# 데이터 액세스 준비
기본적인 지식에서는 데이터 액세스를 실시하기 전에 이해해야 할 데이터 규칙에 대해 설명합니다.
필수 정보에서는 데이터 액세스 시 준비해야 할 시스템 파라미터에 대해 설명합니다.
TE (ThinkingEngine)는 프론트엔드에서의 데이터 액세스 스키마를 제공합니다.
일반적으로, TE로의 데이터 액세스에는 다음의 세 단계가 있습니다.
- 비즈니스 요구에 기반하여 데이터 트래킹 정책을 정리합니다 (필요한 경우, 저희 분석가가 지원할 수도 있습니다).
- 엔지니어가 데이터 트래킹 정책에 기반한 구현을 진행합니다.
- 데이터 액세스의 정확성을 검증합니다.
또한, 데이터 액세스 전에, TE의 기본적인 이해가 중요합니다. 이 문서에서는 데이터 액세스에 필요한 지식에 대한 개요를 설명합니다.
이 문서의 대상자는 비즈니스 측 담당자, 엔지니어 측 담당자, 검증 테스트 담당자 등 TE를 사용할 가능성이 있는 모든 사람들입니다.
# 1. 개요
TE는 프론트엔드에서의 데이터 액세스 스키마를 제공합니다. 주요 데이터 액세스 방법은 다음과 같습니다.
- 클라이언트 SDK
- 서버와 통신하지 않고, 디바이스 정보나 유저 행동에 관한 정보를 비교적 쉽게 수집합니다.
- 서버 SDK
- 서버와 통신하며, 더 정확한 유저 행동에 관한 정보를 수집합니다.
- 데이터 수집 도구
- 더 일반적인 데이터 수집 스키마인 LogBus를 사용한 서버 SDK 등이 사용됩니다.
- 주로 히스토리 데이터를 TE 시스템으로 통합하거나 대규모 데이터 배치 작업을 처리할 때 사용됩니다.
일반적인 앱이나 웹 개발 환경에 맞춰 TE는 다음의 SDK를 제공하고 있습니다.
- React Native SDK
- Flutter SDK
- Original SDK
- Android SDK
- iOS SDK
- 서드 파티 프레임워크
- Flutter
- Reactive Native
- H5 개발
- JavaScript SDK
- H5와 네이티브 SDK 오픈 솔루션
소규모 게임 개발
- 주류 게임 엔진 지원: Cocos Creator
모바일 게임 개발
- Unity SDK
서버 레벨에서의 수집 시나리오에서는, 서버 SDK와 LogBus의 병행 사용을 권장합니다. 이 방식은 데이터 임포트의 안정성, 실시간성, 효율성 면에서 가장 우수합니다.
다른 과거 데이터를 새롭게 임포트하거나 추가할 필요가 있는 경우, DataX의 사용을 고려할 수 있습니다. 하지만, LogBus와는 달리, DataX는 상주 서비스가 아니며, 새로운 데이터의 생성을 모니터링하여 실시간으로 임포트할 수 없습니다. 따라서 데이터의 실시간성을 보장할 수 없습니다. DataX의 장점은 비교적 간단한 조작으로 다수의 데이터 소스로부터의 데이터 액세스을 지원한다는 것입니다.
또한, Filebeat와 Logstash를 사용하여 과거 데이터를 수집하고, 로그 데이터를 TE에 임포트하는 경우는, Filebeat + Logstash를 참조하세요.
데이터 수집 방법을 설계할 때는, 사업 상황에 따라 앱의 기술 아키텍처와 비즈니스 요구에 적합한 방법을 선택하는 것이 바람직합니다. 수집 방법에 대한 질문이 있으면, TE 담당자에게 문의해 주세요.
# 2. 기본 지식
# 2.1 TE 데이터 모델
데이터 액세스 전에, 먼저 TE의 데이터 테이블을 이해할 필요가 있습니다.
데이터 수집 방법의 설계는, 비즈니스 목적에 따라, 수집해야 할 유저 행동 데이터 등을 결정하는 과정입니다. 예를 들어, 유저의 결제 상태를 분석하고 싶은 경우에는, 수집해야 하는 것은 유저의 결제 행동 데이터입니다. 이러한 유저 행동은 5W1H로 분류할 수 있습니다.
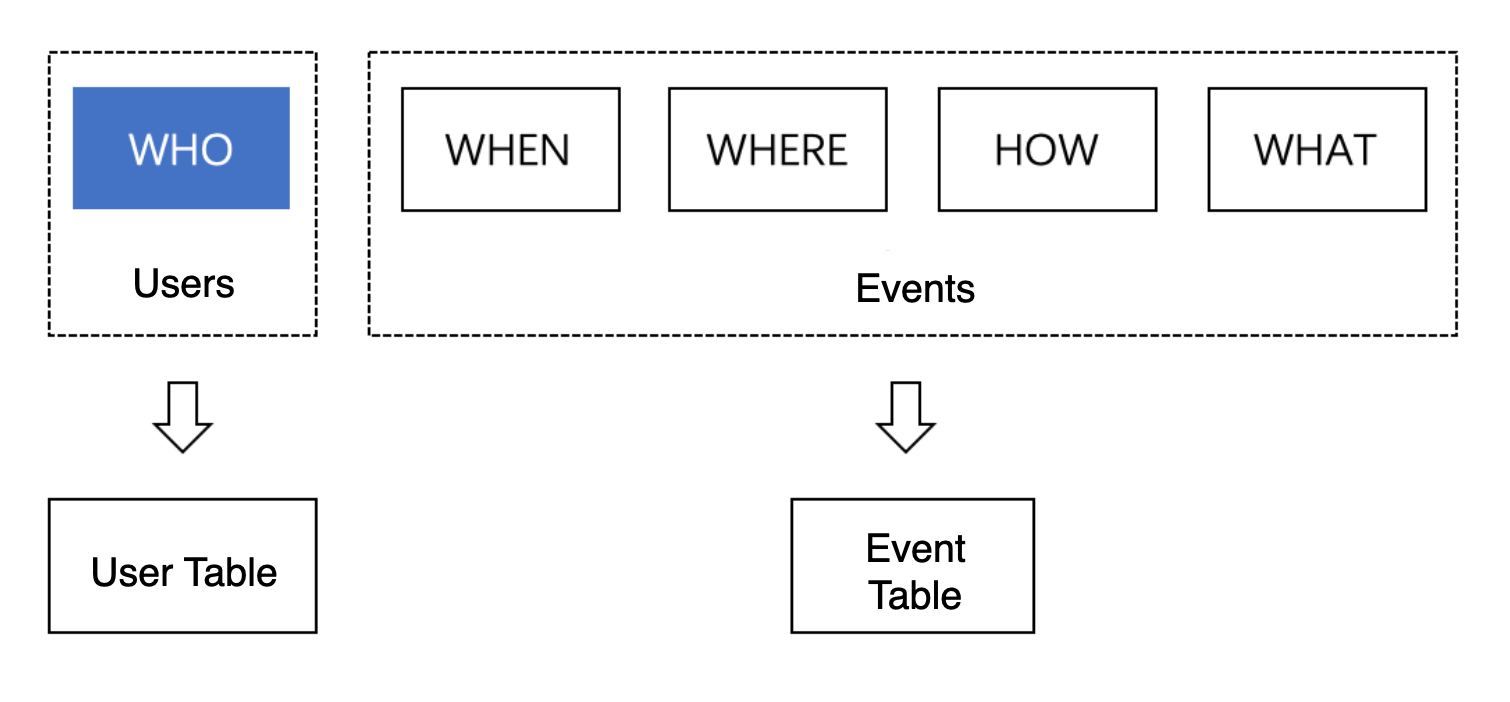
유저 행동 데이터는 TE에서 유저 데이터와 이벤트 데이터로 구성되며, 각각 User Table과 Event Table에 저장됩니다. 유저 데이터는 주로 자주 변경되지 않는 유저의 상태나 속성이 기술됩니다. 반면 이벤트 데이터는 특정한 행동 이벤트와 관련된 정보가 기술됩니다.
따라서, 데이터 수집 방법을 검토할 때는, 유저 데이터와 이벤트 데이터를 TE에 알리는 타이밍이나 트리거를 결정할 필요가 있습니다. 각각의 세부 사항은 유저 식별 규칙을 참조해 주세요.
모든 데이터 액세스 가이드에서는, 유저 데이터와 이벤트 데이터에 각각 액세스하는 방법을 설명하고 있습니다.
# 2.2 유저 식별 규칙
유저 데이터와 이벤트 데이터는, 각각이 어느 유저에게 속해 있는지를 지정할 필요가 있습니다. 계정 시스템이 없는 앱의 경우에는, 장치 관련 ID를 사용하여 유저를 식별합니다. 반면 계정 시스템이 있는 앱의 경우에는, 유저가 여러 장치에서 단일 계정을 사용하여 데이터를 생성하는 경우가 있습니다. 이러한 경우에 분석에서는, 여러 장치를 가로질러 유저 데이터를 분석하는 것이 바람직하며, 장치 관련 ID를 사용하는 것은 부적절합니다.
위의 두 가지 시나리오에 대응하기 위해, 데이터 액세스에 있어서 두 가지 유저 ID를 조합하여 유저를 식별하고 있습니다.
- 게스트 ID (#distinct_id)
- 클라이언트 측에서 랜덤한 게스트 ID를 생성하여 유저를 식별합니다.
- 계정 ID (#account_id)
- 유저가 로그인했을 때 계정 ID를 임의로 설정할 수 있습니다. 계정 ID를 사용함으로써 여러 장치의 데이터를 연결할 수 있습니다.
TE에 저장되는 데이터에는, 게스트 ID나 계정 ID 중 하나를 포함해야 합니다. 클라이언트 SDK에서는, 기본적으로 게스트 ID를 랜덤으로 생성합니다. 계정 ID를 설정하기 위해 login을 호출하고, 계정 ID가 설정되면, 모든 데이터에서 양쪽 ID가 보고됩니다. 서버 레벨에서는, 적어도 하나의 ID를 보고할 필요가 있습니다.
또한 TE에서는, 유저를 식별하는 유니크한 ID인 TE user ID (#user_id field)가 설정됩니다. 데이터가 보고되면, 유저 식별 규칙에 따라, 새로운 ID가 설정되거나, 기존의 ID가 연결됩니다.
유저 식별 규칙은 매우 중요합니다. 위에서 언급한 ID가 정확하게 설정되지 않으면, 데이터가 잘못된 유저와 연결되어 분석 효과에 영향을 줄 수 있습니다. 데이터 액세스 전에, 규칙을 잘 이해하고, 데이터 수집 시에도 유저 식별에 관한 설정을 완료해 주세요.
# 2.3 데이터 규칙
데이터 액세스 방법에 관계없이, 데이터 액세스 시에는 통일된 데이터 규칙에 의해 제한됩니다. 데이터 규칙에서는 데이터 포맷과 각각의 제한 사항에 대해 설명합니다.
SDK를 통해 데이터에 액세스하는 경우, 해당 인터페이스를 호출함으로써 SDK는 액세스에 필요한 데이터 포맷으로 데이터를 정리합니다. 데이터 임포트 도구나 Restful API를 사용하여 데이터 액세스을 하는 경우, 데이터 규칙 설명에 따라 데이터를 정리해야 합니다.
또한 데이터 포맷에 대해서는, 명명 규칙과 속성 값의 데이터 타입에 특별한 주의를 기울여야 합니다.
- 명명 규칙
- 이벤트명이나 속성명에는 문자, 숫자, '_' 만 포함할 수 있습니다. 또한 50자를 초과할 수 없습니다.
Note: 속성 이름에서는 대소문자를 구분하지 않습니다. 반면, 이벤트 이름과 속성 값에서는 대소문자를 구분합니다.
- 속성 값의 데이터 타입
데이터 타입 | 예시 | 비고 | 데이터 타입 |
|---|---|---|---|
수치 값 | 123,1.23 | 데이터 상한: -9E15에서 9E15까지 | Number |
텍스트 | "ABC", "Tokyo" | 데이터 상한: 2KB | String |
시간 | "2019-01-01 00:00:00","2019-01-01 00:00:00.000" | "yyyy-MM-dd HH:mm:ss.SSS" 또는 "yyyy-MM-dd HH:mm:ss" 날짜를 지정하려면: "yyyy-MM-dd 00:00:00" | String |
불리언 | true, false | - | Boolean |
리스트 | ["a","1","true"] | 리스트의 요소는 문자열로 식별됩니다. 최대 500개의 요소를 지원합니다. | Array(String) |
객체 | {hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False} | 객체의 키는 고유한 데이터 유형을 가집니다. 그 설명은 일반적인 속성을 참조하십시오. 객체 내의 키의 상한은 100개입니다. | Object |
객체 그룹 | [{hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False}, {hero_name: "Liu Bei", hero_level: 22, hero_equipment: ["Male and Female Double Sword", "Lu"], hero_if_support: False}] | 객체 그룹의 키는 고유한 데이터 유형을 가집니다. 그 설명은 일반적인 속성을 참조하십시오. 객체 그룹 내의 키의 상한은 500개입니다. | Array(Object) |
Note: TE에서는, 프로퍼티 값의 데이터 유형이 최초에 받은 프로퍼티 값의 데이터 유형을 따라 결정됩니다. 값의 데이터 유형이 데이터 내의 어떤 프로퍼티와 사전에 결정된 데이터 유형과 일치하지 않는 경우, 해당 프로퍼티를 폐기해야 합니다.
TE에는 #으로 시작하는 프로퍼티 이름이 있으며, 이러한 프로퍼티는 프리셋 프로퍼티로서, 특별한 설정이 필요 없으며 SDK에서 기본적으로 수집됩니다. 자세한 내용은 Preset attributes and system fields를 참조하십시오.
데이터 포맷이나 데이터 유형이 정확하게 설정되지 않은 경우 데이터가 저장되지 않을 수 있으므로, 데이터 액세스 시 및 데이터 검증 시 Data Reporting Management module을 사용하여 데이터의 정확성을 확인 및 관리해야 합니다.
# 3. 필수 정보
엔지니어가 공식적으로 데이터 액세스을 수행하기 전에, 아래의 정보가 준비되어 있는지 확인해야 합니다.
- Project APP ID
- TE에서 프로젝트를 생성하면, 프로젝트마다 APP ID가 생성됩니다. 프로젝트 관리 화면에서 확인할 수 있습니다.
- 데이터 수신단의 주소
- SaaS 버전을 사용하는 경우는 [https://ta-receiver.thinkingdata.io]입니다.
- 프라이빗 구축인 경우, 프라이빗 클러스터(또는 액세스 포인트)에 도메인 이름을 연결하고 SSL 인증서를 발급해야 합니다.
- 데이터 수신 끝 주소 확인 방법
- 아래 URL에 접속하여 OK가 표시되는지 확인하십시오.
- https://YOUR_RECEIVER_URL/health-check
- 아래 URL에 접속하여 OK가 표시되는지 확인하십시오.
- 데이터 수집의 정리
- 데이터 수집 방법
- 클라이언트 SDK, 서버 SDK, 데이터 임포트 도구, 또는 여러 방법의 조합을 명확히 하십시오.
- 데이터 액세스할 데이터의 내용과 트리거 타이밍
- 데이터 수집 방법
데이터 액세스 전에 이해해야 할 문서의 읽기가 완료되었습니다. 이제 선택한 데이터 수집 방법을 바탕으로, 해당 액세스 가이드를 참조하면서 데이터 액세스을 시작하십시오.