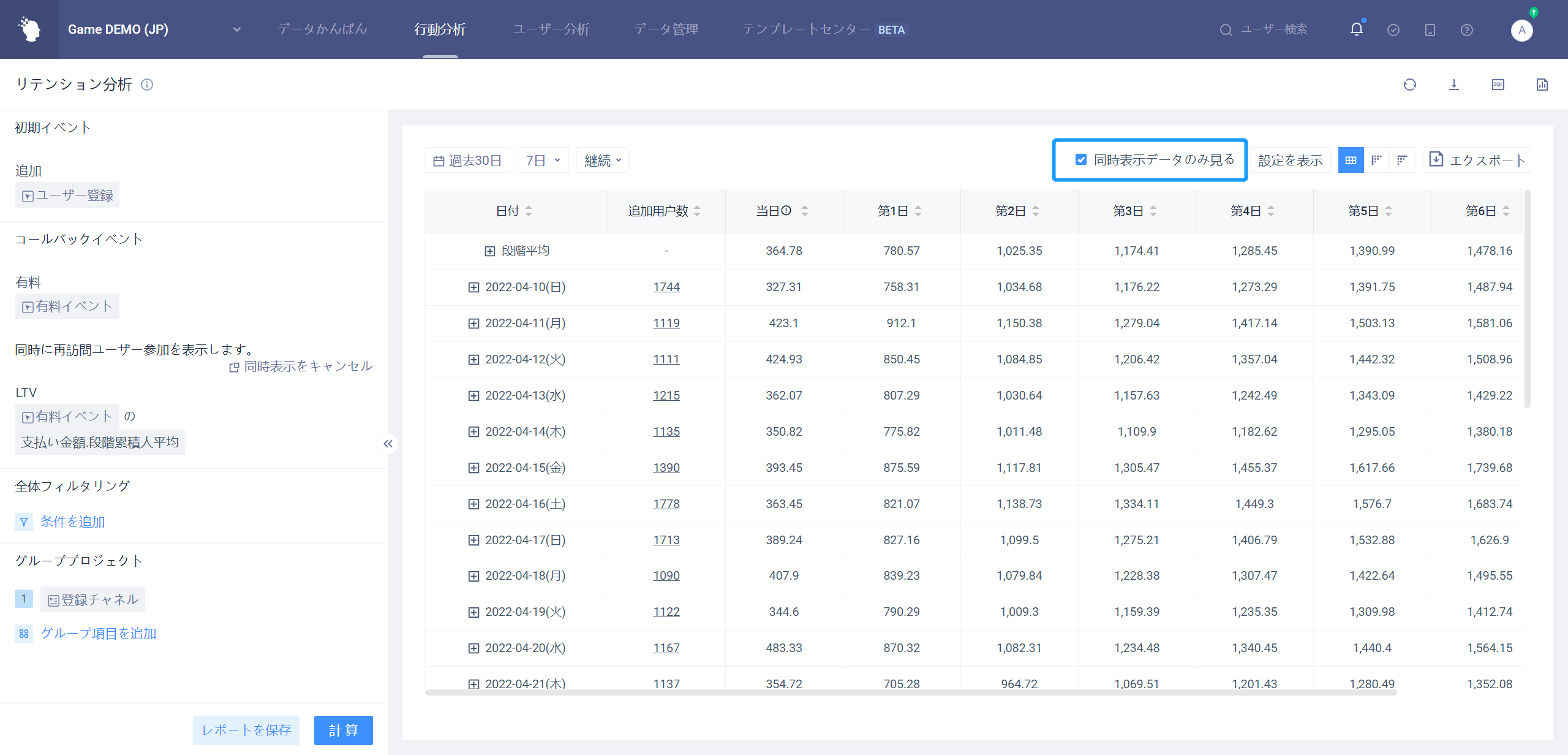
# 同時に展示された展示内容だけを見4.4.1.3
# グループ化を4.4.1.4た場合のプレゼンテーション
# 4.4.2グラフスタイルがN番目の日に残っている場合の表示
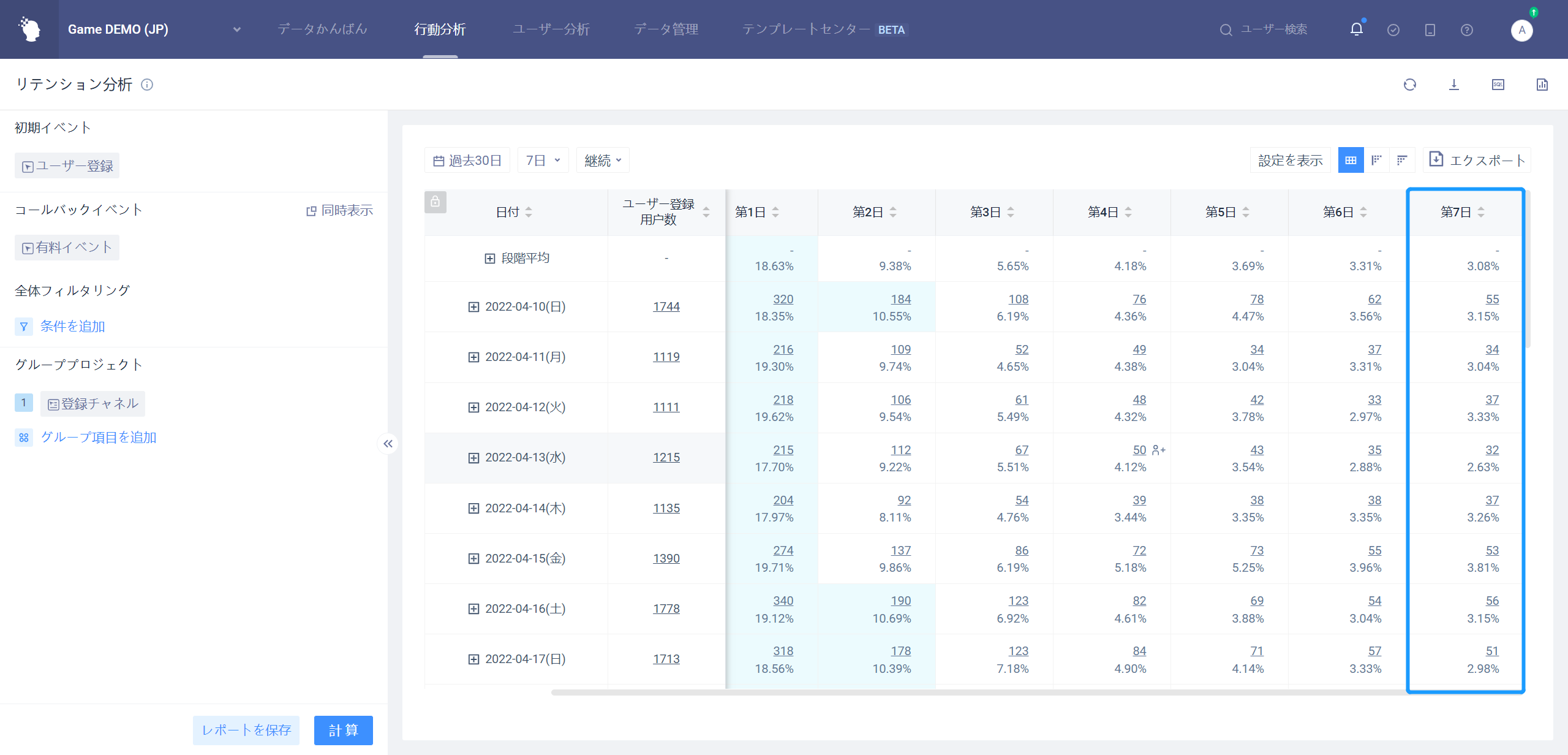
# 4.4.2.1N日目の縮図
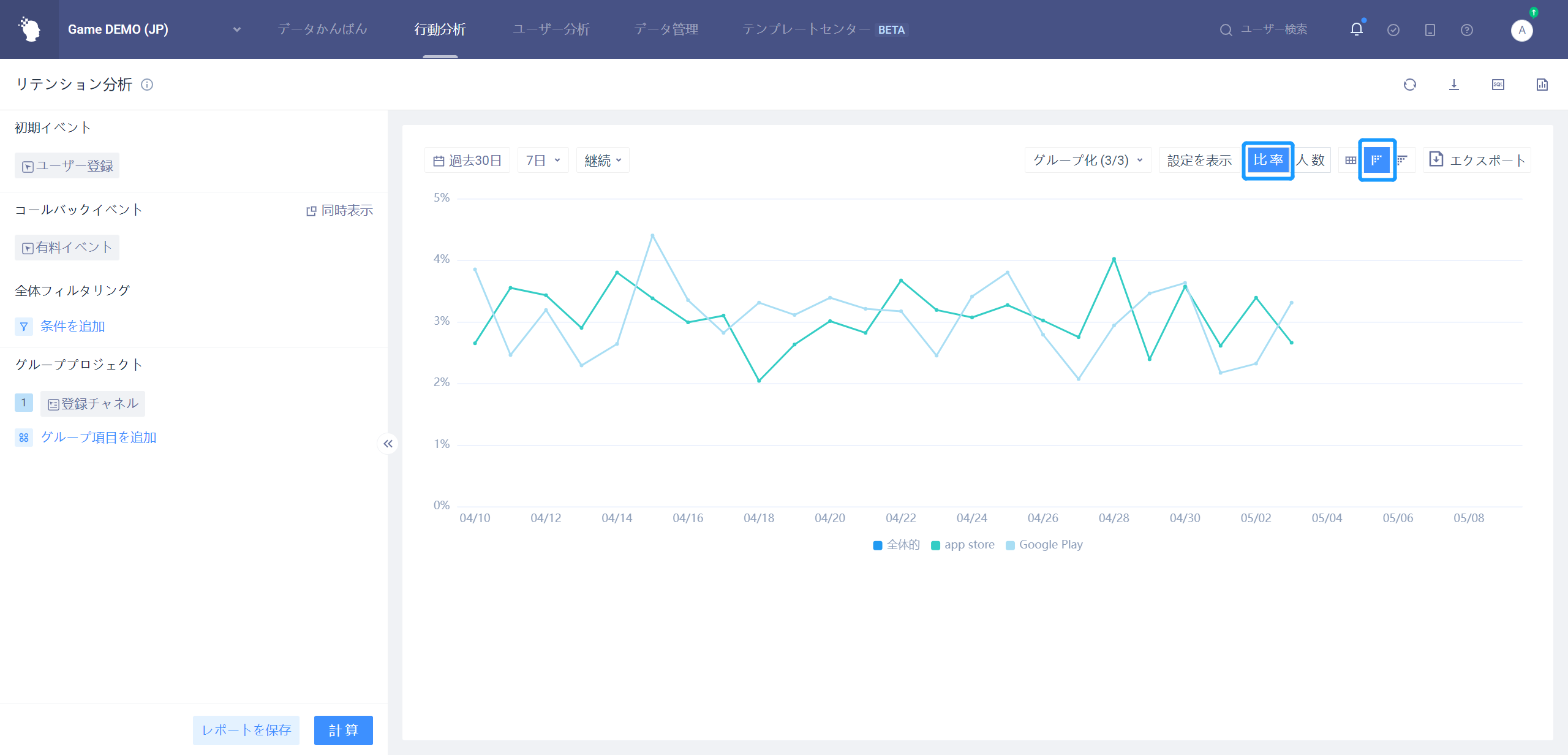
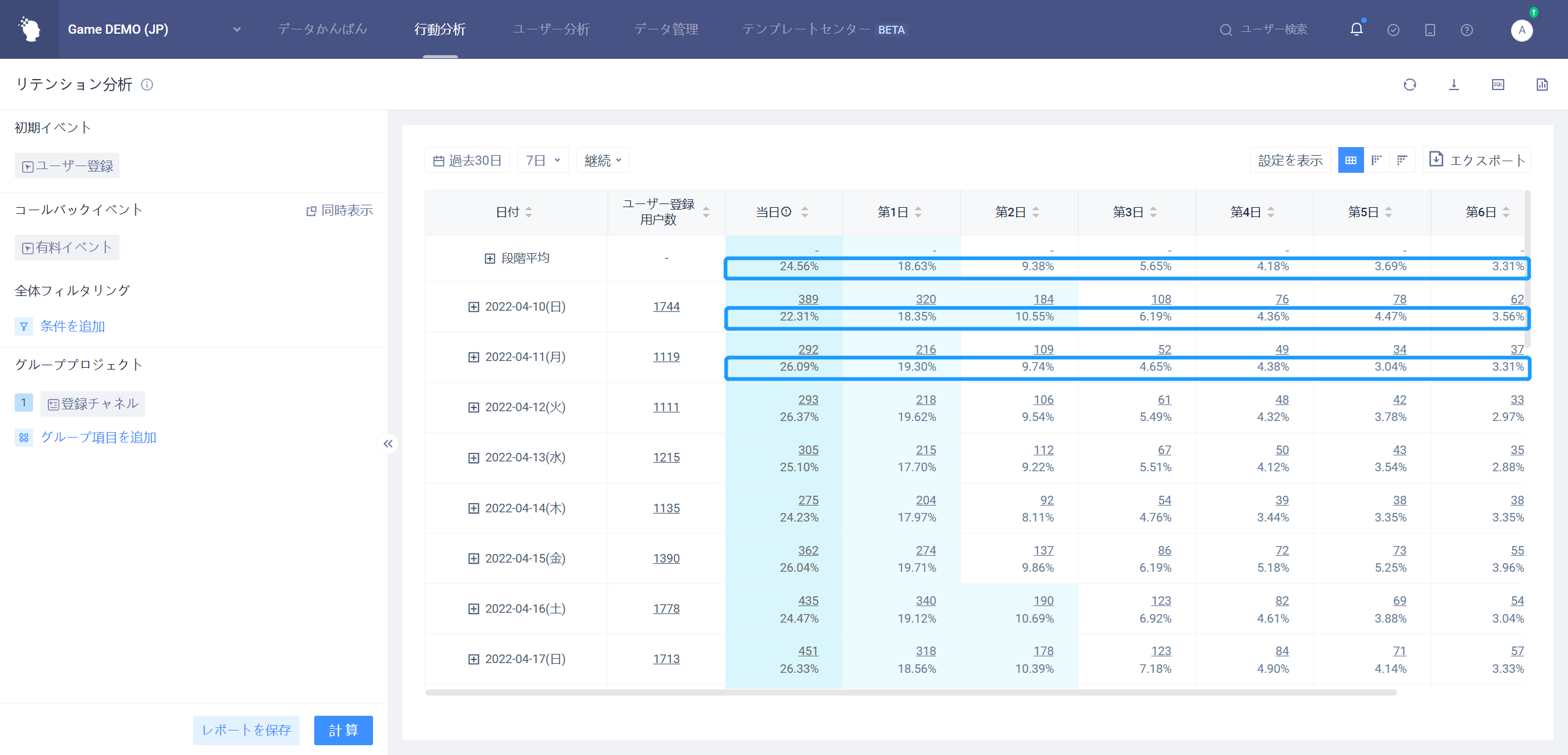
第N日のリテンションは、異なる日付または異なるグループの下での第N日のリテンション表現を分析するために使用される。
グループ項目が全体を選択する場合、全体のN日目のリテンション率傾向を分析する。
例として7日間のリテンション:
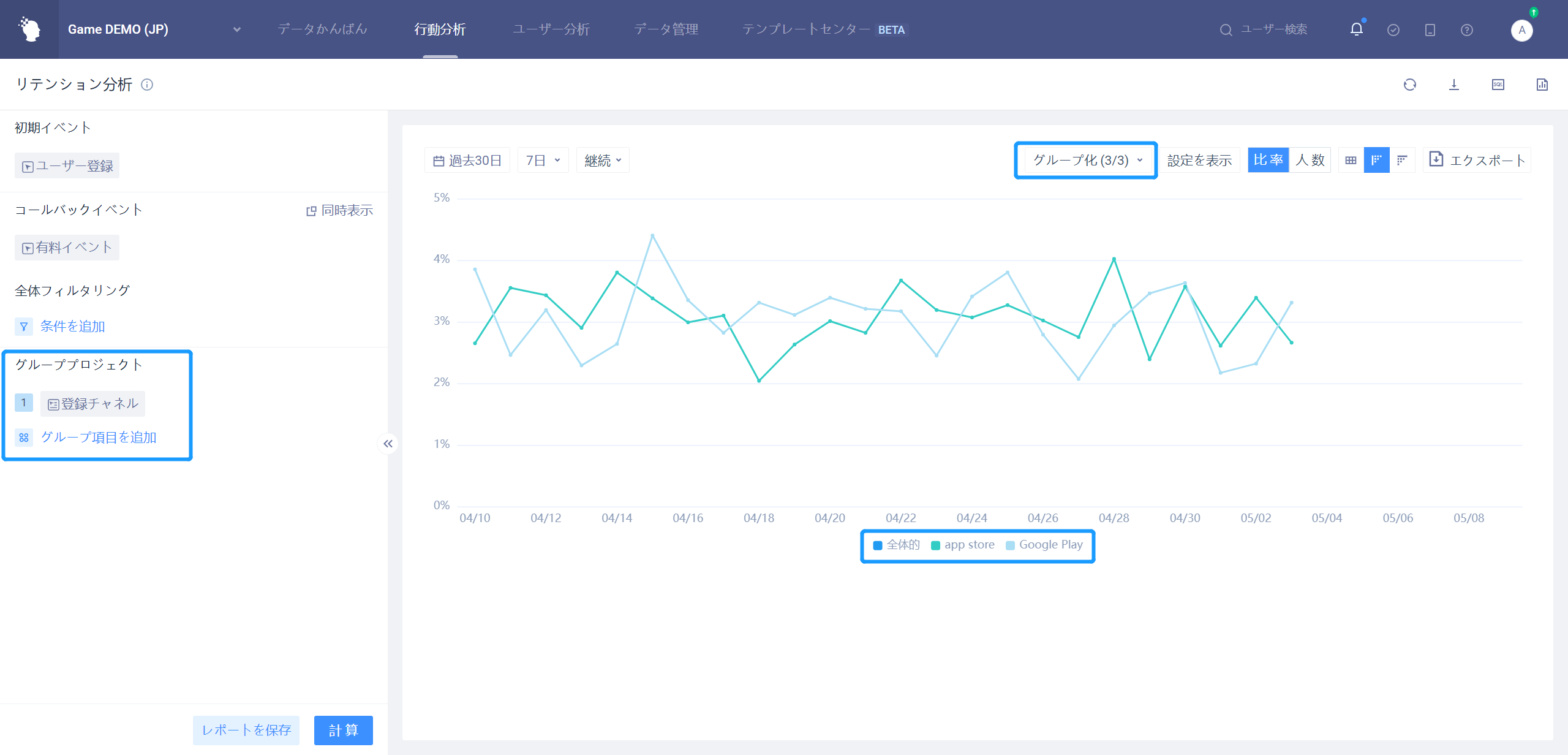
グループ項目が初期イベント属性、ユーザ属性、ユーザサブグループを選択した場合、ある属性のN日目のリテンション率傾向を分析する。
省のグループ化、7日のリテンションを例にとると
- 各グループ間のリテンション率比較を行う。
- 各グループと全体的なリテンション率を比較する。
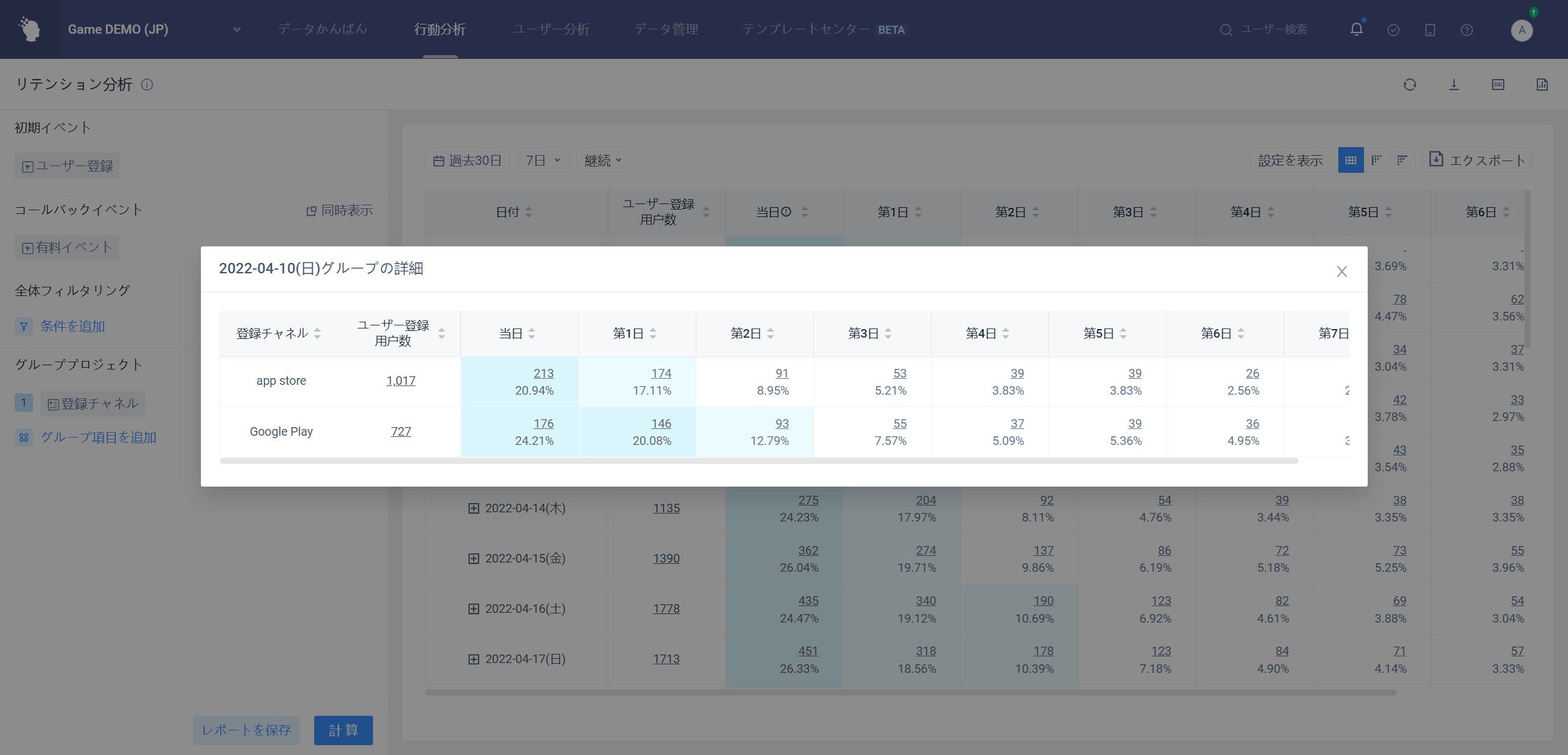
# 4.4.2.2N日目の予約人数図
グループ項目が全体を選択する場合、全体のN日目のリテンション人数傾向を分析する。
例として7日のリテンション:
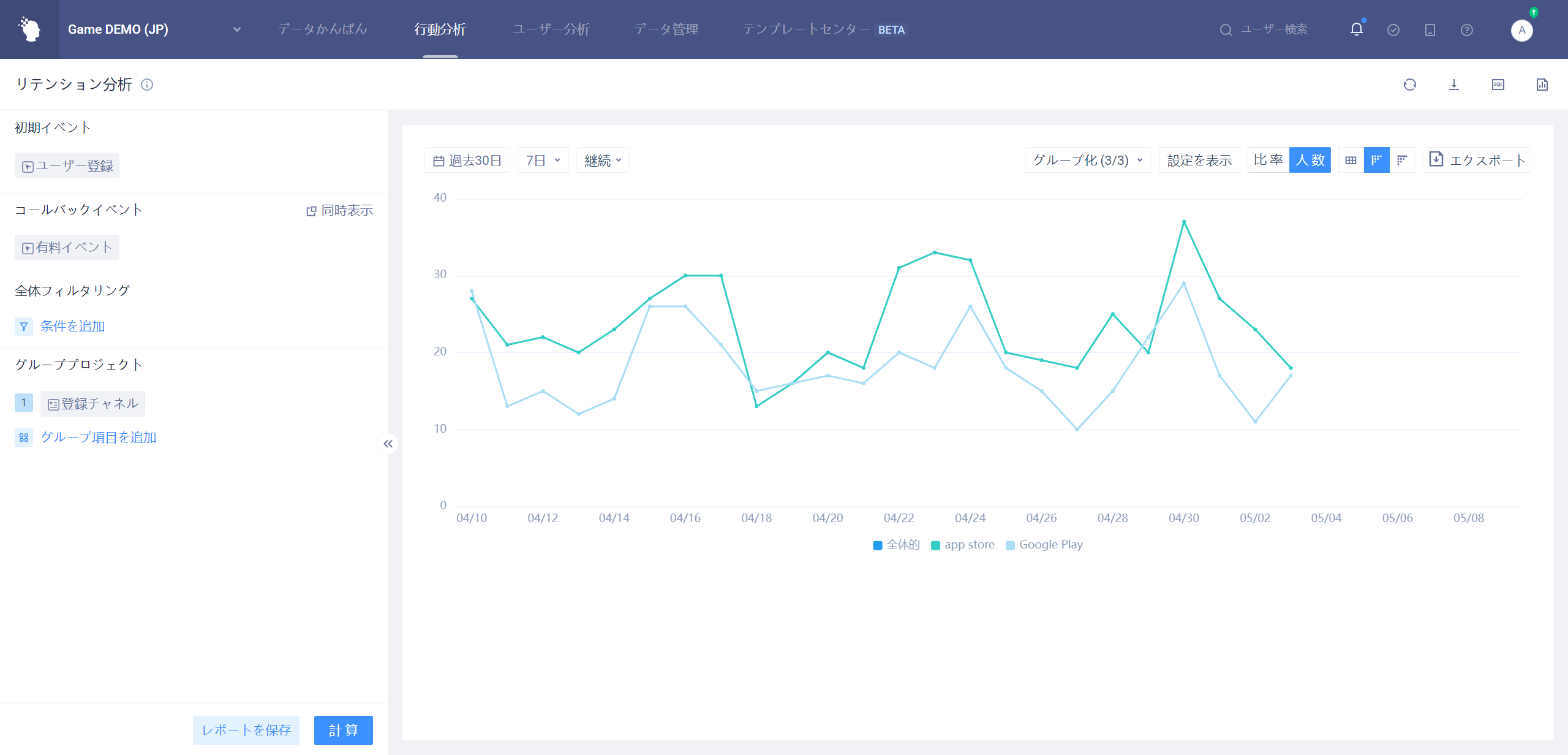
グループ項目が初期イベント属性、ユーザ属性、ユーザサブグループを選択した場合、ある属性のN日目の滞留人数傾向を分析する。
省のグループ化、7日のリテンションを例にとると
- 各グループ間の予約人数の比較を行う。
- サブグループと全体的な保持数を比較します。
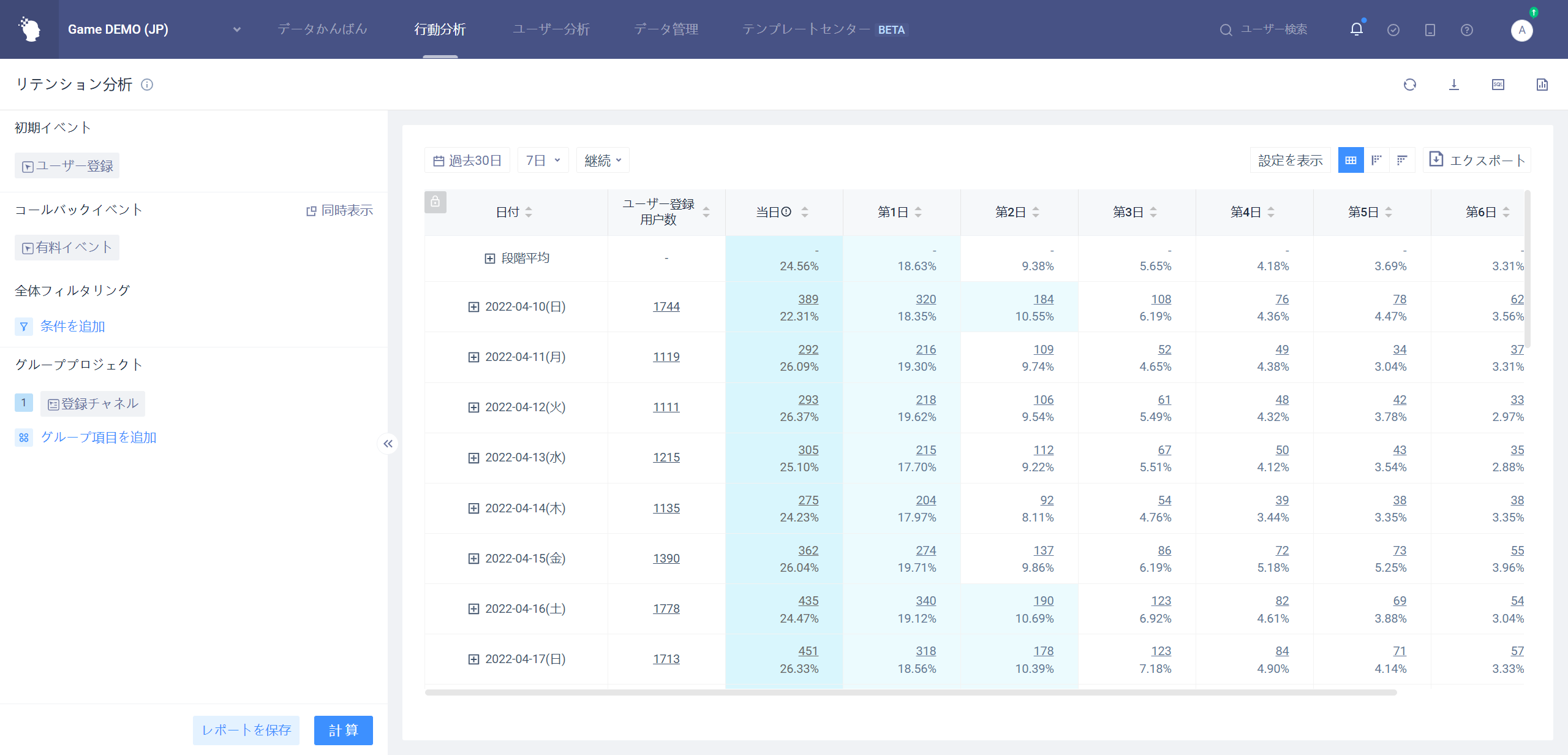
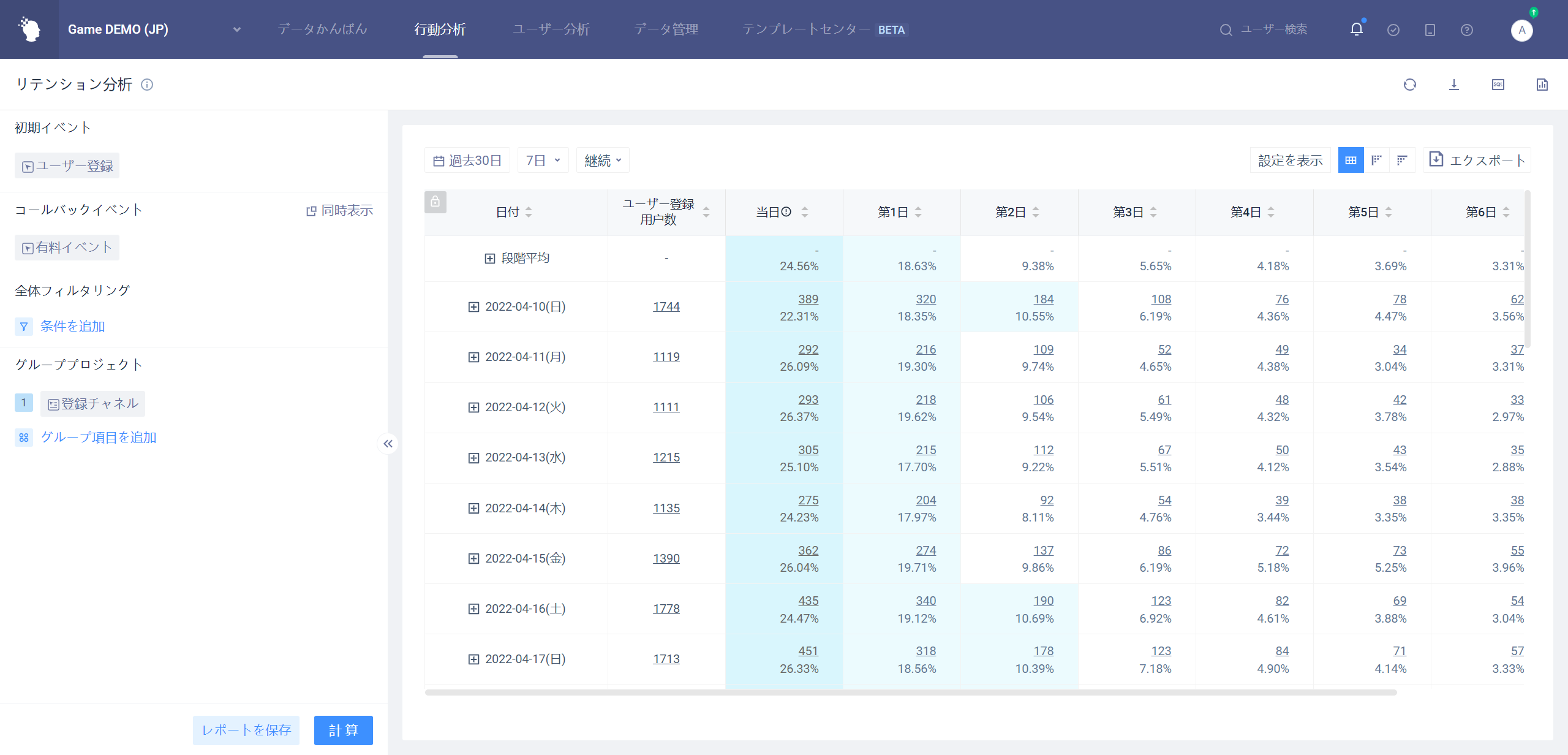
# 4.4.3グラフスタイルが毎日保存されている場合の表示
# 4.4.3.1毎日の縮図
毎日のリテンションは、異なる日付または段階の平均の変化を見るための縮図のみを提供します。
グループ項目選択全体の場合、分析の異なる日付の毎日のリテンション率を比較する。
例として7日のリテンション:
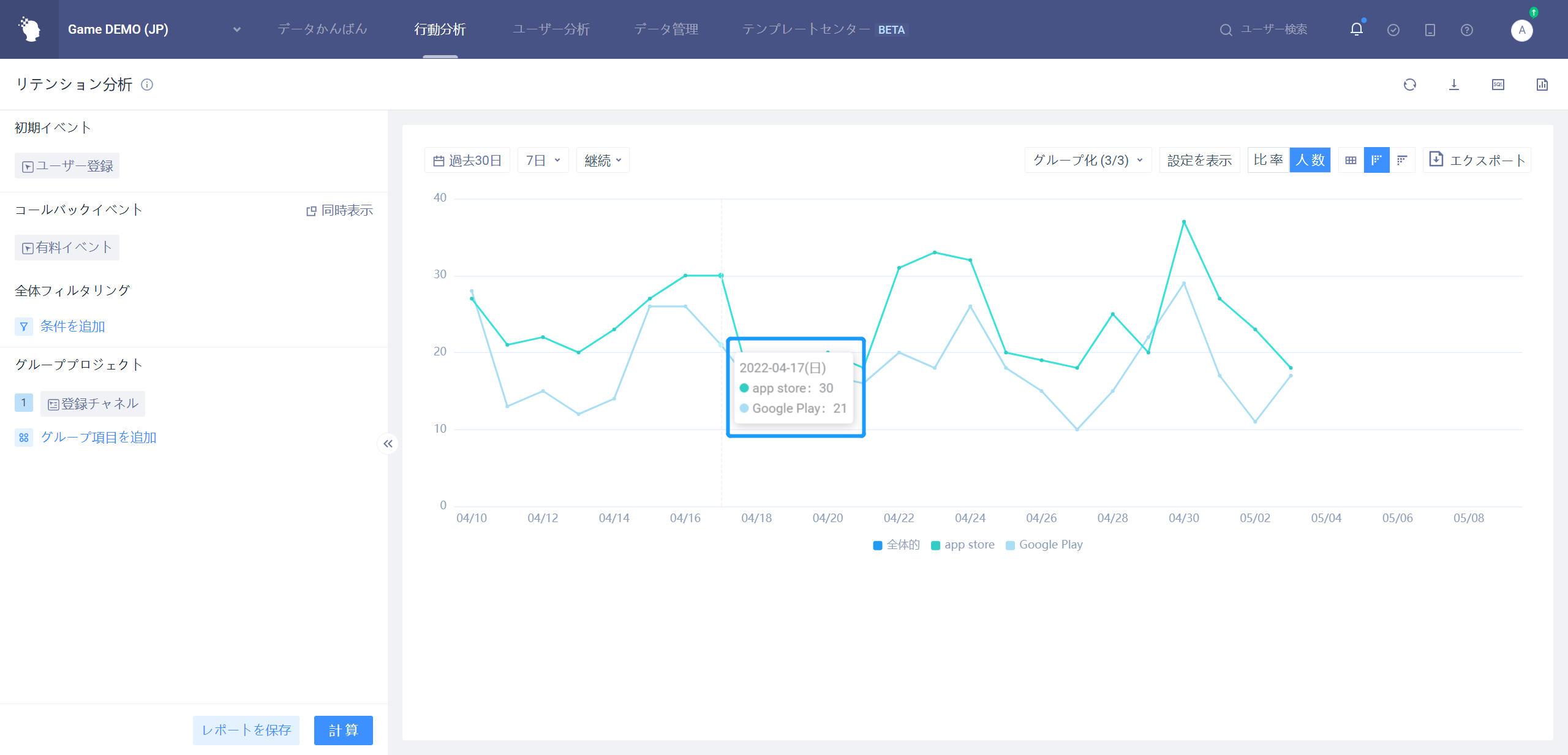
グループ項目が初期イベント属性、ユーザー属性、ユーザーグループを選択した場合、ある属性の段階平均のリテンション率比較を分析する。
省のグループ化、7日のリテンションを例にとると
- 各グループ間の保持率段階の平均比較を行う。
- 各グループは全体的なリテンション段階の平均と比較した。
# 4.4.4テキストプロンプト
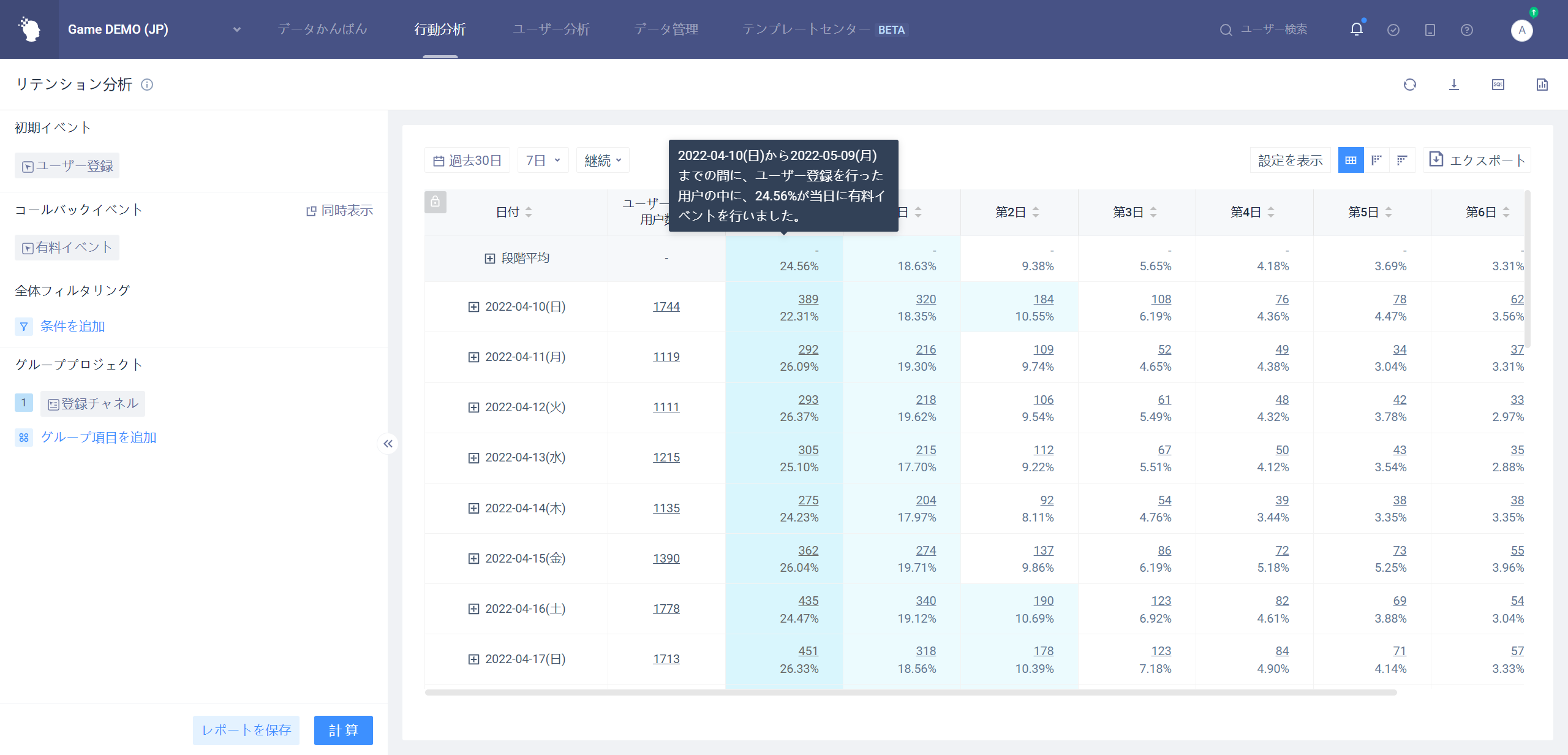
グラフボックスにマウスを移動すると、テキストヒントが表示されます。
データが不完全な場合、グラフには「*」でマーク
# 4.4.5データダウンロード
ダウンロードテーブルのスタイルは、グラフスタイルがテーブルの場合と同じで、csv形式
# V.ベストプラクティス
# 5.1ユーザーの保持状況をよりカスタマイズして理解する
リテンション分析モデルの主な役割はリテンション(または訪問)データを計算することで、リテンションの定義は完全にカスタマイズされているため、リテンションを計算する際にもっとカスタマイズされた設定を行うことができる。例えば、アプリケーション/ユーザーログインを開くことをリテンションの標識とするのではなく、製品/ゲームの中の核心的な行為をリテンションの標識とする。例えば、サインしたり、チャットをしたり、ゲームをしたり、ニュースを見たりして、製品の中で最も重要な行為をリテンションの標識とすることは、ユーザーの実際のリテンション状況、あるいは製品の粘性をよりよく反映して、ユーザーがまだ製品から価値や楽しみを得ているかどうかを知ることができる。
# 5.2計算LTVとROI
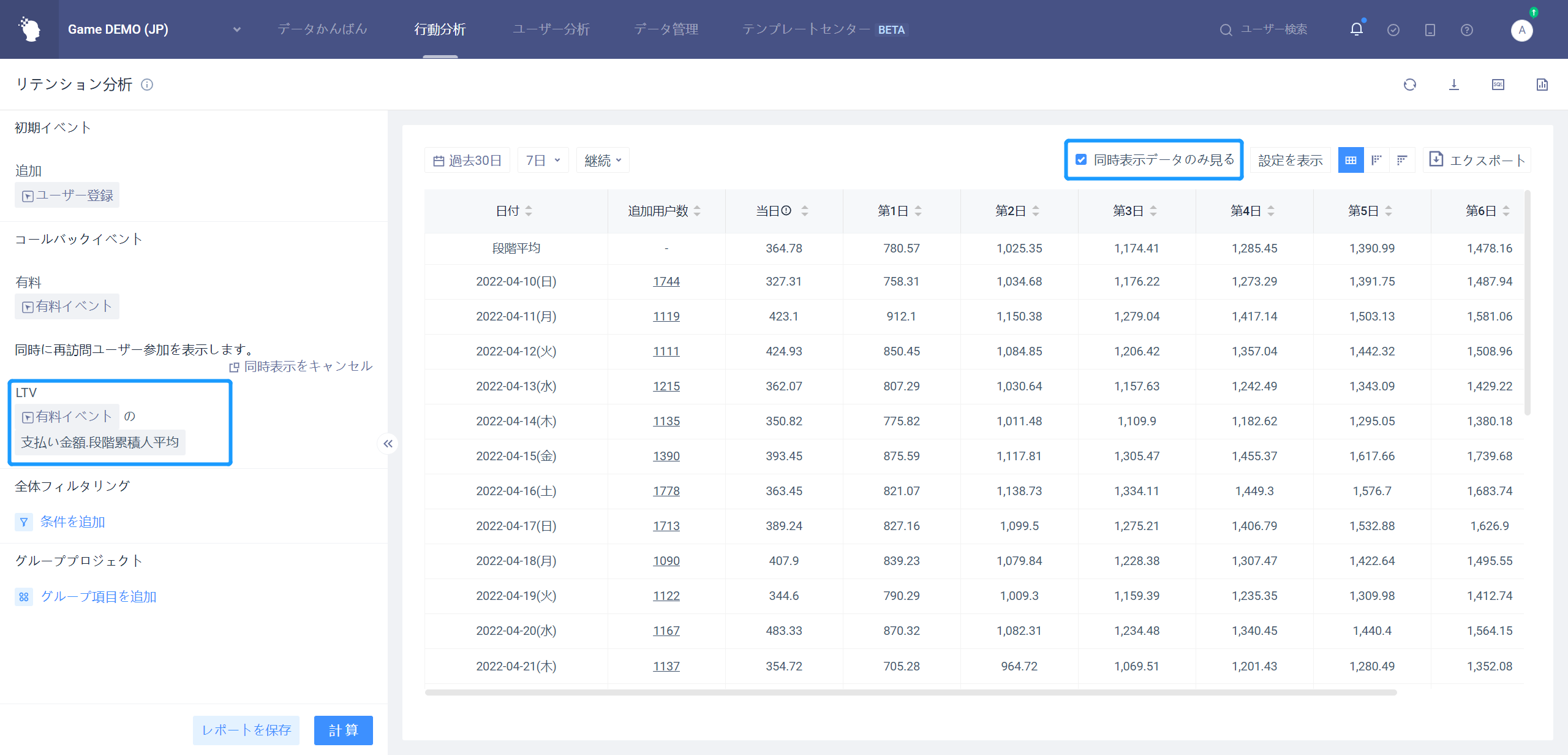
保持分析モデルのより高度な使用法は、そのアルゴリズムを使用してLTVとROIを計算することです。
LTVとは、ユーザーのライフタイム値を指し、リテンション分析モデルでは、同時表示指標に有料イベントの有料金額を設定できます段階累積人平均。この時点で計算されたのは、LTV7、LTV30などの新しいユーザーに対応するLTVです。
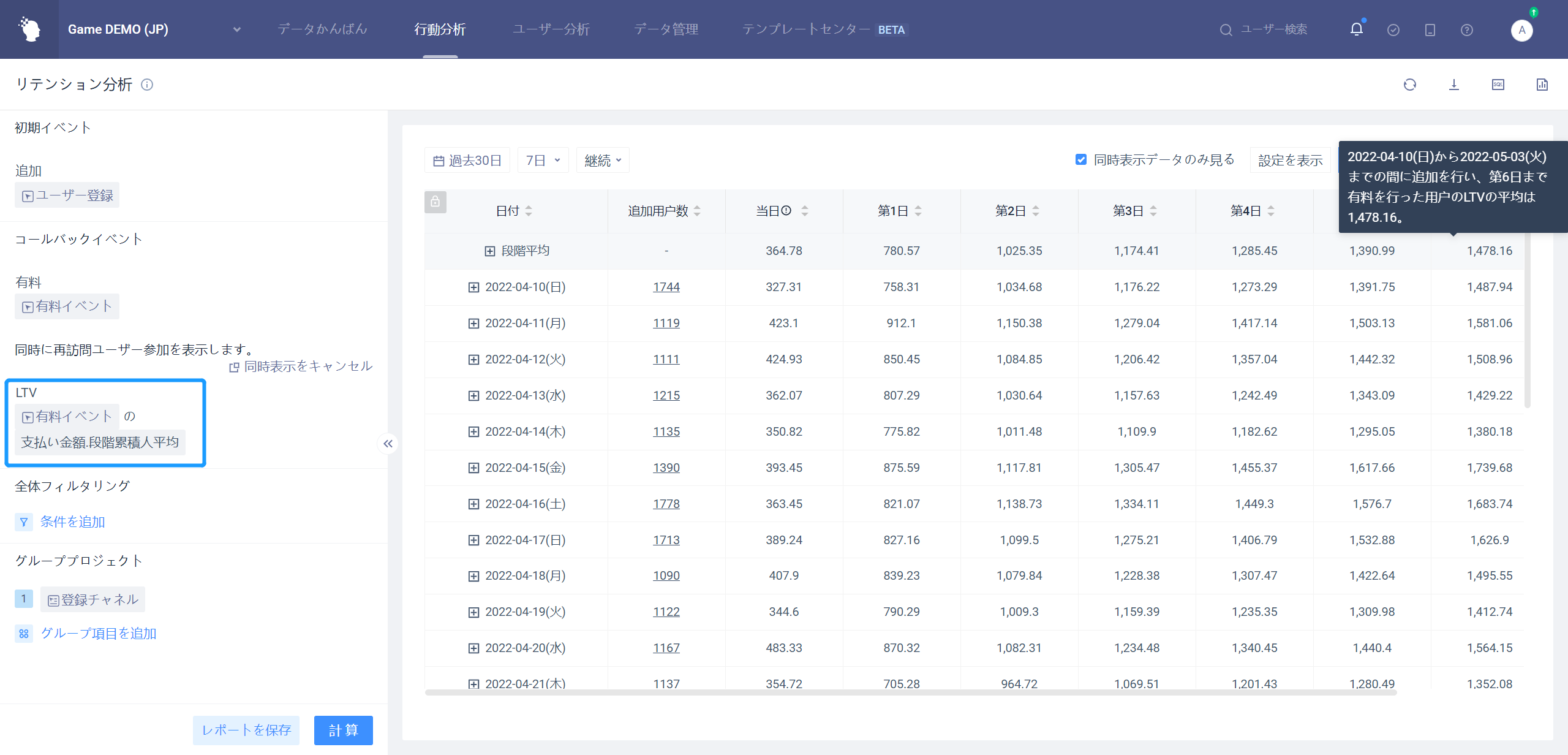
LTVに加えて、広告配信のROIも配信品質と製品収益を評価する重要な指標であり、これも残存分析モデルで計算できる。下図のように、指標式の編集状態を同時に示すことができ、初期日付指標を購入量支出に設定し、訪問ユーザー指標を有料金額段階の累積合計に設定し、指標は後者を前者で割ると計算され、この時点で計算されたのがROIで、ROIが1より大きい日付が投入コストの回収期間である。
TAは各ゲームDEMOでLTVとROIのレポートを提供しており、LTVとROIの計算方法を知りたい場合は、これらのレポートの作成方法たり、テンプレートセンターで該当するレポートテンプレート。
そのほか、リテンションモデルのアルゴリズムによって、初日に支払った人数や支払いレートなど、より多くの指標を計算することができる。