# DataX 引擎
# 一、DataX 简介
DataX 是阿里巴巴发布的开源项目(详情请访问DataX 的 Github 主页 (opens new window)),是一个高效的离线数据同步工具,常用于异构数据源之间的数据同步。
DataX 采用的是 Framework + plugin 架构,数据源读取和写入分别对应 Reader 与 Writer 插件,每一种数据源会有对应的 Reader 或者 Writer,DataX 默认地提供了丰富的 Reader 与 Writer 支持,用于适配多种主流数据源。Framework 用于连接 Reader 和 Writer,并负责同步任务中的数据处理、扭转等核心过程。
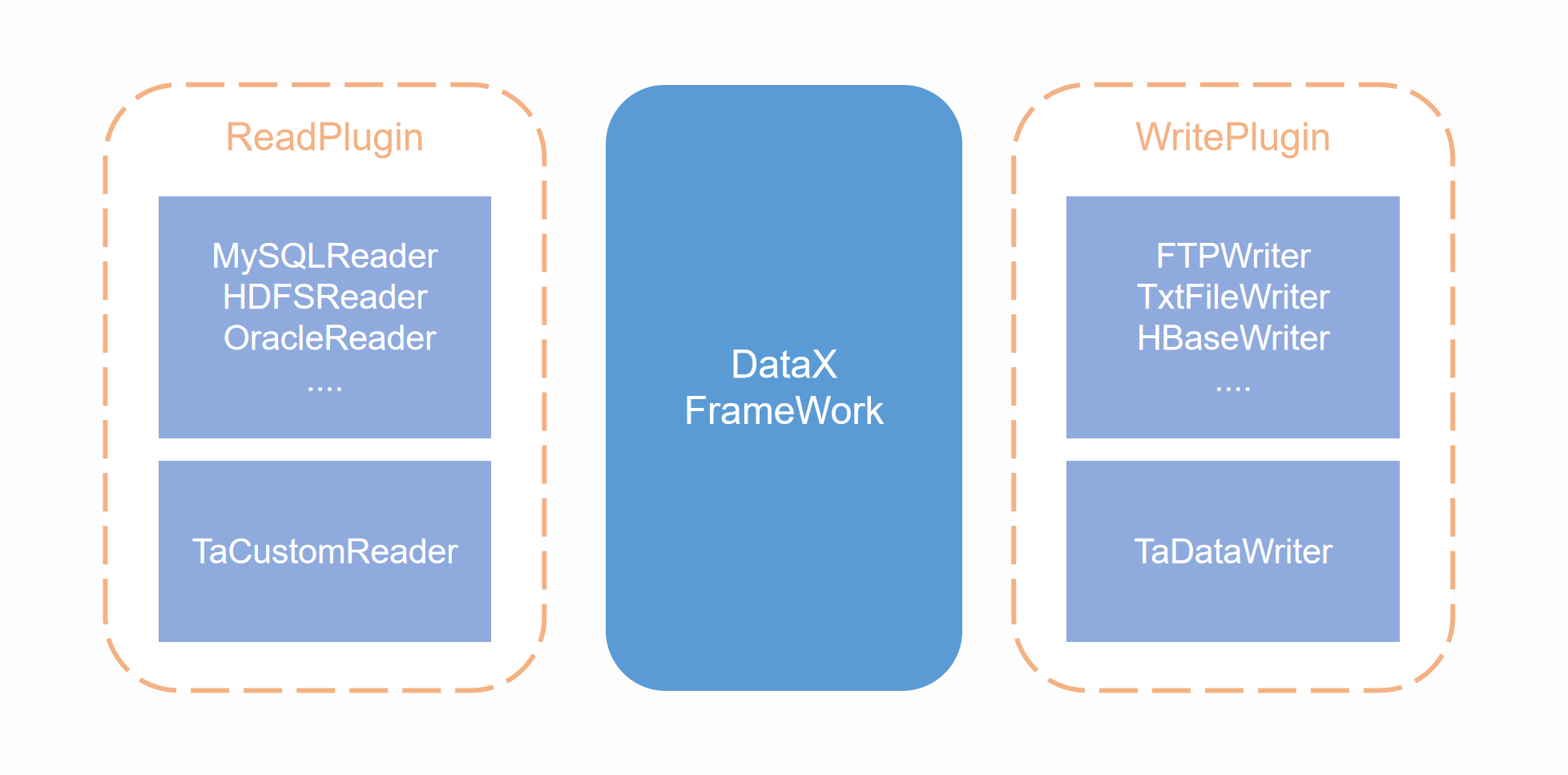
DataX 的数据同步任务,主要通过一个配置文件进行控制,其中最主要的配置是 Reader 与 Writer 的配置,这两者分别代表如何从数据源抽取数据,以及如何将抽取的数据写入数据源。通过在配置文件中使用对应数据源的 Reader 与 Writer,即可完成异构数据源的同步。
在 ta-tool 中,我们集成了 DataX 引擎,并且编写了 TA 集群的插件(即 TA 集群的 Reader 与 Writer),借由 TA 集群插件,可以将 TA 集群的作为 DataX 的数据源。
通过 ta-tool 中的 DataX 引擎,您可以完成以下数据同步:
- 将其他数据库中的数据,导入到 TA 集群,需要使用 DataX 的已有 Reader 插件与 TA Writer
- 将 TA 集群的数据,导出到其他数据库中,需要使用 TA Reader 与 DataX 的已有 Writer 插件
# 二、DataX 引擎的使用方式
如果需要使用 ta-tool 中的 DataX 引擎进行多数据源同步任务,那么首先需要在 TA 集群中编写 DataX 任务的 Config 文件,其次是执行二次开发组件中的 DataX 命令,读取 Config 文件执行数据同步任务。
# 2.1 配置文件样例
DataX 的任务 Config 文件需要是一个 json 文件,json 配置的模板如下:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
整个配置文件是一个 JSON,最外层"job"元素,其中包含两个元素,分别为"content"和"setting","content"内的元素中包含 reader 和 writer 的信息,可以在本文后续部分查看 TA 集群的 Reader 和 Writer。"setting"中的"speed"内的"channel"是同时执行的任务数。
配置文件中主要需要配置的部分为"content"中的"reader"和"writer"元素,分别配置读取数据的 Reader 插件以及写入数据的 Writer 插件。DataX 预置的 Reader 和 Writer 插件的配置方法,请访问 DataX 的Support Data Channels (opens new window)部分。
# 2.2 执行 DataX 命令
完成配置文件的编写后,可以执行以下命令读取配置文件,并开始数据同步任务。
ta-tool datax_engine -conf <configPath> [--date <date>]
传入的参数为配置文件所在路径。
# 三、TA 集群的 DataX 插件说明
# 3.1 集群内使用的插件
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| TA 系统 | TA | √ | √ | 读 、写 |
| 自定义表 | TA | √ | 写 | |
| json 文本 | TA | √ | 写 |
# 3.2 集群外使用的插件
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| TA 系统 | TA | √ | 写 |